 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-art minibatches via novel DPP kernels: discretization, wavelets, and rough objectives
May 13, 2026Determinantal point processes (DPPs) have emerged as a kernelized alternative to vanilla independent sampling for generating efficient minibatches, coresets and other parsimonious representations of large-scale datasets. While theoretical foundations and promising empirical performance have been demonstrated, there are two challenges for current proposals for DPP-based coresets or minibatches. The first is the need for families of DPPs with certain key variance reduction properties, usually constructed in a continuous setting, of which there are few known examples. The second is the need for an ad-hoc construction of a discrete DPP defined on a given dataset, that inherits such variance reduction. In this work, we contribute to the programme of establishing DPPs as a subsampling toolbox for ML by advancing on these two fronts. First, we propose new DPPs on the Euclidean space based on wavelets, with provably better accuracy guarantees than the best known rates. Second, we introduce a general method to convert such continuous DPPs, which are more amenable to proving analytical statements, into discrete kernels, which are pertinent for subsampling tasks such as minibatch and coreset constructions. This conversion mechanism simultaneously preserves the desired variance decay and reveals a low-rank decomposition of the discrete kernel, which makes sampling the corresponding DPP computationally inexpensive. En route, we enlarge the class of ML tasks amenable to improvements via DPP-based minibatches and coresets to include objective functions with arbitrarily low regularity, and rate guarantees that explicitly adapt to this regularity.
On two ways to use determinantal point processes for Monte Carlo integration
Apr 21, 2026The standard Monte Carlo estimator $\widehat{I}_N^{\mathrm{MC}}$ of $\int fdω$ relies on independent samples from $ω$ and has variance of order $1/N$. Replacing the samples with a determinantal point process (DPP), a repulsive distribution, makes the estimator consistent, with variance rates that depend on how the DPP is adapted to $f$ and $ω$. We examine two existing DPP-based estimators: one by Bardenet & Hardy (2020) with a rate of $\mathcal{O}(N^{-(1+1/d)})$ for smooth $f$, but relying on a fixed DPP. The other, by Ermakov & Zolotukhin (1960), is unbiased with rate of order $1/N$, like Monte Carlo, but its DPP is tailored to $f$. We revisit these estimators, generalize them to continuous settings, and provide sampling algorithms.
Filtering through a topological lens: homology for point processes on the time-frequency plane
Apr 10, 2025
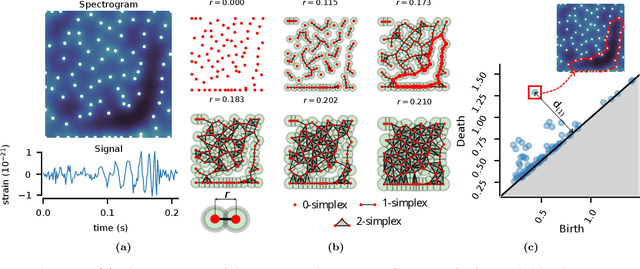
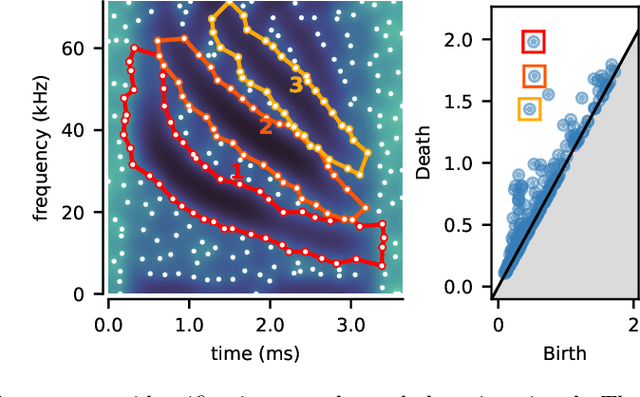
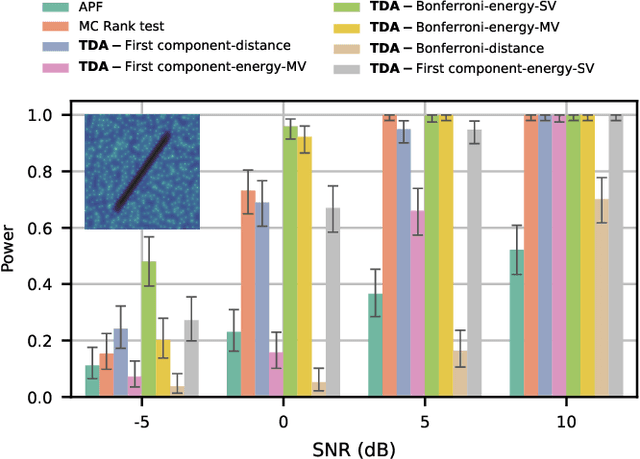
We introduce a very general approach to the analysis of signals from their noisy measurements from the perspective of Topological Data Analysis (TDA). While TDA has emerged as a powerful analytical tool for data with pronounced topological structures, here we demonstrate its applicability for general problems of signal processing, without any a-priori geometric feature. Our methods are well-suited to a wide array of time-dependent signals in different scientific domains, with acoustic signals being a particularly important application. We invoke time-frequency representations of such signals, focusing on their zeros which are gaining salience as a signal processing tool in view of their stability properties. Leveraging state-of-the-art topological concepts, such as stable and minimal volumes, we develop a complete suite of TDA-based methods to explore the delicate stochastic geometry of these zeros, capturing signals based on the disruption they cause to this rigid, hyperuniform spatial structure. Unlike classical spatial data tools, TDA is able to capture the full spectrum of the stochastic geometry of the zeros, thereby leading to powerful inferential outcomes that are underpinned by a principled statistical foundation. This is reflected in the power and versatility of our applications, which include competitive performance in processing. a wide variety of audio signals (esp. in low SNR regimes), effective detection and reconstruction of gravitational wave signals (a reputed signal processing challenge with non-Gaussian noise), and medical time series data from EEGs, indicating a wide horizon for the approach and methods introduced in this paper.
Bypassing orthogonalization in the quantum DPP sampler
Mar 07, 2025



Given an $n\times r$ matrix $X$ of rank $r$, consider the problem of sampling $r$ integers $\mathtt{C}\subset \{1, \dots, n\}$ with probability proportional to the squared determinant of the rows of $X$ indexed by $\mathtt{C}$. The distribution of $\mathtt{C}$ is called a projection determinantal point process (DPP). The vanilla classical algorithm to sample a DPP works in two steps, an orthogonalization in $\mathcal{O}(nr^2)$ and a sampling step of the same cost. The bottleneck of recent quantum approaches to DPP sampling remains that preliminary orthogonalization step. For instance, (Kerenidis and Prakash, 2022) proposed an algorithm with the same $\mathcal{O}(nr^2)$ orthogonalization, followed by a $\mathcal{O}(nr)$ classical step to find the gates in a quantum circuit. The classical $\mathcal{O}(nr^2)$ orthogonalization thus still dominates the cost. Our first contribution is to reduce preprocessing to normalizing the columns of $X$, obtaining $\mathsf{X}$ in $\mathcal{O}(nr)$ classical operations. We show that a simple circuit inspired by the formalism of Kerenidis et al., 2022 samples a DPP of a type we had never encountered in applications, which is different from our target DPP. Plugging this circuit into a rejection sampling routine, we recover our target DPP after an expected $1/\det \mathsf{X}^\top\mathsf{X} = 1/a$ preparations of the quantum circuit. Using amplitude amplification, our second contribution is to boost the acceptance probability from $a$ to $1-a$ at the price of a circuit depth of $\mathcal{O}(r\log n/\sqrt{a})$ and $\mathcal{O}(\log n)$ extra qubits. Prepending a fast, sketching-based classical approximation of $a$, we obtain a pipeline to sample a projection DPP on a quantum computer, where the former $\mathcal{O}(nr^2)$ preprocessing bottleneck has been replaced by the $\mathcal{O}(nr)$ cost of normalizing the columns and the cost of our approximation of $a$.
Small coresets via negative dependence: DPPs, linear statistics, and concentration
Nov 01, 2024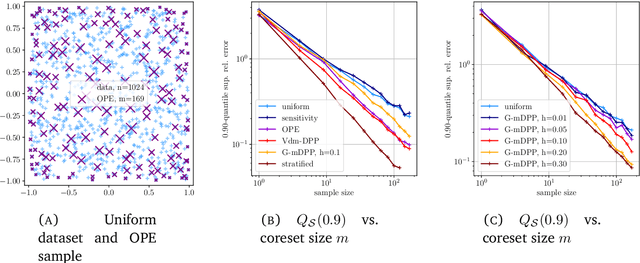
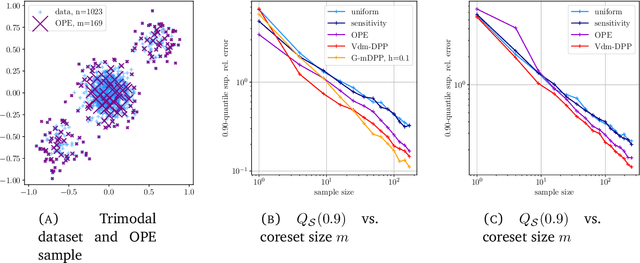
Determinantal point processes (DPPs) are random configurations of points with tunable negative dependence. Because sampling is tractable, DPPs are natural candidates for subsampling tasks, such as minibatch selection or coreset construction. A \emph{coreset} is a subset of a (large) training set, such that minimizing an empirical loss averaged over the coreset is a controlled replacement for the intractable minimization of the original empirical loss. Typically, the control takes the form of a guarantee that the average loss over the coreset approximates the total loss uniformly across the parameter space. Recent work has provided significant empirical support in favor of using DPPs to build randomized coresets, coupled with interesting theoretical results that are suggestive but leave some key questions unanswered. In particular, the central question of whether the cardinality of a DPP-based coreset is fundamentally smaller than one based on independent sampling remained open. In this paper, we answer this question in the affirmative, demonstrating that \emph{DPPs can provably outperform independently drawn coresets}. In this vein, we contribute a conceptual understanding of coreset loss as a \emph{linear statistic} of the (random) coreset. We leverage this structural observation to connect the coresets problem to a more general problem of concentration phenomena for linear statistics of DPPs, wherein we obtain \emph{effective concentration inequalities that extend well-beyond the state-of-the-art}, encompassing general non-projection, even non-symmetric kernels. The latter have been recently shown to be of interest in machine learning beyond coresets, but come with a limited theoretical toolbox, to the extension of which our result contributes. Finally, we are also able to address the coresets problem for vector-valued objective functions, a novelty in the coresets literature.
Point Processes and spatial statistics in time-frequency analysis
Feb 29, 2024

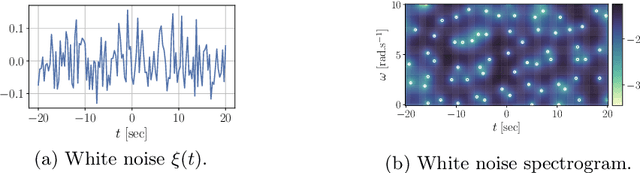

A finite-energy signal is represented by a square-integrable, complex-valued function $t\mapsto s(t)$ of a real variable $t$, interpreted as time. Similarly, a noisy signal is represented by a random process. Time-frequency analysis, a subfield of signal processing, amounts to describing the temporal evolution of the frequency content of a signal. Loosely speaking, if $s$ is the audio recording of a musical piece, time-frequency analysis somehow consists in writing the musical score of the piece. Mathematically, the operation is performed through a transform $\mathcal{V}$, mapping $s \in L^2(\mathbb{R})$ onto a complex-valued function $\mathcal{V}s \in L^2(\mathbb{R}^2)$ of time $t$ and angular frequency $\omega$. The squared modulus $(t, \omega) \mapsto \vert\mathcal{V}s(t,\omega)\vert^2$ of the time-frequency representation is known as the spectrogram of $s$; in the musical score analogy, a peaked spectrogram at $(t_0,\omega_0)$ corresponds to a musical note at angular frequency $\omega_0$ localized at time $t_0$. More generally, the intuition is that upper level sets of the spectrogram contain relevant information about in the original signal. Hence, many signal processing algorithms revolve around identifying maxima of the spectrogram. In contrast, zeros of the spectrogram indicate perfect silence, that is, a time at which a particular frequency is absent. Assimilating $\mathbb{R}^2$ to $\mathbb{C}$ through $z = \omega + \mathrm{i}t$, this chapter focuses on time-frequency transforms $\mathcal{V}$ that map signals to analytic functions. The zeros of the spectrogram of a noisy signal are then the zeros of a random analytic function, hence forming a Point Process in $\mathbb{C}$. This chapter is devoted to the study of these Point Processes, to their links with zeros of Gaussian Analytic Functions, and to designing signal detection and denoising algorithms using spatial statistics.
Monte Carlo with kernel-based Gibbs measures: Guarantees for probabilistic herding
Feb 18, 2024

Kernel herding belongs to a family of deterministic quadratures that seek to minimize the worst-case integration error over a reproducing kernel Hilbert space (RKHS). In spite of strong experimental support, it has revealed difficult to prove that this worst-case error decreases at a faster rate than the standard square root of the number of quadrature nodes, at least in the usual case where the RKHS is infinite-dimensional. In this theoretical paper, we study a joint probability distribution over quadrature nodes, whose support tends to minimize the same worst-case error as kernel herding. We prove that it does outperform i.i.d. Monte Carlo, in the sense of coming with a tighter concentration inequality on the worst-case integration error. While not improving the rate yet, this demonstrates that the mathematical tools of the study of Gibbs measures can help understand to what extent kernel herding and its variants improve on computationally cheaper methods. Moreover, we provide early experimental evidence that a faster rate of convergence, though not worst-case, is likely.
Benchmarking multi-component signal processing methods in the time-frequency plane
Feb 13, 2024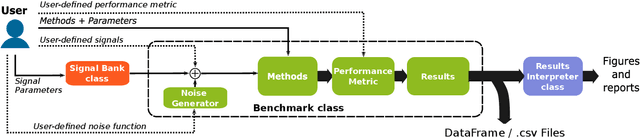

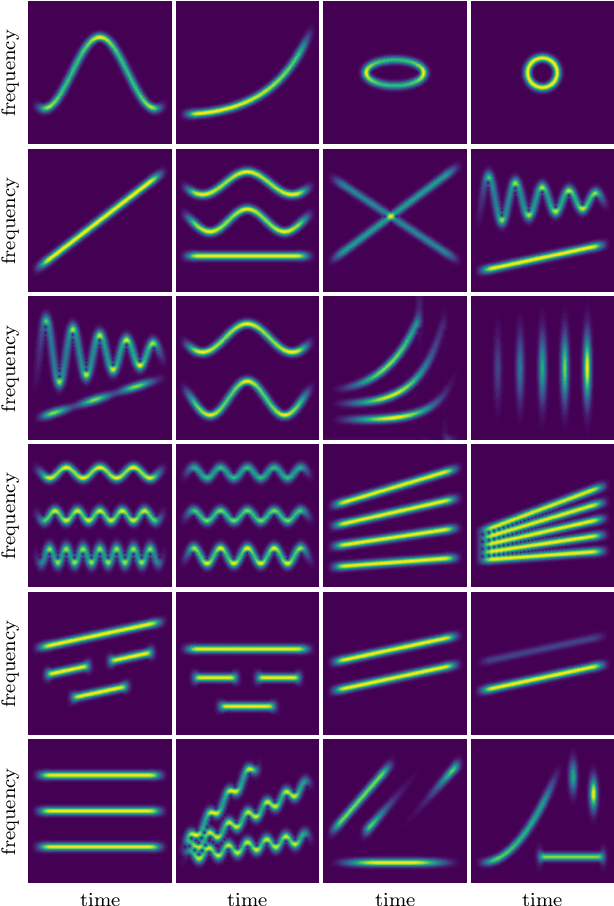

Signal processing in the time-frequency plane has a long history and remains a field of methodological innovation. For instance, detection and denoising based on the zeros of the spectrogram have been proposed since 2015, contrasting with a long history of focusing on larger values of the spectrogram. Yet, unlike neighboring fields like optimization and machine learning, time-frequency signal processing lacks widely-adopted benchmarking tools. In this work, we contribute an open-source, Python-based toolbox termed MCSM-Benchs for benchmarking multi-component signal analysis methods, and we demonstrate our toolbox on three time-frequency benchmarks. First, we compare different methods for signal detection based on the zeros of the spectrogram, including unexplored variations of previously proposed detection tests. Second, we compare zero-based denoising methods to both classical and novel methods based on large values and ridges of the spectrogram. Finally, we compare the denoising performance of these methods against typical spectrogram thresholding strategies, in terms of post-processing artifacts commonly referred to as musical noise. At a low level, the obtained results provide new insight on the assessed approaches, and in particular research directions to further develop zero-based methods. At a higher level, our benchmarks exemplify the benefits of using a public, collaborative, common framework for benchmarking.
Signal reconstruction using determinantal sampling
Oct 13, 2023We study the approximation of a square-integrable function from a finite number of evaluations on a random set of nodes according to a well-chosen distribution. This is particularly relevant when the function is assumed to belong to a reproducing kernel Hilbert space (RKHS). This work proposes to combine several natural finite-dimensional approximations based two possible probability distributions of nodes. These distributions are related to determinantal point processes, and use the kernel of the RKHS to favor RKHS-adapted regularity in the random design. While previous work on determinantal sampling relied on the RKHS norm, we prove mean-square guarantees in $L^2$ norm. We show that determinantal point processes and mixtures thereof can yield fast convergence rates. Our results also shed light on how the rate changes as more smoothness is assumed, a phenomenon known as superconvergence. Besides, determinantal sampling generalizes i.i.d. sampling from the Christoffel function which is standard in the literature. More importantly, determinantal sampling guarantees the so-called instance optimality property for a smaller number of function evaluations than i.i.d. sampling.
On sampling determinantal and Pfaffian point processes on a quantum computer
May 25, 2023DPPs were introduced by Macchi as a model in quantum optics the 1970s. Since then, they have been widely used as models and subsampling tools in statistics and computer science. Most applications require sampling from a DPP, and given their quantum origin, it is natural to wonder whether sampling a DPP on a quantum computer is easier than on a classical one. We focus here on DPPs over a finite state space, which are distributions over the subsets of $\{1,\dots,N\}$ parametrized by an $N\times N$ Hermitian kernel matrix. Vanilla sampling consists in two steps, of respective costs $\mathcal{O}(N^3)$ and $\mathcal{O}(Nr^2)$ operations on a classical computer, where $r$ is the rank of the kernel matrix. A large first part of the current paper consists in explaining why the state-of-the-art in quantum simulation of fermionic systems already yields quantum DPP sampling algorithms. We then modify existing quantum circuits, and discuss their insertion in a full DPP sampling pipeline that starts from practical kernel specifications. The bottom line is that, with $P$ (classical) parallel processors, we can divide the preprocessing cost by $P$ and build a quantum circuit with $\mathcal{O}(Nr)$ gates that sample a given DPP, with depth varying from $\mathcal{O}(N)$ to $\mathcal{O}(r\log N)$ depending on qubit-communication constraints on the target machine. We also connect existing work on the simulation of superconductors to Pfaffian point processes, which generalize DPPs and would be a natural addition to the machine learner's toolbox. Finally, the circuits are empirically validated on a classical simulator and on 5-qubit machines.