 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoLoR: An ASR-Based Framework for Expedited Endangered Language Documentation with Neo-Aramaic as a Case Study
Dec 06, 2024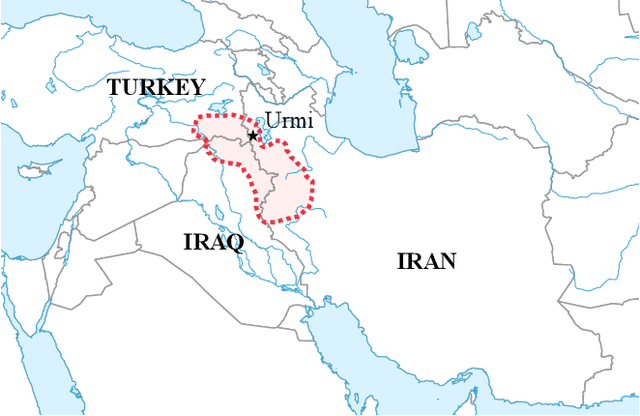

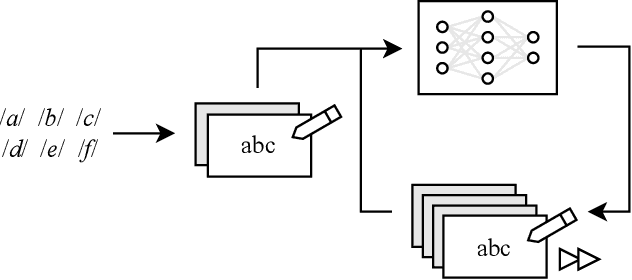
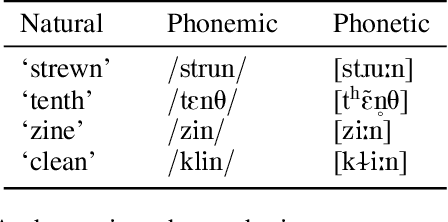
The documentation of the Neo-Aramaic dialects before their extinction has been described as the most urgent task in all of Semitology today. The death of this language will be an unfathomable loss to the descendents of the indigenous speakers of Aramaic, now predominantly diasporic after forced displacement due to violence. This paper develops an ASR model to expedite the documentation of this endangered language and generalizes the strategy in a new framework we call NoLoR.
PCTreeS: 3D Point Cloud Tree Species Classification Using Airborne LiDAR Images
Dec 06, 2024
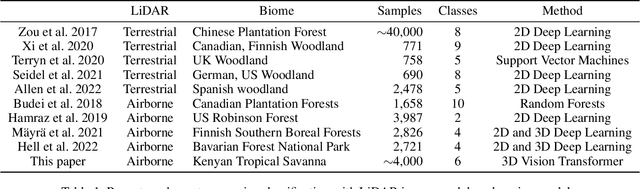

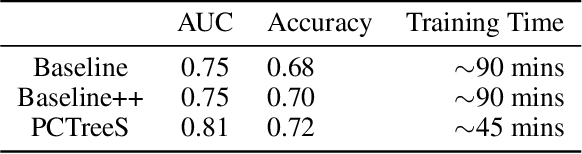
Reliable large-scale data on the state of forests is crucial for monitoring ecosystem health, carbon stock, and the impact of climate change. Current knowledge of tree species distribution relies heavily on manual data collection in the field, which often takes years to complete, resulting in limited datasets that cover only a small subset of the world's forests. Recent works show that state-of-the-art deep learning models using Light Detection and Ranging (LiDAR) images enable accurate and scalable classification of tree species in various ecosystems. While LiDAR images contain rich 3D information, most previous works flatten the 3D images into 2D projections to use Convolutional Neural Networks (CNNs). This paper offers three significant contributions: (1) we apply the deep learning framework for tree classification in tropical savannas; (2) we use Airborne LiDAR images, which have a lower resolution but greater scalability than Terrestrial LiDAR images used in most previous works; (3) we introduce the approach of directly feeding 3D point cloud images into a vision transformer model (PCTreeS). Our results show that the PCTreeS approach outperforms current CNN baselines with 2D projections in AUC (0.81), overall accuracy (0.72), and training time (~45 mins). This paper also motivates further LiDAR image collection and validation for accurate large-scale automatic classification of tree species.
Consistent Explanations in the Face of Model Indeterminacy via Ensembling
Jun 13, 2023



This work addresses the challenge of providing consistent explanations for predictive models in the presence of model indeterminacy, which arises due to the existence of multiple (nearly) equally well-performing models for a given dataset and task. Despite their similar performance, such models often exhibit inconsistent or even contradictory explanations for their predictions, posing challenges to end users who rely on these models to make critical decisions. Recognizing this issue, we introduce ensemble methods as an approach to enhance the consistency of the explanations provided in these scenarios. Leveraging insights from recent work on neural network loss landscapes and mode connectivity, we devise ensemble strategies to efficiently explore the underspecification set -- the set of models with performance variations resulting solely from changes in the random seed during training. Experiments on five benchmark financial datasets reveal that ensembling can yield significant improvements when it comes to explanation similarity, and demonstrate the potential of existing ensemble methods to explore the underspecification set efficiently. Our findings highlight the importance of considering model indeterminacy when interpreting explanations and showcase the effectiveness of ensembles in enhancing the reliability of explanations in machine learning.