 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising bivariate signals via smoothing and polarization priors
Feb 28, 2025We propose two formulations to leverage the geometric properties of bivariate signals for dealing with the denoising problem. In doing so, we use the instantaneous Stokes parameters to incorporate the polarization state of the signal. While the first formulation exploits the statistics of the Stokes representation in a Bayesian setting, the second uses a kernel regression formulation to impose locally smooth time-varying polarization properties. In turn, we obtain two formulations that allow us to use both signal and polarization domain regularization for denoising a bivariate signal. The solutions to them exploit the polarization information efficiently as demonstrated in the numerical simulations
Process-constrained batch Bayesian approaches for yield optimization in multi-reactor systems
Aug 05, 2024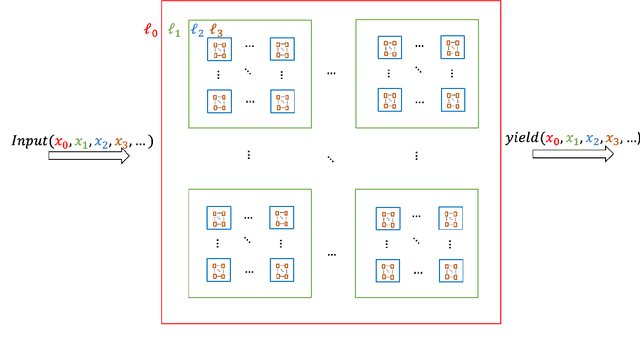
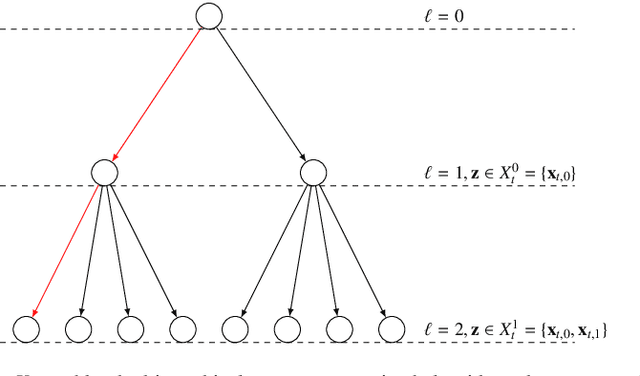
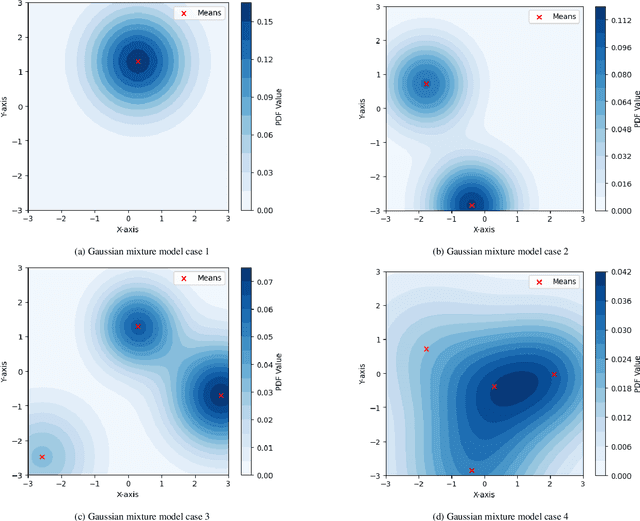
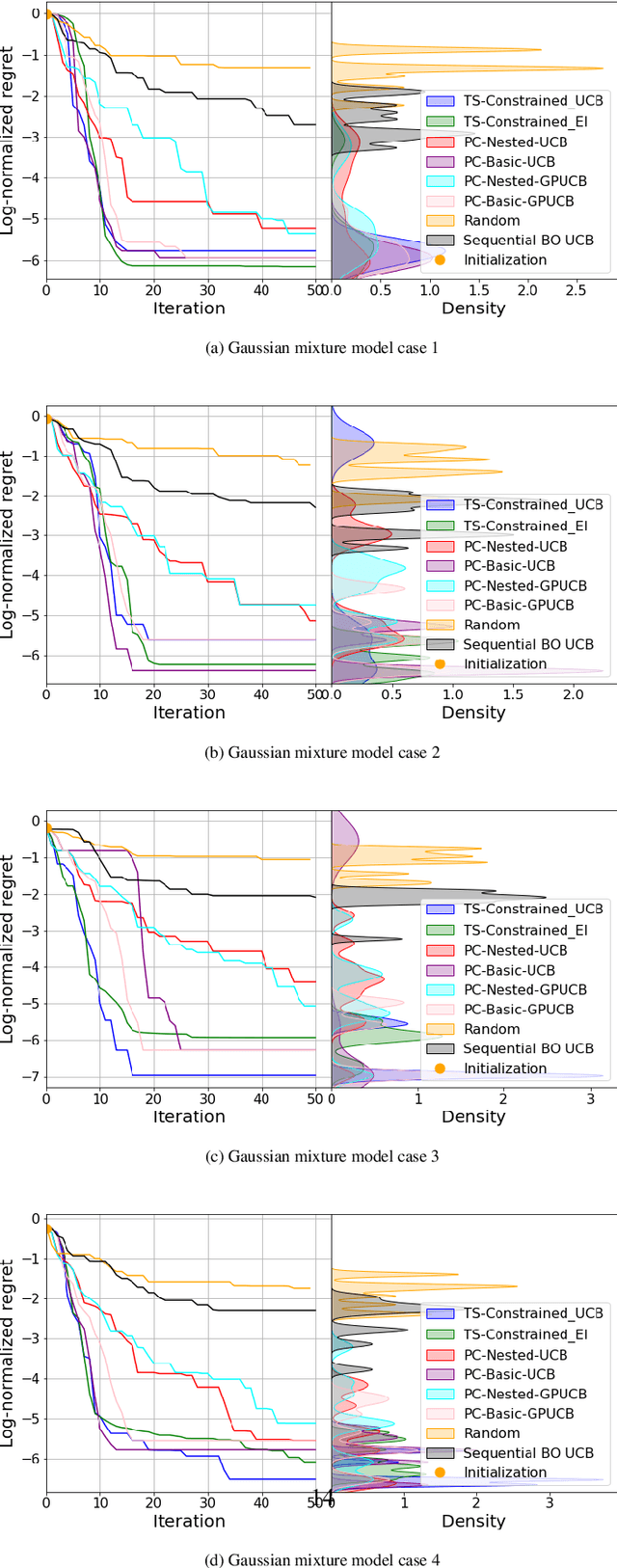
The optimization of yields in multi-reactor systems, which are advanced tools in heterogeneous catalysis research, presents a significant challenge due to hierarchical technical constraints. To this respect, this work introduces a novel approach called process-constrained batch Bayesian optimization via Thompson sampling (pc-BO-TS) and its generalized hierarchical extension (hpc-BO-TS). This method, tailored for the efficiency demands in multi-reactor systems, integrates experimental constraints and balances between exploration and exploitation in a sequential batch optimization strategy. It offers an improvement over other Bayesian optimization methods. The performance of pc-BO-TS and hpc-BO-TS is validated in synthetic cases as well as in a realistic scenario based on data obtained from high-throughput experiments done on a multi-reactor system available in the REALCAT platform. The proposed methods often outperform other sequential Bayesian optimizations and existing process-constrained batch Bayesian optimization methods. This work proposes a novel approach to optimize the yield of a reaction in a multi-reactor system, marking a significant step forward in digital catalysis and generally in optimization methods for chemical engineering.
Benchmarking multi-component signal processing methods in the time-frequency plane
Feb 13, 2024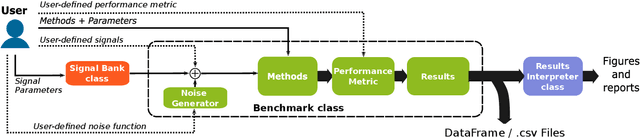

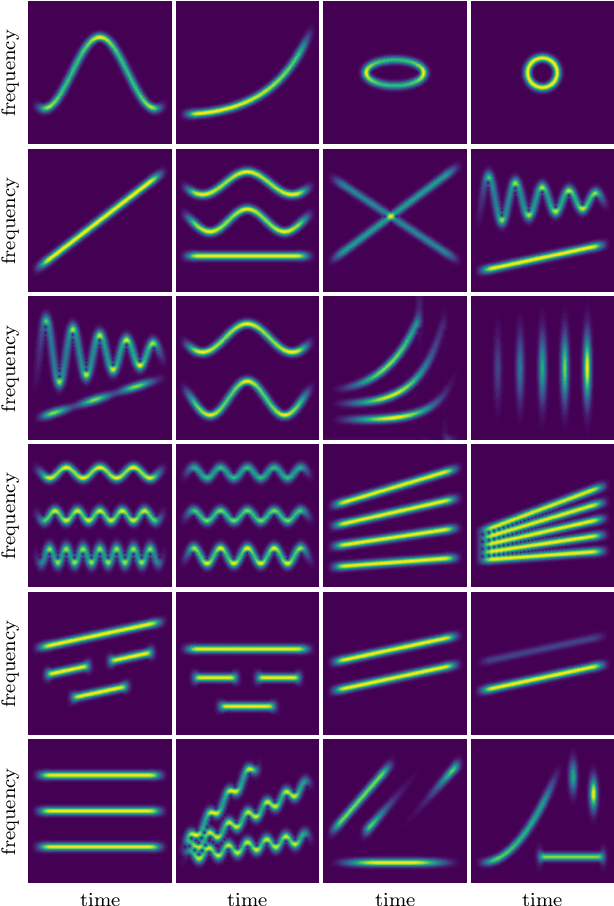

Signal processing in the time-frequency plane has a long history and remains a field of methodological innovation. For instance, detection and denoising based on the zeros of the spectrogram have been proposed since 2015, contrasting with a long history of focusing on larger values of the spectrogram. Yet, unlike neighboring fields like optimization and machine learning, time-frequency signal processing lacks widely-adopted benchmarking tools. In this work, we contribute an open-source, Python-based toolbox termed MCSM-Benchs for benchmarking multi-component signal analysis methods, and we demonstrate our toolbox on three time-frequency benchmarks. First, we compare different methods for signal detection based on the zeros of the spectrogram, including unexplored variations of previously proposed detection tests. Second, we compare zero-based denoising methods to both classical and novel methods based on large values and ridges of the spectrogram. Finally, we compare the denoising performance of these methods against typical spectrogram thresholding strategies, in terms of post-processing artifacts commonly referred to as musical noise. At a low level, the obtained results provide new insight on the assessed approaches, and in particular research directions to further develop zero-based methods. At a higher level, our benchmarks exemplify the benefits of using a public, collaborative, common framework for benchmarking.
Signal reconstruction using determinantal sampling
Oct 13, 2023We study the approximation of a square-integrable function from a finite number of evaluations on a random set of nodes according to a well-chosen distribution. This is particularly relevant when the function is assumed to belong to a reproducing kernel Hilbert space (RKHS). This work proposes to combine several natural finite-dimensional approximations based two possible probability distributions of nodes. These distributions are related to determinantal point processes, and use the kernel of the RKHS to favor RKHS-adapted regularity in the random design. While previous work on determinantal sampling relied on the RKHS norm, we prove mean-square guarantees in $L^2$ norm. We show that determinantal point processes and mixtures thereof can yield fast convergence rates. Our results also shed light on how the rate changes as more smoothness is assumed, a phenomenon known as superconvergence. Besides, determinantal sampling generalizes i.i.d. sampling from the Christoffel function which is standard in the literature. More importantly, determinantal sampling guarantees the so-called instance optimality property for a smaller number of function evaluations than i.i.d. sampling.
Normalizing flow sampling with Langevin dynamics in the latent space
May 20, 2023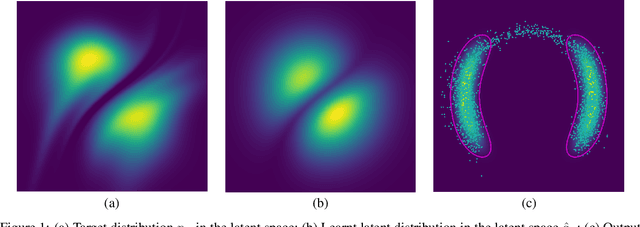



Normalizing flows (NF) use a continuous generator to map a simple latent (e.g. Gaussian) distribution, towards an empirical target distribution associated with a training data set. Once trained by minimizing a variational objective, the learnt map provides an approximate generative model of the target distribution. Since standard NF implement differentiable maps, they may suffer from pathological behaviors when targeting complex distributions. For instance, such problems may appear for distributions on multi-component topologies or characterized by multiple modes with high probability regions separated by very unlikely areas. A typical symptom is the explosion of the Jacobian norm of the transformation in very low probability areas. This paper proposes to overcome this issue thanks to a new Markov chain Monte Carlo algorithm to sample from the target distribution in the latent domain before transporting it back to the target domain. The approach relies on a Metropolis adjusted Langevin algorithm (MALA) whose dynamics explicitly exploits the Jacobian of the transformation. Contrary to alternative approaches, the proposed strategy preserves the tractability of the likelihood and it does not require a specific training. Notably, it can be straightforwardly used with any pre-trained NF network, regardless of the architecture. Experiments conducted on synthetic and high-dimensional real data sets illustrate the efficiency of the method.
Plug-and-Play split Gibbs sampler: embedding deep generative priors in Bayesian inference
Apr 21, 2023This paper introduces a stochastic plug-and-play (PnP) sampling algorithm that leverages variable splitting to efficiently sample from a posterior distribution. The algorithm based on split Gibbs sampling (SGS) draws inspiration from the alternating direction method of multipliers (ADMM). It divides the challenging task of posterior sampling into two simpler sampling problems. The first problem depends on the likelihood function, while the second is interpreted as a Bayesian denoising problem that can be readily carried out by a deep generative model. Specifically, for an illustrative purpose, the proposed method is implemented in this paper using state-of-the-art diffusion-based generative models. Akin to its deterministic PnP-based counterparts, the proposed method exhibits the great advantage of not requiring an explicit choice of the prior distribution, which is rather encoded into a pre-trained generative model. However, unlike optimization methods (e.g., PnP-ADMM) which generally provide only point estimates, the proposed approach allows conventional Bayesian estimators to be accompanied by confidence intervals at a reasonable additional computational cost. Experiments on commonly studied image processing problems illustrate the efficiency of the proposed sampling strategy. Its performance is compared to recent state-of-the-art optimization and sampling methods.
A distributed Gibbs Sampler with Hypergraph Structure for High-Dimensional Inverse Problems
Oct 05, 2022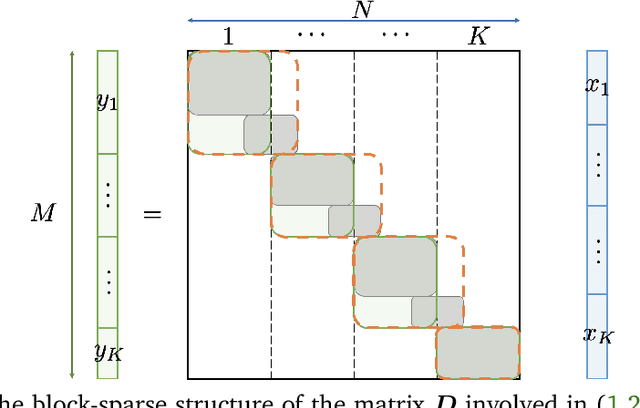
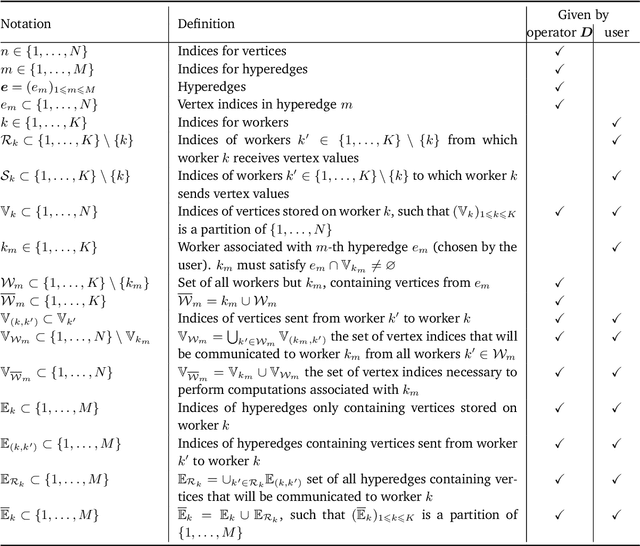
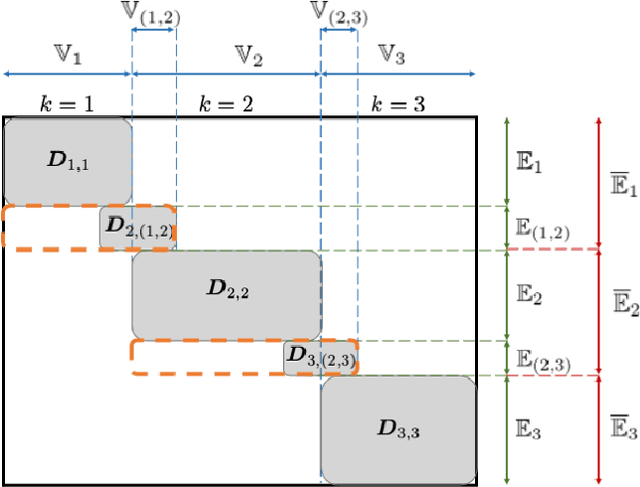

Sampling-based algorithms are classical approaches to perform Bayesian inference in inverse problems. They provide estimators with the associated credibility intervals to quantify the uncertainty on the estimators. Although these methods hardly scale to high dimensional problems, they have recently been paired with optimization techniques, such as proximal and splitting approaches, to address this issue. Such approaches pave the way to distributed samplers, splitting computations to make inference more scalable and faster. We introduce a distributed Gibbs sampler to efficiently solve such problems, considering posterior distributions with multiple smooth and non-smooth functions composed with linear operators. The proposed approach leverages a recent approximate augmentation technique reminiscent of primal-dual optimization methods. It is further combined with a block-coordinate approach to split the primal and dual variables into blocks, leading to a distributed block-coordinate Gibbs sampler. The resulting algorithm exploits the hypergraph structure of the involved linear operators to efficiently distribute the variables over multiple workers under controlled communication costs. It accommodates several distributed architectures, such as the Single Program Multiple Data and client-server architectures. Experiments on a large image deblurring problem show the performance of the proposed approach to produce high quality estimates with credibility intervals in a small amount of time.
Sliced-Wasserstein normalizing flows: beyond maximum likelihood training
Jul 12, 2022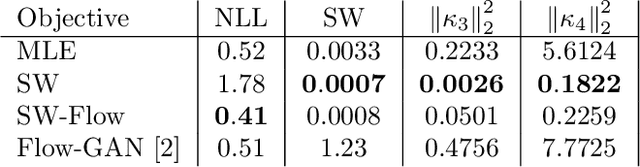
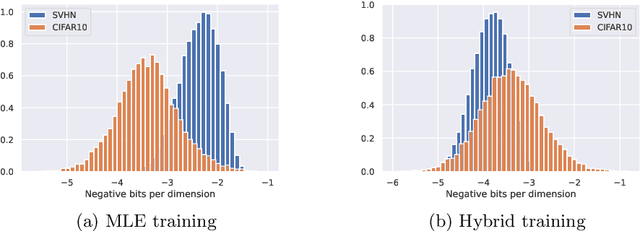

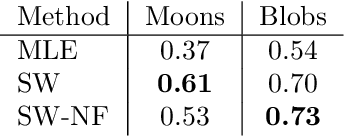
Despite their advantages, normalizing flows generally suffer from several shortcomings including their tendency to generate unrealistic data (e.g., images) and their failing to detect out-of-distribution data. One reason for these deficiencies lies in the training strategy which traditionally exploits a maximum likelihood principle only. This paper proposes a new training paradigm based on a hybrid objective function combining the maximum likelihood principle (MLE) and a sliced-Wasserstein distance. Results obtained on synthetic toy examples and real image data sets show better generative abilities in terms of both likelihood and visual aspects of the generated samples. Reciprocally, the proposed approach leads to a lower likelihood of out-of-distribution data, demonstrating a greater data fidelity of the resulting flows.
Learning Optimal Transport Between two Empirical Distributions with Normalizing Flows
Jul 05, 2022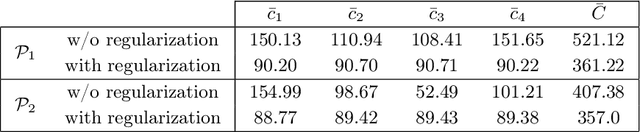
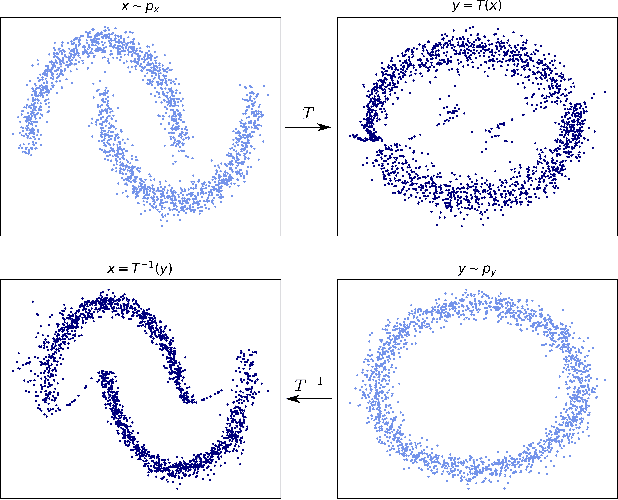
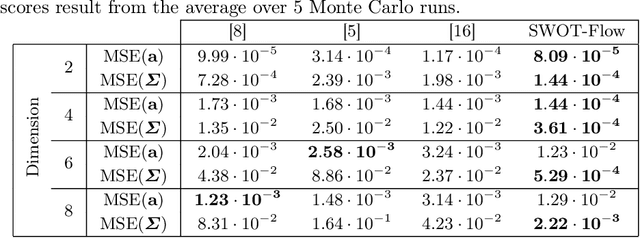

Optimal transport (OT) provides effective tools for comparing and mapping probability measures. We propose to leverage the flexibility of neural networks to learn an approximate optimal transport map. More precisely, we present a new and original method to address the problem of transporting a finite set of samples associated with a first underlying unknown distribution towards another finite set of samples drawn from another unknown distribution. We show that a particular instance of invertible neural networks, namely the normalizing flows, can be used to approximate the solution of this OT problem between a pair of empirical distributions. To this aim, we propose to relax the Monge formulation of OT by replacing the equality constraint on the push-forward measure by the minimization of the corresponding Wasserstein distance. The push-forward operator to be retrieved is then restricted to be a normalizing flow which is trained by optimizing the resulting cost function. This approach allows the transport map to be discretized as a composition of functions. Each of these functions is associated to one sub-flow of the network, whose output provides intermediate steps of the transport between the original and target measures. This discretization yields also a set of intermediate barycenters between the two measures of interest. Experiments conducted on toy examples as well as a challenging task of unsupervised translation demonstrate the interest of the proposed method. Finally, some experiments show that the proposed approach leads to a good approximation of the true OT.
Kernel interpolation with continuous volume sampling
Feb 22, 2020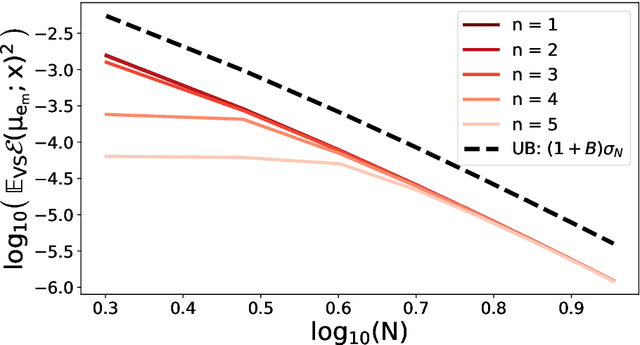
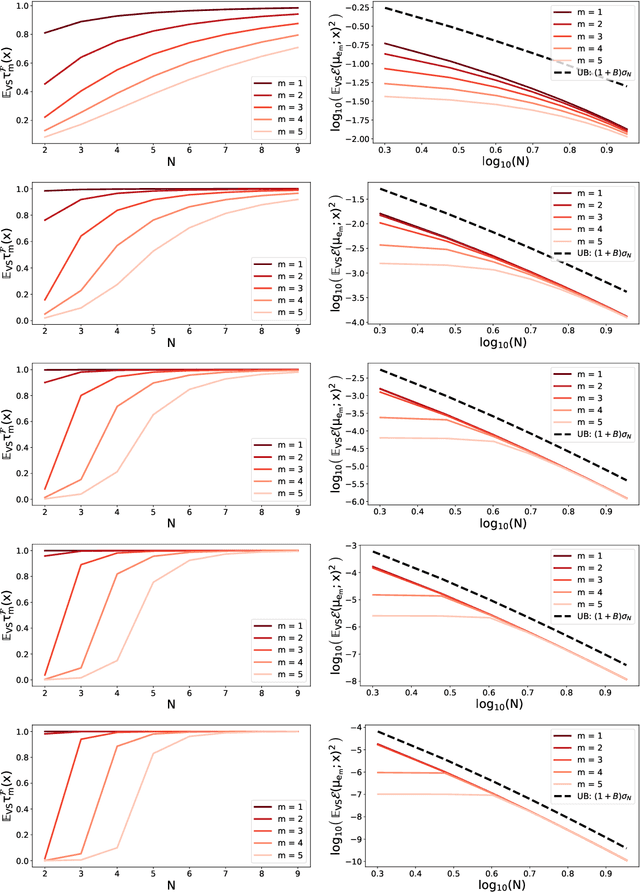
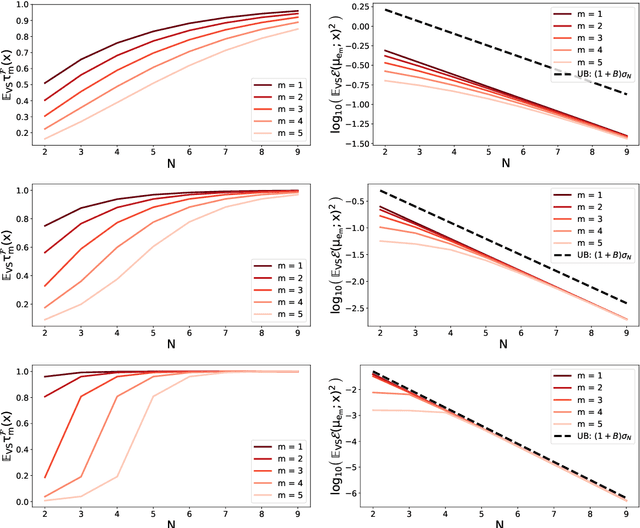
A fundamental task in kernel methods is to pick nodes and weights, so as to approximate a given function from an RKHS by the weighted sum of kernel translates located at the nodes. This is the crux of kernel density estimation, kernel quadrature, or interpolation from discrete samples. Furthermore, RKHSs offer a convenient mathematical and computational framework. We introduce and analyse continuous volume sampling (VS), the continuous counterpart -- for choosing node locations -- of a discrete distribution introduced in (Deshpande & Vempala, 2006). Our contribution is theoretical: we prove almost optimal bounds for interpolation and quadrature under VS. While similar bounds already exist for some specific RKHSs using ad-hoc node constructions, VS offers bounds that apply to any Mercer kernel and depend on the spectrum of the associated integration operator. We emphasize that, unlike previous randomized approaches that rely on regularized leverage scores or determinantal point processes, evaluating the pdf of VS only requires pointwise evaluations of the kernel. VS is thus naturally amenable to MCMC samplers.