 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds for Spectral GNNs via Fourier Domain Analysis
Apr 01, 2026Spectral graph neural networks learn graph filters, but their behavior with increasing depth and polynomial order is not well understood. We analyze these models in the graph Fourier domain, where each layer becomes an element-wise frequency update, separating the fixed spectrum from trainable parameters and making depth and order explicit. In this setting, we show that Gaussian complexity is invariant under the Graph Fourier Transform, which allows us to derive data-dependent, depth, and order-aware generalization bounds together with stability estimates. In the linear case, our bounds are tighter, and on real graphs, the data-dependent term correlates with the generalization gap across polynomial bases, highlighting practical choices that avoid frequency amplification across layers.
Training-free Graph-based Imputation of Missing Modalities in Multimodal Recommendation
Feb 19, 2026Multimodal recommender systems (RSs) represent items in the catalog through multimodal data (e.g., product images and descriptions) that, in some cases, might be noisy or (even worse) missing. In those scenarios, the common practice is to drop items with missing modalities and train the multimodal RSs on a subsample of the original dataset. To date, the problem of missing modalities in multimodal recommendation has still received limited attention in the literature, lacking a precise formalisation as done with missing information in traditional machine learning. In this work, we first provide a problem formalisation for missing modalities in multimodal recommendation. Second, by leveraging the user-item graph structure, we re-cast the problem of missing multimodal information as a problem of graph features interpolation on the item-item co-purchase graph. On this basis, we propose four training-free approaches that propagate the available multimodal features throughout the item-item graph to impute the missing features. Extensive experiments on popular multimodal recommendation datasets demonstrate that our solutions can be seamlessly plugged into any existing multimodal RS and benchmarking framework while still preserving (or even widen) the performance gap between multimodal and traditional RSs. Moreover, we show that our graph-based techniques can perform better than traditional imputations in machine learning under different missing modalities settings. Finally, we analyse (for the first time in multimodal RSs) how feature homophily calculated on the item-item graph can influence our graph-based imputations.
On the Impact of Graph Neural Networks in Recommender Systems: A Topological Perspective
Dec 08, 2025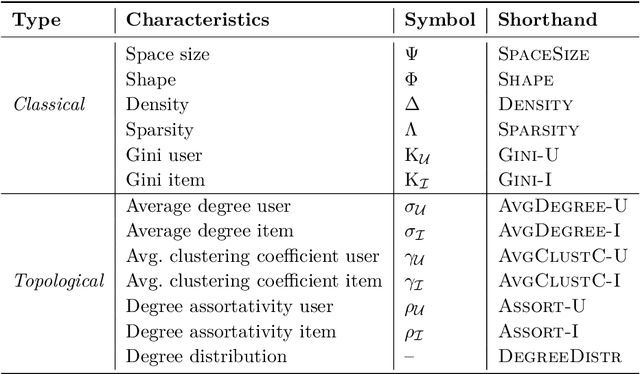
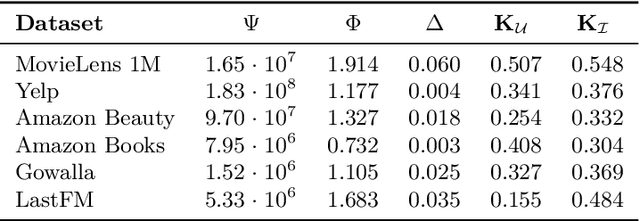
In recommender systems, user-item interactions can be modeled as a bipartite graph, where user and item nodes are connected by undirected edges. This graph-based view has motivated the rapid adoption of graph neural networks (GNNs), which often outperform collaborative filtering (CF) methods such as latent factor models, deep neural networks, and generative strategies. Yet, despite their empirical success, the reasons why GNNs offer systematic advantages over other CF approaches remain only partially understood. This monograph advances a topology-centered perspective on GNN-based recommendation. We argue that a comprehensive understanding of these models' performance should consider the structural properties of user-item graphs and their interaction with GNN architectural design. To support this view, we introduce a formal taxonomy that distills common modeling patterns across eleven representative GNN-based recommendation approaches and consolidates them into a unified conceptual pipeline. We further formalize thirteen classical and topological characteristics of recommendation datasets and reinterpret them through the lens of graph machine learning. Using these definitions, we analyze the considered GNN-based recommender architectures to assess how and to what extent they encode such properties. Building on this analysis, we derive an explanatory framework that links measurable dataset characteristics to model behavior and performance. Taken together, this monograph re-frames GNN-based recommendation through its topological underpinnings and outlines open theoretical, data-centric, and evaluation challenges for the next generation of topology-aware recommender systems.
ContextGNN goes to Elliot: Towards Benchmarking Relational Deep Learning for Static Link Prediction (aka Personalized Item Recommendation)
Mar 20, 2025

Relational deep learning (RDL) settles among the most exciting advances in machine learning for relational databases, leveraging the representational power of message passing graph neural networks (GNNs) to derive useful knowledge and run predicting tasks on tables connected through primary-to-foreign key links. The RDL paradigm has been successfully applied to recommendation lately, through its most recent representative deep learning architecture namely, ContextGNN. While acknowledging ContextGNN's improved performance on real-world recommendation datasets and tasks, preliminary tests for the more traditional static link prediction task (aka personalized item recommendation) on the popular Amazon Book dataset have demonstrated how ContextGNN has still room for improvement compared to other state-of-the-art GNN-based recommender systems. To this end, with this paper, we integrate ContextGNN within Elliot, a popular framework for reproducibility and benchmarking analyses, counting around 50 state-of-the-art recommendation models from the literature to date. On such basis, we run preliminary experiments on three standard recommendation datasets and against six state-of-the-art GNN-based recommender systems, confirming similar trends to those observed by the authors in their original paper. The code is publicly available on GitHub: https://github.com/danielemalitesta/Rel-DeepLearning-RecSys.
DataRec: A Framework for Standardizing Recommendation Data Processing and Analysis
Oct 30, 2024



Thanks to the great interest posed by researchers and companies, recommendation systems became a cornerstone of machine learning applications. However, concerns have arisen recently about the need for reproducibility, making it challenging to identify suitable pipelines. Several frameworks have been proposed to improve reproducibility, covering the entire process from data reading to performance evaluation. Despite this effort, these solutions often overlook the role of data management, do not promote interoperability, and neglect data analysis despite its well-known impact on recommender performance. To address these gaps, we propose DataRec, which facilitates using and manipulating recommendation datasets. DataRec supports reading and writing in various formats, offers filtering and splitting techniques, and enables data distribution analysis using well-known metrics. It encourages a unified approach to data manipulation by allowing data export in formats compatible with several recommendation frameworks.
Ducho meets Elliot: Large-scale Benchmarks for Multimodal Recommendation
Sep 24, 2024



In specific domains like fashion, music, and movie recommendation, the multi-faceted features characterizing products and services may influence each customer on online selling platforms differently, paving the way to novel multimodal recommendation models that can learn from such multimodal content. According to the literature, the common multimodal recommendation pipeline involves (i) extracting multimodal features, (ii) refining their high-level representations to suit the recommendation task, (iii) optionally fusing all multimodal features, and (iv) predicting the user-item score. While great effort has been put into designing optimal solutions for (ii-iv), to the best of our knowledge, very little attention has been devoted to exploring procedures for (i). In this respect, the existing literature outlines the large availability of multimodal datasets and the ever-growing number of large models accounting for multimodal-aware tasks, but (at the same time) an unjustified adoption of limited standardized solutions. This motivates us to explore more extensive techniques for the (i) stage of the pipeline. To this end, this paper settles as the first attempt to offer a large-scale benchmarking for multimodal recommender systems, with a specific focus on multimodal extractors. Specifically, we take advantage of two popular and recent frameworks for multimodal feature extraction and reproducibility in recommendation, Ducho and Elliot, to offer a unified and ready-to-use experimental environment able to run extensive benchmarking analyses leveraging novel multimodal feature extractors. Results, largely validated under different hyper-parameter settings for the chosen extractors, provide important insights on how to train and tune the next generation of multimodal recommendation algorithms.
Dot Product is All You Need: Bridging the Gap Between Item Recommendation and Link Prediction
Sep 11, 2024


Item recommendation (the task of predicting if a user may interact with new items from the catalogue in a recommendation system) and link prediction (the task of identifying missing links in a knowledge graph) have long been regarded as distinct problems. In this work, we show that the item recommendation problem can be seen as an instance of the link prediction problem, where entities in the graph represent users and items, and the task consists of predicting missing instances of the relation type <<interactsWith>>. In a preliminary attempt to demonstrate the assumption, we decide to test three popular factorisation-based link prediction models on the item recommendation task, showing that their predictive accuracy is competitive with ten state-of-the-art recommendation models. The purpose is to show how the former may be seamlessly and effectively applied to the recommendation task without any specific modification to their architectures. Finally, while beginning to unveil the key reasons behind the recommendation performance of the selected link prediction models, we explore different settings for their hyper-parameter values, paving the way for future directions.
How Fair is Your Diffusion Recommender Model?
Sep 06, 2024



Diffusion-based recommender systems have recently proven to outperform traditional generative recommendation approaches, such as variational autoencoders and generative adversarial networks. Nevertheless, the machine learning literature has raised several concerns regarding the possibility that diffusion models, while learning the distribution of data samples, may inadvertently carry information bias and lead to unfair outcomes. In light of this aspect, and considering the relevance that fairness has held in recommendations over the last few decades, we conduct one of the first fairness investigations in the literature on DiffRec, a pioneer approach in diffusion-based recommendation. First, we propose an experimental setting involving DiffRec (and its variant L-DiffRec) along with nine state-of-the-art recommendation models, two popular recommendation datasets from the fairness-aware literature, and six metrics accounting for accuracy and consumer/provider fairness. Then, we perform a twofold analysis, one assessing models' performance under accuracy and recommendation fairness separately, and the other identifying if and to what extent such metrics can strike a performance trade-off. Experimental results from both studies confirm the initial unfairness warnings but pave the way for how to address them in future research directions.
Do We Really Need to Drop Items with Missing Modalities in Multimodal Recommendation?
Aug 21, 2024
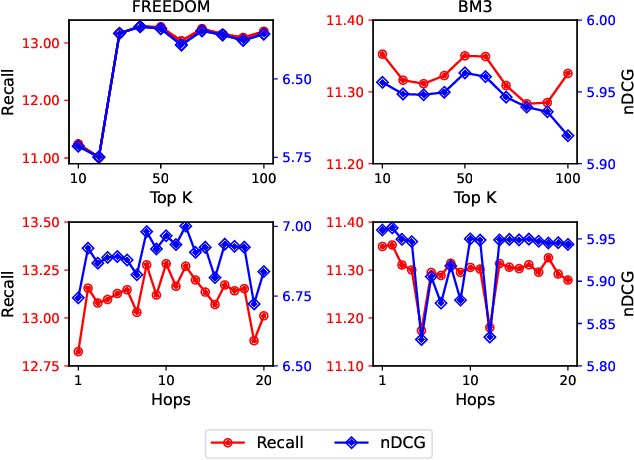
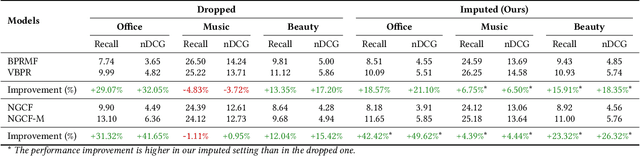
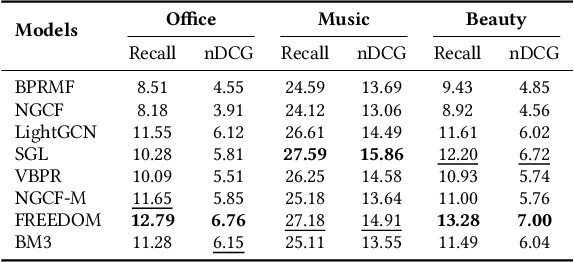
Generally, items with missing modalities are dropped in multimodal recommendation. However, with this work, we question this procedure, highlighting that it would further damage the pipeline of any multimodal recommender system. First, we show that the lack of (some) modalities is, in fact, a widely-diffused phenomenon in multimodal recommendation. Second, we propose a pipeline that imputes missing multimodal features in recommendation by leveraging traditional imputation strategies in machine learning. Then, given the graph structure of the recommendation data, we also propose three more effective imputation solutions that leverage the item-item co-purchase graph and the multimodal similarities of co-interacted items. Our method can be plugged into any multimodal RSs in the literature working as an untrained pre-processing phase, showing (through extensive experiments) that any data pre-filtering is not only unnecessary but also harmful to the performance.
A Novel Evaluation Perspective on GNNs-based Recommender Systems through the Topology of the User-Item Graph
Aug 21, 2024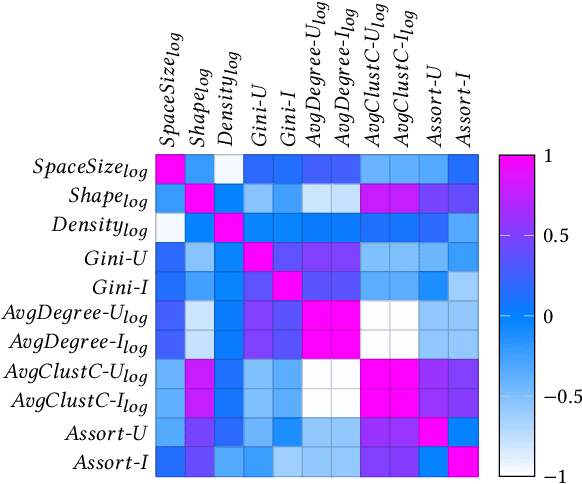
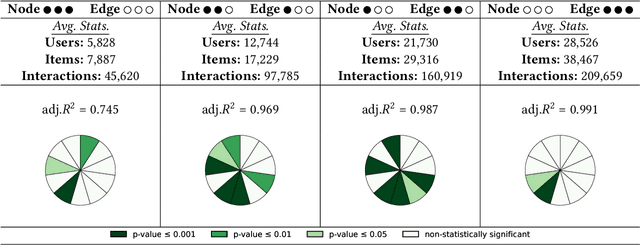
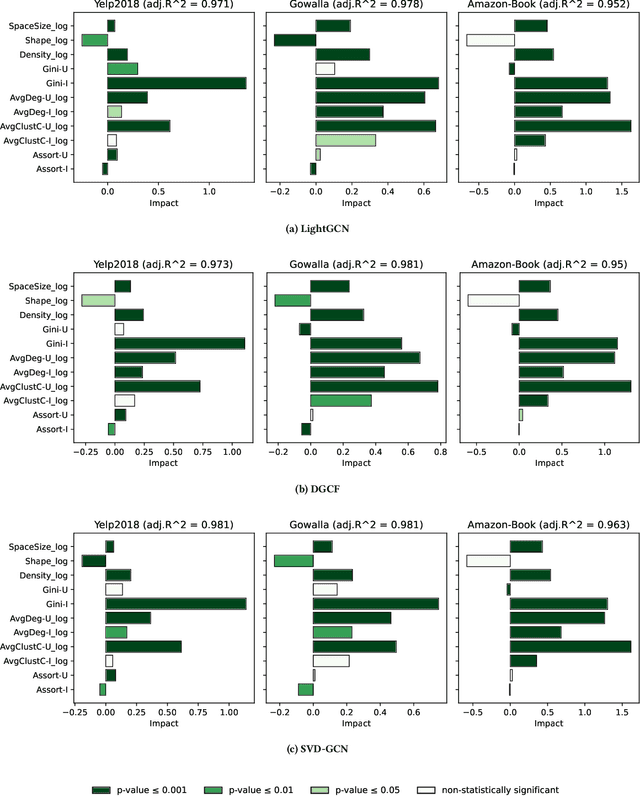
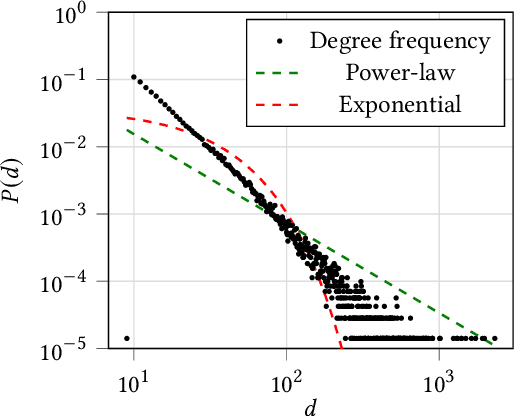
Recently, graph neural networks (GNNs)-based recommender systems have encountered great success in recommendation. As the number of GNNs approaches rises, some works have started questioning the theoretical and empirical reasons behind their superior performance. Nevertheless, this investigation still disregards that GNNs treat the recommendation data as a topological graph structure. Building on this assumption, in this work, we provide a novel evaluation perspective on GNNs-based recommendation, which investigates the impact of the graph topology on the recommendation performance. To this end, we select some (topological) properties of the recommendation data and three GNNs-based recommender systems (i.e., LightGCN, DGCF, and SVD-GCN). Then, starting from three popular recommendation datasets (i.e., Yelp2018, Gowalla, and Amazon-Book) we sample them to obtain 1,800 size-reduced datasets that still resemble the original ones but can encompass a wider range of topological structures. We use this procedure to build a large pool of samples for which data characteristics and recommendation performance of the selected GNNs models are measured. Through an explanatory framework, we find strong correspondences between graph topology and GNNs performance, offering a novel evaluation perspective on these models.