 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Higher-Order Graph Learning with Maximal Clique Complexes
May 29, 2026Graph neural networks (GNNs) are limited to modeling pairwise interactions, while higher-order models based on cell complexes achieve greater expressivity but often suffer from poor scalability. We introduce simplified and factored cellular Weisfeiler Leman tests (sCWL and fCWL), which preserve the expressivity of the CWL test while improving computational efficiency. We further introduce the maximal clique complex, enabling scalable CWNs with reduced time and memory complexity while retaining strong empirical performance. To avoid explicit clique enumeration, we propose CliqueWalk, a biased random walk that samples maximal cliques and scales linearly with graph size. These contributions yield a scalable topological learning framework for higher-order graph representation.
TriForces: Augmenting Atomistic GNNs for Transferable Representations
May 20, 2026Machine learning interatomic potentials (MLIPs) achieve excellent accuracy when trained on large Density Functional Theory (DFT) data. To be useful in practice, they must often be adapted to target chemistries using small and expensive task-specific datasets. However, MLIPs transfer inconsistently across domains, with representations that often loose accessible composition and structure information. To address this, we present TriForces, a model-agnostic three-stream framework that separates composition and structure information, combined with self-supervised learning to preserve transferable representations. TriForces improves performance on MatBench and QM9 over baselines without needing DFT labels and enables efficient similar structure retrieval through its learned latent space. On OMat24, in limited-data training regime, TriForces reduces energy MAE by 57% at 20K samples only and improves force MAE across sample sizes. We release pretrained TriForces variants across multiple MLIP architectures with code at https://github.com/Ramlaoui/triforces.
Generalization Bounds for Spectral GNNs via Fourier Domain Analysis
Apr 01, 2026Spectral graph neural networks learn graph filters, but their behavior with increasing depth and polynomial order is not well understood. We analyze these models in the graph Fourier domain, where each layer becomes an element-wise frequency update, separating the fixed spectrum from trainable parameters and making depth and order explicit. In this setting, we show that Gaussian complexity is invariant under the Graph Fourier Transform, which allows us to derive data-dependent, depth, and order-aware generalization bounds together with stability estimates. In the linear case, our bounds are tighter, and on real graphs, the data-dependent term correlates with the generalization gap across polynomial bases, highlighting practical choices that avoid frequency amplification across layers.
Training-free Graph-based Imputation of Missing Modalities in Multimodal Recommendation
Feb 19, 2026Multimodal recommender systems (RSs) represent items in the catalog through multimodal data (e.g., product images and descriptions) that, in some cases, might be noisy or (even worse) missing. In those scenarios, the common practice is to drop items with missing modalities and train the multimodal RSs on a subsample of the original dataset. To date, the problem of missing modalities in multimodal recommendation has still received limited attention in the literature, lacking a precise formalisation as done with missing information in traditional machine learning. In this work, we first provide a problem formalisation for missing modalities in multimodal recommendation. Second, by leveraging the user-item graph structure, we re-cast the problem of missing multimodal information as a problem of graph features interpolation on the item-item co-purchase graph. On this basis, we propose four training-free approaches that propagate the available multimodal features throughout the item-item graph to impute the missing features. Extensive experiments on popular multimodal recommendation datasets demonstrate that our solutions can be seamlessly plugged into any existing multimodal RS and benchmarking framework while still preserving (or even widen) the performance gap between multimodal and traditional RSs. Moreover, we show that our graph-based techniques can perform better than traditional imputations in machine learning under different missing modalities settings. Finally, we analyse (for the first time in multimodal RSs) how feature homophily calculated on the item-item graph can influence our graph-based imputations.
Dynamic Triangulation-Based Graph Rewiring for Graph Neural Networks
Aug 28, 2025Graph Neural Networks (GNNs) have emerged as the leading paradigm for learning over graph-structured data. However, their performance is limited by issues inherent to graph topology, most notably oversquashing and oversmoothing. Recent advances in graph rewiring aim to mitigate these limitations by modifying the graph topology to promote more effective information propagation. In this work, we introduce TRIGON, a novel framework that constructs enriched, non-planar triangulations by learning to select relevant triangles from multiple graph views. By jointly optimizing triangle selection and downstream classification performance, our method produces a rewired graph with markedly improved structural properties such as reduced diameter, increased spectral gap, and lower effective resistance compared to existing rewiring methods. Empirical results demonstrate that TRIGON outperforms state-of-the-art approaches on node classification tasks across a range of homophilic and heterophilic benchmarks.
Piecewise Constant Spectral Graph Neural Network
May 07, 2025Graph Neural Networks (GNNs) have achieved significant success across various domains by leveraging graph structures in data. Existing spectral GNNs, which use low-degree polynomial filters to capture graph spectral properties, may not fully identify the graph's spectral characteristics because of the polynomial's small degree. However, increasing the polynomial degree is computationally expensive and beyond certain thresholds leads to performance plateaus or degradation. In this paper, we introduce the Piecewise Constant Spectral Graph Neural Network(PieCoN) to address these challenges. PieCoN combines constant spectral filters with polynomial filters to provide a more flexible way to leverage the graph structure. By adaptively partitioning the spectrum into intervals, our approach increases the range of spectral properties that can be effectively learned. Experiments on nine benchmark datasets, including both homophilic and heterophilic graphs, demonstrate that PieCoN is particularly effective on heterophilic datasets, highlighting its potential for a wide range of applications.
COSMOS: Continuous Simplicial Neural Networks
Mar 17, 2025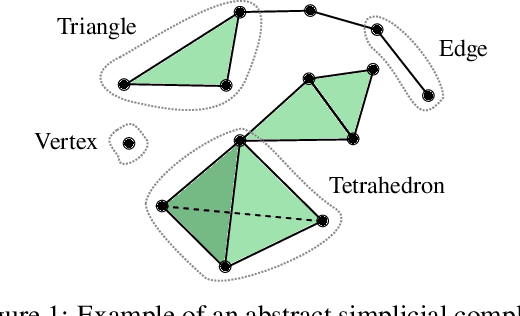
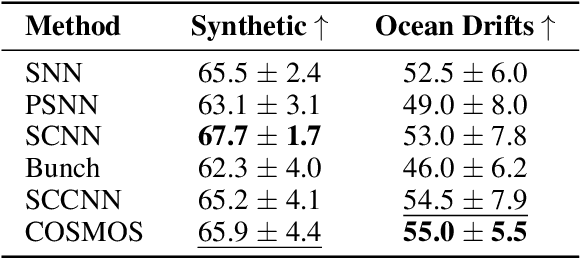


Simplicial complexes provide a powerful framework for modeling high-order interactions in structured data, making them particularly suitable for applications such as trajectory prediction and mesh processing. However, existing simplicial neural networks (SNNs), whether convolutional or attention-based, rely primarily on discrete filtering techniques, which can be restrictive. In contrast, partial differential equations (PDEs) on simplicial complexes offer a principled approach to capture continuous dynamics in such structures. In this work, we introduce COntinuous SiMplicial neural netwOrkS (COSMOS), a novel SNN architecture derived from PDEs on simplicial complexes. We provide theoretical and experimental justifications of COSMOS's stability under simplicial perturbations. Furthermore, we investigate the over-smoothing phenomenon, a common issue in geometric deep learning, demonstrating that COSMOS offers better control over this effect than discrete SNNs. Our experiments on real-world datasets of ocean trajectory prediction and regression on partial deformable shapes demonstrate that COSMOS achieves competitive performance compared to state-of-the-art SNNs in complex and noisy environments.
A Fused Gromov-Wasserstein Approach to Subgraph Contrastive Learning
Feb 28, 2025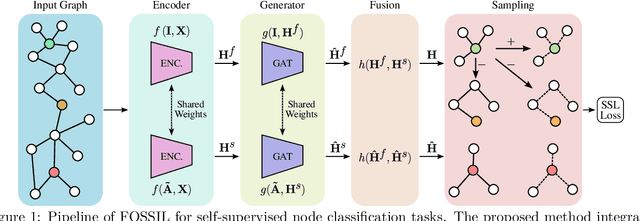
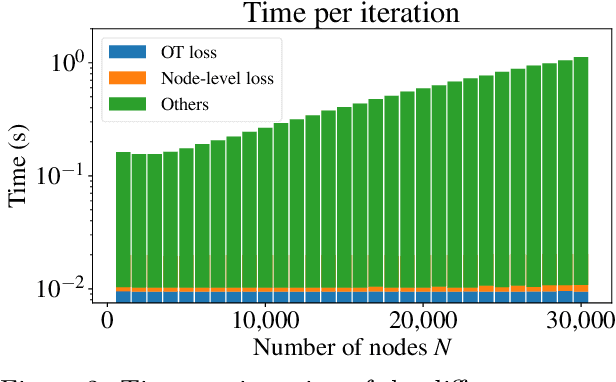
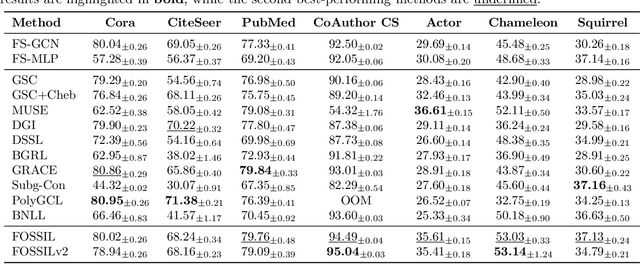
Self-supervised learning has become a key method for training deep learning models when labeled data is scarce or unavailable. While graph machine learning holds great promise across various domains, the design of effective pretext tasks for self-supervised graph representation learning remains challenging. Contrastive learning, a popular approach in graph self-supervised learning, leverages positive and negative pairs to compute a contrastive loss function. However, current graph contrastive learning methods often struggle to fully use structural patterns and node similarities. To address these issues, we present a new method called Fused Gromov Wasserstein Subgraph Contrastive Learning (FOSSIL). Our model integrates node-level and subgraph-level contrastive learning, seamlessly combining a standard node-level contrastive loss with the Fused Gromov-Wasserstein distance. This combination helps our method capture both node features and graph structure together. Importantly, our approach works well with both homophilic and heterophilic graphs and can dynamically create views for generating positive and negative pairs. Through extensive experiments on benchmark graph datasets, we show that FOSSIL outperforms or achieves competitive performance compared to current state-of-the-art methods.
Gaussian Mixture Models Based Augmentation Enhances GNN Generalization
Nov 13, 2024



Graph Neural Networks (GNNs) have shown great promise in tasks like node and graph classification, but they often struggle to generalize, particularly to unseen or out-of-distribution (OOD) data. These challenges are exacerbated when training data is limited in size or diversity. To address these issues, we introduce a theoretical framework using Rademacher complexity to compute a regret bound on the generalization error and then characterize the effect of data augmentation. This framework informs the design of GMM-GDA, an efficient graph data augmentation (GDA) algorithm leveraging the capability of Gaussian Mixture Models (GMMs) to approximate any distribution. Our approach not only outperforms existing augmentation techniques in terms of generalization but also offers improved time complexity, making it highly suitable for real-world applications.
Post-Hoc Robustness Enhancement in Graph Neural Networks with Conditional Random Fields
Nov 08, 2024



Graph Neural Networks (GNNs), which are nowadays the benchmark approach in graph representation learning, have been shown to be vulnerable to adversarial attacks, raising concerns about their real-world applicability. While existing defense techniques primarily concentrate on the training phase of GNNs, involving adjustments to message passing architectures or pre-processing methods, there is a noticeable gap in methods focusing on increasing robustness during inference. In this context, this study introduces RobustCRF, a post-hoc approach aiming to enhance the robustness of GNNs at the inference stage. Our proposed method, founded on statistical relational learning using a Conditional Random Field, is model-agnostic and does not require prior knowledge about the underlying model architecture. We validate the efficacy of this approach across various models, leveraging benchmark node classification datasets.