 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance Shrinkage via Stochastic Interpolation
Jun 05, 2026We recast classical shrinkage of high-dimensional covariance estimators as empirical risk minimization over a parametric stochastic interpolant between a source and a target distribution. This formalism recovers known shrinkage estimators as special cases and reveals three distinct mechanisms for reducing statistical risk: (i) Scheduling: the interpolant schedule determines the class of admissible covariances, and hence the achievable risk. (ii) Flow maps and couplings: whereas naive constructions amount to assuming independence between the distributions, specific coupling structures (e.g., solutions of optimal transport problems) can lower the empirical risk. Moreover, non-linear flow maps realizing such couplings free the interpolant covariance from the eigenbasis of the empirical estimate, enabling eigenvector regularization. (iii) Early stopping: estimators defined by integrating a regressed vector field afford an additional bias-variance trade-off through approximation of the true interpolant distribution. We then propose a neural estimator of the interpolant, together with an upper bound on its quadratic risk in terms of the interpolant approximation error, and validate both on synthetic experiments. Finally, we apply the estimator to real neuroimaging data, demonstrating the additional regularization power this approach offers in practice.
Random Matrix Theory of Early-Stopped Gradient Flow: A Transient BBP Scenario
Apr 20, 2026Empirical studies of trained models often report a transient regime in which signal is detectable in a finite gradient descent time window before overfitting dominates. We provide an analytically tractable random-matrix model that reproduces this phenomenon for gradient flow in a linear teacher--student setting. In this framework, learning occurs when an isolated eigenvalue separates from a noisy bulk, before eventually disappearing in the overfitting regime. The key ingredient is anisotropy in the input covariance, which induces fast and slow directions in the learning dynamics. In a two-block covariance model, we derive the full time-dependent bulk spectrum of the symmetrized weight matrix through a $2\times 2$ Dyson equation, and we obtain an explicit outlier condition for a rank-one teacher via a rank-two determinant formula. This yields a transient Baik-Ben Arous-Péché (BBP) transition: depending on signal strength and covariance anisotropy, the teacher spike may never emerge, emerge and persist, or emerge only during an intermediate time interval before being reabsorbed into the bulk. We map the corresponding phase diagrams and validate the theory against finite-size simulations. Our results provide a minimal solvable mechanism for early stopping as a transient spectral effect driven by anisotropy and noise.
Training-Free Generative Modeling via Kernelized Stochastic Interpolants
Feb 25, 2026We develop a kernel method for generative modeling within the stochastic interpolant framework, replacing neural network training with linear systems. The drift of the generative SDE is $\hat b_t(x) = \nablaφ(x)^\topη_t$, where $η_t\in\R^P$ solves a $P\times P$ system computable from data, with $P$ independent of the data dimension $d$. Since estimates are inexact, the diffusion coefficient $D_t$ affects sample quality; the optimal $D_t^*$ from Girsanov diverges at $t=0$, but this poses no difficulty and we develop an integrator that handles it seamlessly. The framework accommodates diverse feature maps -- scattering transforms, pretrained generative models etc. -- enabling training-free generation and model combination. We demonstrate the approach on financial time series, turbulence, and image generation.
Probing the Geometry of Diffusion Models with the String Method
Feb 25, 2026Understanding the geometry of learned distributions is fundamental to improving and interpreting diffusion models, yet systematic tools for exploring their landscape remain limited. Standard latent-space interpolations fail to respect the structure of the learned distribution, often traversing low-density regions. We introduce a framework based on the string method that computes continuous paths between samples by evolving curves under the learned score function. Operating on pretrained models without retraining, our approach interpolates between three regimes: pure generative transport, which yields continuous sample paths; gradient-dominated dynamics, which recover minimum energy paths (MEPs); and finite-temperature string dynamics, which compute principal curves -- self-consistent paths that balance energy and entropy. We demonstrate that the choice of regime matters in practice. For image diffusion models, MEPs contain high-likelihood but unrealistic ''cartoon'' images, confirming prior observations that likelihood maxima appear unrealistic; principal curves instead yield realistic morphing sequences despite lower likelihood. For protein structure prediction, our method computes transition pathways between metastable conformers directly from models trained on static structures, yielding paths with physically plausible intermediates. Together, these results establish the string method as a principled tool for probing the modal structure of diffusion models -- identifying modes, characterizing barriers, and mapping connectivity in complex learned distributions.
MGD: Moment Guided Diffusion for Maximum Entropy Generation
Feb 19, 2026Generating samples from limited information is a fundamental problem across scientific domains. Classical maximum entropy methods provide principled uncertainty quantification from moment constraints but require sampling via MCMC or Langevin dynamics, which typically exhibit exponential slowdown in high dimensions. In contrast, generative models based on diffusion and flow matching efficiently transport noise to data but offer limited theoretical guarantees and can overfit when data is scarce. We introduce Moment Guided Diffusion (MGD), which combines elements of both approaches. Building on the stochastic interpolant framework, MGD samples maximum entropy distributions by solving a stochastic differential equation that guides moments toward prescribed values in finite time, thereby avoiding slow mixing in equilibrium-based methods. We formally obtain, in the large-volatility limit, convergence of MGD to the maximum entropy distribution and derive a tractable estimator of the resulting entropy computed directly from the dynamics. Applications to financial time series, turbulent flows, and cosmological fields using wavelet scattering moments yield estimates of negentropy for high-dimensional multiscale processes.
Multitask Learning with Stochastic Interpolants
Aug 06, 2025We propose a framework for learning maps between probability distributions that broadly generalizes the time dynamics of flow and diffusion models. To enable this, we generalize stochastic interpolants by replacing the scalar time variable with vectors, matrices, or linear operators, allowing us to bridge probability distributions across multiple dimensional spaces. This approach enables the construction of versatile generative models capable of fulfilling multiple tasks without task-specific training. Our operator-based interpolants not only provide a unifying theoretical perspective for existing generative models but also extend their capabilities. Through numerical experiments, we demonstrate the zero-shot efficacy of our method on conditional generation and inpainting, fine-tuning and posterior sampling, and multiscale modeling, suggesting its potential as a generic task-agnostic alternative to specialized models.
Normalizing flow sampling with Langevin dynamics in the latent space
May 20, 2023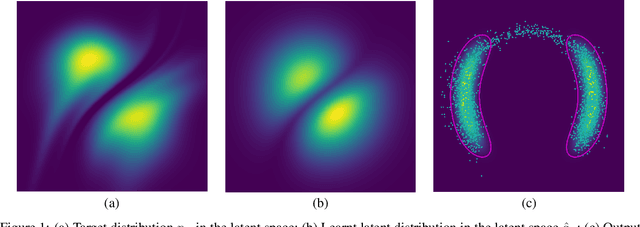



Normalizing flows (NF) use a continuous generator to map a simple latent (e.g. Gaussian) distribution, towards an empirical target distribution associated with a training data set. Once trained by minimizing a variational objective, the learnt map provides an approximate generative model of the target distribution. Since standard NF implement differentiable maps, they may suffer from pathological behaviors when targeting complex distributions. For instance, such problems may appear for distributions on multi-component topologies or characterized by multiple modes with high probability regions separated by very unlikely areas. A typical symptom is the explosion of the Jacobian norm of the transformation in very low probability areas. This paper proposes to overcome this issue thanks to a new Markov chain Monte Carlo algorithm to sample from the target distribution in the latent domain before transporting it back to the target domain. The approach relies on a Metropolis adjusted Langevin algorithm (MALA) whose dynamics explicitly exploits the Jacobian of the transformation. Contrary to alternative approaches, the proposed strategy preserves the tractability of the likelihood and it does not require a specific training. Notably, it can be straightforwardly used with any pre-trained NF network, regardless of the architecture. Experiments conducted on synthetic and high-dimensional real data sets illustrate the efficiency of the method.
Plug-and-Play split Gibbs sampler: embedding deep generative priors in Bayesian inference
Apr 21, 2023This paper introduces a stochastic plug-and-play (PnP) sampling algorithm that leverages variable splitting to efficiently sample from a posterior distribution. The algorithm based on split Gibbs sampling (SGS) draws inspiration from the alternating direction method of multipliers (ADMM). It divides the challenging task of posterior sampling into two simpler sampling problems. The first problem depends on the likelihood function, while the second is interpreted as a Bayesian denoising problem that can be readily carried out by a deep generative model. Specifically, for an illustrative purpose, the proposed method is implemented in this paper using state-of-the-art diffusion-based generative models. Akin to its deterministic PnP-based counterparts, the proposed method exhibits the great advantage of not requiring an explicit choice of the prior distribution, which is rather encoded into a pre-trained generative model. However, unlike optimization methods (e.g., PnP-ADMM) which generally provide only point estimates, the proposed approach allows conventional Bayesian estimators to be accompanied by confidence intervals at a reasonable additional computational cost. Experiments on commonly studied image processing problems illustrate the efficiency of the proposed sampling strategy. Its performance is compared to recent state-of-the-art optimization and sampling methods.
Sliced-Wasserstein normalizing flows: beyond maximum likelihood training
Jul 12, 2022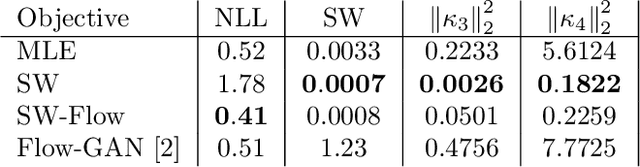
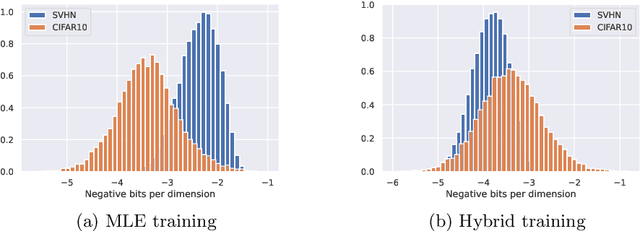

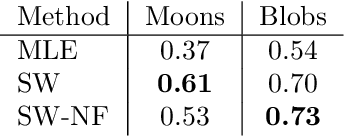
Despite their advantages, normalizing flows generally suffer from several shortcomings including their tendency to generate unrealistic data (e.g., images) and their failing to detect out-of-distribution data. One reason for these deficiencies lies in the training strategy which traditionally exploits a maximum likelihood principle only. This paper proposes a new training paradigm based on a hybrid objective function combining the maximum likelihood principle (MLE) and a sliced-Wasserstein distance. Results obtained on synthetic toy examples and real image data sets show better generative abilities in terms of both likelihood and visual aspects of the generated samples. Reciprocally, the proposed approach leads to a lower likelihood of out-of-distribution data, demonstrating a greater data fidelity of the resulting flows.
Learning Optimal Transport Between two Empirical Distributions with Normalizing Flows
Jul 05, 2022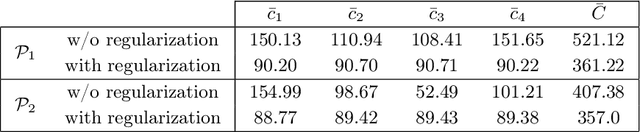
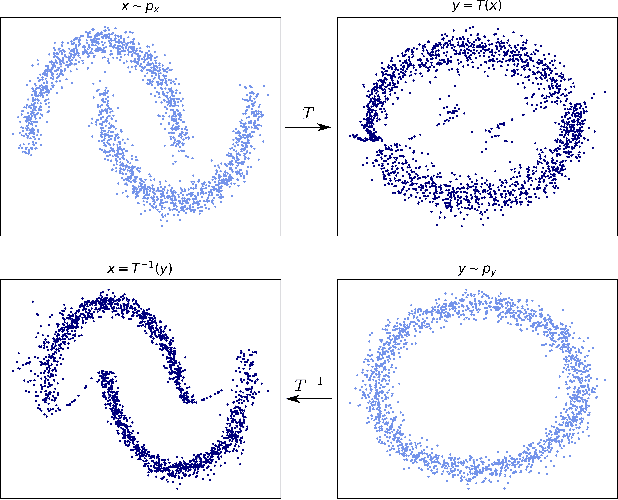
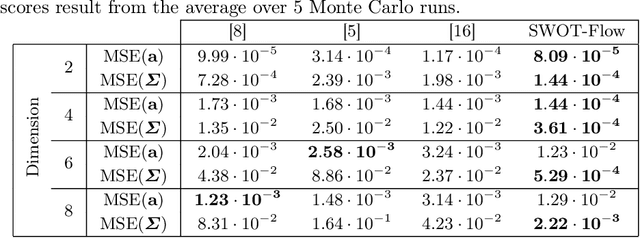

Optimal transport (OT) provides effective tools for comparing and mapping probability measures. We propose to leverage the flexibility of neural networks to learn an approximate optimal transport map. More precisely, we present a new and original method to address the problem of transporting a finite set of samples associated with a first underlying unknown distribution towards another finite set of samples drawn from another unknown distribution. We show that a particular instance of invertible neural networks, namely the normalizing flows, can be used to approximate the solution of this OT problem between a pair of empirical distributions. To this aim, we propose to relax the Monge formulation of OT by replacing the equality constraint on the push-forward measure by the minimization of the corresponding Wasserstein distance. The push-forward operator to be retrieved is then restricted to be a normalizing flow which is trained by optimizing the resulting cost function. This approach allows the transport map to be discretized as a composition of functions. Each of these functions is associated to one sub-flow of the network, whose output provides intermediate steps of the transport between the original and target measures. This discretization yields also a set of intermediate barycenters between the two measures of interest. Experiments conducted on toy examples as well as a challenging task of unsupervised translation demonstrate the interest of the proposed method. Finally, some experiments show that the proposed approach leads to a good approximation of the true OT.