 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
May 21, 2025



SDForger is a flexible and efficient framework for generating high-quality multivariate time series using LLMs. Leveraging a compact data representation, SDForger provides synthetic time series generation from a few samples and low-computation fine-tuning of any autoregressive LLM. Specifically, the framework transforms univariate and multivariate signals into tabular embeddings, which are then encoded into text and used to fine-tune the LLM. At inference, new textual embeddings are sampled and decoded into synthetic time series that retain the original data's statistical properties and temporal dynamics. Across a diverse range of datasets, SDForger outperforms existing generative models in many scenarios, both in similarity-based evaluations and downstream forecasting tasks. By enabling textual conditioning in the generation process, SDForger paves the way for multimodal modeling and the streamlined integration of time series with textual information. SDForger source code will be open-sourced soon.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025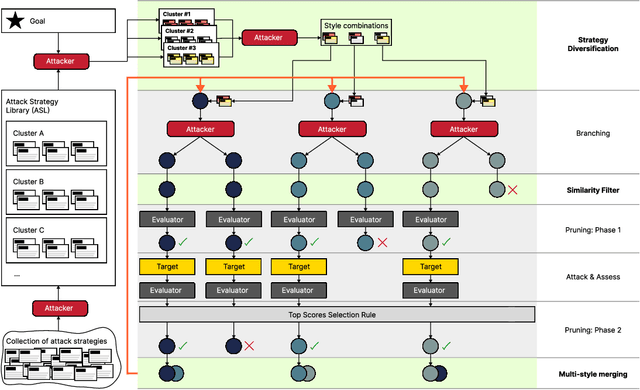
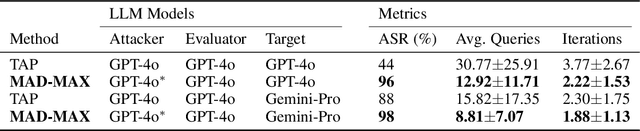
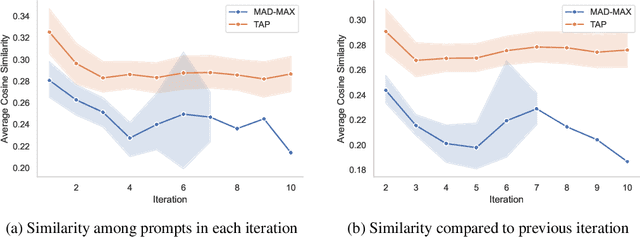
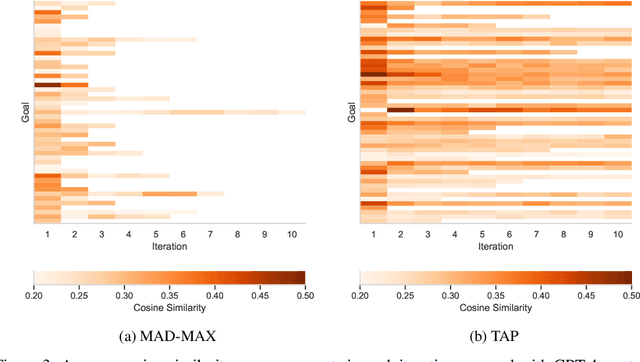
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Adversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025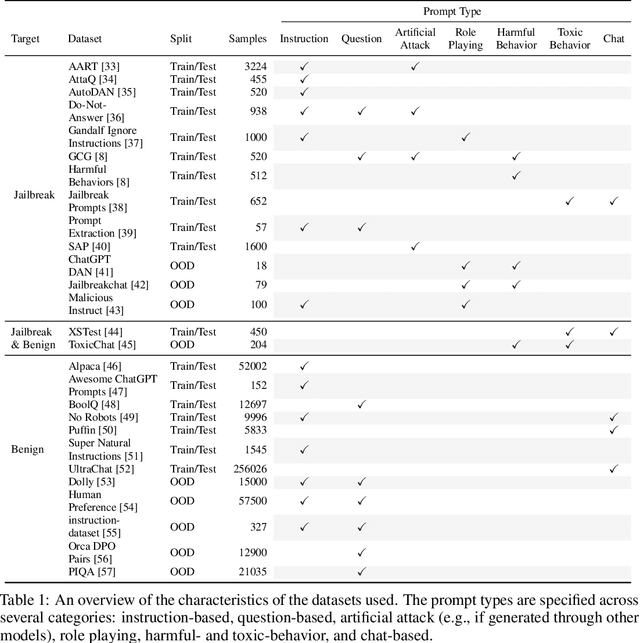
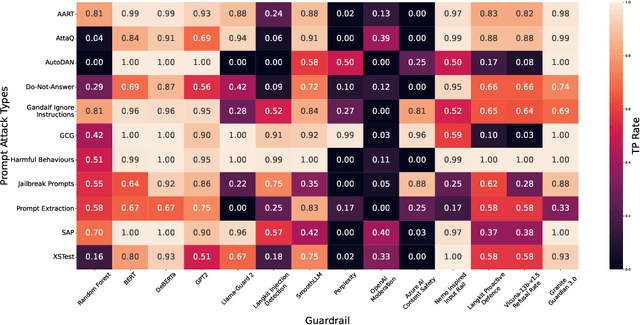
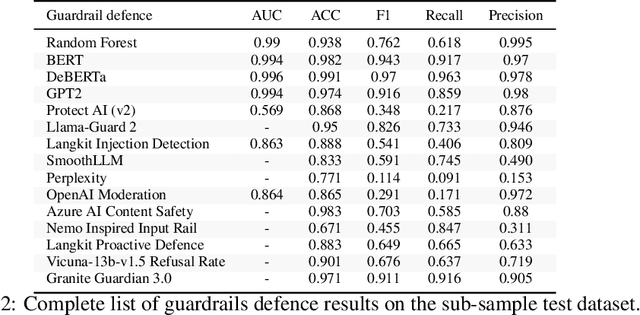
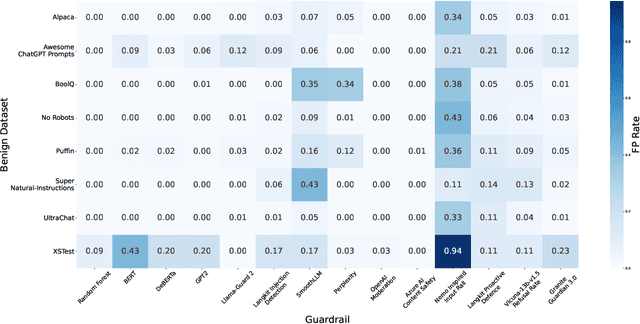
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
MoJE: Mixture of Jailbreak Experts, Naive Tabular Classifiers as Guard for Prompt Attacks
Sep 27, 2024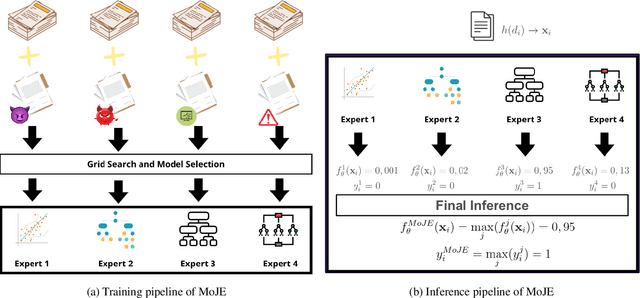
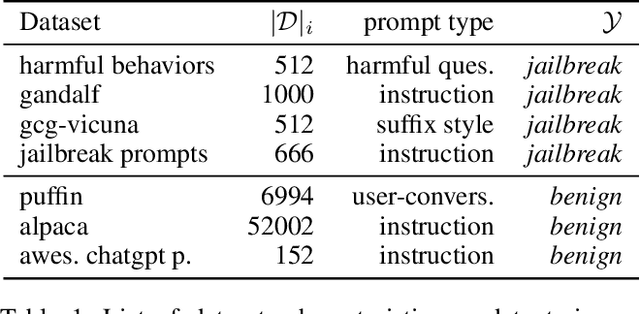
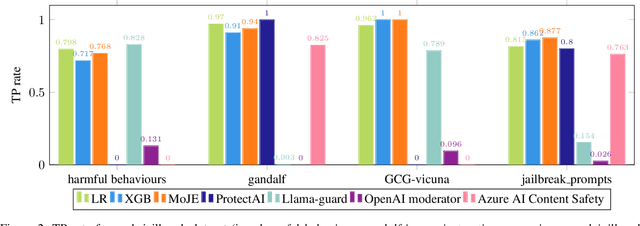
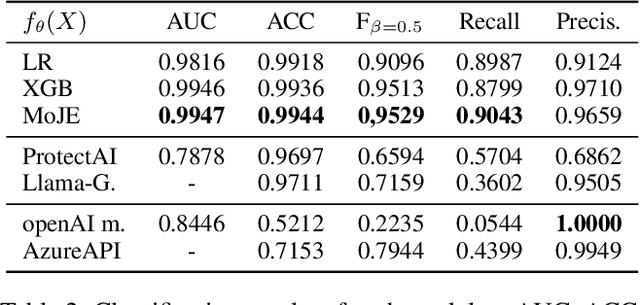
The proliferation of Large Language Models (LLMs) in diverse applications underscores the pressing need for robust security measures to thwart potential jailbreak attacks. These attacks exploit vulnerabilities within LLMs, endanger data integrity and user privacy. Guardrails serve as crucial protective mechanisms against such threats, but existing models often fall short in terms of both detection accuracy, and computational efficiency. This paper advocates for the significance of jailbreak attack prevention on LLMs, and emphasises the role of input guardrails in safeguarding these models. We introduce MoJE (Mixture of Jailbreak Expert), a novel guardrail architecture designed to surpass current limitations in existing state-of-the-art guardrails. By employing simple linguistic statistical techniques, MoJE excels in detecting jailbreak attacks while maintaining minimal computational overhead during model inference. Through rigorous experimentation, MoJE demonstrates superior performance capable of detecting 90% of the attacks without compromising benign prompts, enhancing LLMs security against jailbreak attacks.
Formalizing Multimedia Recommendation through Multimodal Deep Learning
Sep 11, 2023Recommender systems (RSs) offer personalized navigation experiences on online platforms, but recommendation remains a challenging task, particularly in specific scenarios and domains. Multimodality can help tap into richer information sources and construct more refined user/item profiles for recommendations. However, existing literature lacks a shared and universal schema for modeling and solving the recommendation problem through the lens of multimodality. This work aims to formalize a general multimodal schema for multimedia recommendation. It provides a comprehensive literature review of multimodal approaches for multimedia recommendation from the last eight years, outlines the theoretical foundations of a multimodal pipeline, and demonstrates its rationale by applying it to selected state-of-the-art approaches. The work also conducts a benchmarking analysis of recent algorithms for multimedia recommendation within Elliot, a rigorous framework for evaluating recommender systems. The main aim is to provide guidelines for designing and implementing the next generation of multimodal approaches in multimedia recommendation.
On Popularity Bias of Multimodal-aware Recommender Systems: a Modalities-driven Analysis
Aug 24, 2023
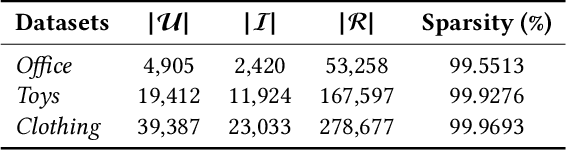
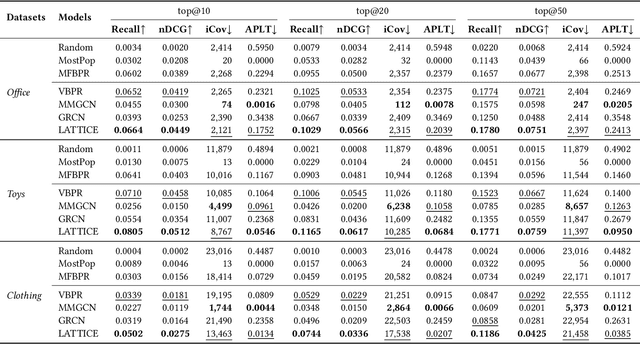

Multimodal-aware recommender systems (MRSs) exploit multimodal content (e.g., product images or descriptions) as items' side information to improve recommendation accuracy. While most of such methods rely on factorization models (e.g., MFBPR) as base architecture, it has been shown that MFBPR may be affected by popularity bias, meaning that it inherently tends to boost the recommendation of popular (i.e., short-head) items at the detriment of niche (i.e., long-tail) items from the catalog. Motivated by this assumption, in this work, we provide one of the first analyses on how multimodality in recommendation could further amplify popularity bias. Concretely, we evaluate the performance of four state-of-the-art MRSs algorithms (i.e., VBPR, MMGCN, GRCN, LATTICE) on three datasets from Amazon by assessing, along with recommendation accuracy metrics, performance measures accounting for the diversity of recommended items and the portion of retrieved niche items. To better investigate this aspect, we decide to study the separate influence of each modality (i.e., visual and textual) on popularity bias in different evaluation dimensions. Results, which demonstrate how the single modality may augment the negative effect of popularity bias, shed light on the importance to provide a more rigorous analysis of the performance of such models.
Counterfactual Reasoning for Bias Evaluation and Detection in a Fairness under Unawareness setting
Feb 16, 2023



Current AI regulations require discarding sensitive features (e.g., gender, race, religion) in the algorithm's decision-making process to prevent unfair outcomes. However, even without sensitive features in the training set, algorithms can persist in discrimination. Indeed, when sensitive features are omitted (fairness under unawareness), they could be inferred through non-linear relations with the so called proxy features. In this work, we propose a way to reveal the potential hidden bias of a machine learning model that can persist even when sensitive features are discarded. This study shows that it is possible to unveil whether the black-box predictor is still biased by exploiting counterfactual reasoning. In detail, when the predictor provides a negative classification outcome, our approach first builds counterfactual examples for a discriminated user category to obtain a positive outcome. Then, the same counterfactual samples feed an external classifier (that targets a sensitive feature) that reveals whether the modifications to the user characteristics needed for a positive outcome moved the individual to the non-discriminated group. When this occurs, it could be a warning sign for discriminatory behavior in the decision process. Furthermore, we leverage the deviation of counterfactuals from the original sample to determine which features are proxies of specific sensitive information. Our experiments show that, even if the model is trained without sensitive features, it often suffers discriminatory biases.
Counterfactual Fair Opportunity: Measuring Decision Model Fairness with Counterfactual Reasoning
Feb 16, 2023



The increasing application of Artificial Intelligence and Machine Learning models poses potential risks of unfair behavior and, in light of recent regulations, has attracted the attention of the research community. Several researchers focused on seeking new fairness definitions or developing approaches to identify biased predictions. However, none try to exploit the counterfactual space to this aim. In that direction, the methodology proposed in this work aims to unveil unfair model behaviors using counterfactual reasoning in the case of fairness under unawareness setting. A counterfactual version of equal opportunity named counterfactual fair opportunity is defined and two novel metrics that analyze the sensitive information of counterfactual samples are introduced. Experimental results on three different datasets show the efficacy of our methodologies and our metrics, disclosing the unfair behavior of classic machine learning and debiasing models.