 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Missing Modalities in Multimodal Recommendation: a Feature Propagation-based Approach
Paper and Code
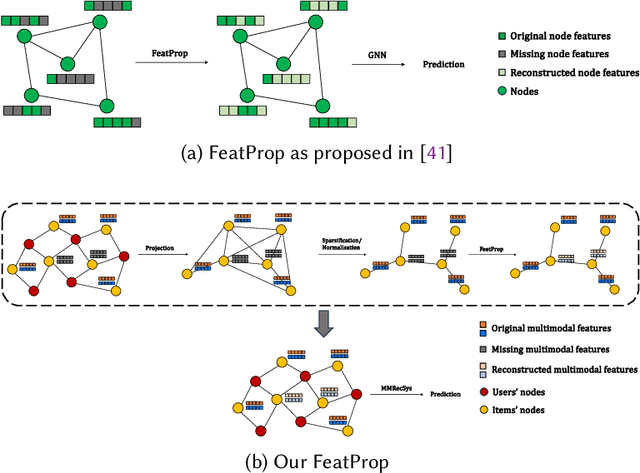
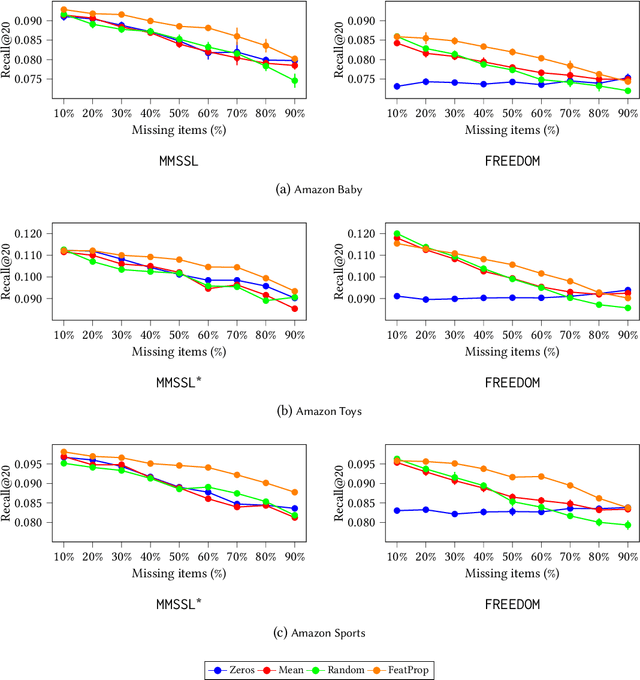
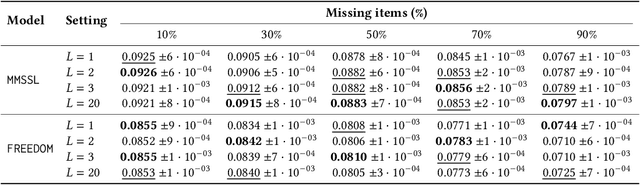
Multimodal recommender systems work by augmenting the representation of the products in the catalogue through multimodal features extracted from images, textual descriptions, or audio tracks characterising such products. Nevertheless, in real-world applications, only a limited percentage of products come with multimodal content to extract meaningful features from, making it hard to provide accurate recommendations. To the best of our knowledge, very few attention has been put into the problem of missing modalities in multimodal recommendation so far. To this end, our paper comes as a preliminary attempt to formalise and address such an issue. Inspired by the recent advances in graph representation learning, we propose to re-sketch the missing modalities problem as a problem of missing graph node features to apply the state-of-the-art feature propagation algorithm eventually. Technically, we first project the user-item graph into an item-item one based on co-interactions. Then, leveraging the multimodal similarities among co-interacted items, we apply a modified version of the feature propagation technique to impute the missing multimodal features. Adopted as a pre-processing stage for two recent multimodal recommender systems, our simple approach performs better than other shallower solutions on three popular datasets.