 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePercENT: Scaling Disentangled Representation Learning Beyond Two Modalities
Jun 03, 2026To leverage the full potential of multimodal data, we need representations that go beyond the state-of-the-art alignment and fusion approaches and exploit all cross-modal interactions without sacrificing modality-specific information. Learning disentangled representations is a principled way to identify these underlying shared and unique factors that are hidden in observational data. However, while multimodal disentanglement is a compelling paradigm, existing methods are largely confined to the two-modality regime due to its inherent scalability bottleneck. To address this, we propose RePercENT, a self-supervised framework designed to surpass these limitations and unlocks scalable pairwise disentanglement beyond two modalities. Through a multimodal `plug-and-play' architecture, our approach operates directly on pre-extracted embeddings, eliminating the need for extensive joint pre-training while making no assumptions regarding the underlying modalities or foundation model backbones. Moreover, we introduce a joint optimization objective for simultaneously deriving the shared and unique components, and provide formal theoretical guarantees that characterize the optimality of our solution. Across diverse modalities and tasks, RePercENT successfully recovers disentangled components while maintaining competitive performance and significantly reducing computational complexity.
Graph Signal Separation with Learnable Spectral Filters
Apr 27, 2026Separating multiple graph signals from a single observed mixture is an inherently ill-posed problem that traditionally relies on restrictive and handcrafted priors. This letter addresses this challenge by proposing an unsupervised learnable spectral filtering framework. Our approach reconstructs latent components by passing a fixed random input through learnable spectral filters, operating within the low-frequency eigenspace of each source-specific graph Laplacian. The architecture implicitly biases the recovered signals toward smooth patterns by confining reconstruction to these low-frequency subspaces. This acts as a structural prior, establishing a principled bridge between classical graph spectral analysis and modern neural decomposition. Numerical experiments confirm that this framework successfully isolates individual sources using solely the observed mixture and the underlying graph topology.
Causality-Driven Disentangled Representation Learning in Multiplex Graphs
Mar 25, 2026Learning representations from multiplex graphs, i.e., multi-layer networks where nodes interact through multiple relation types, is challenging due to the entanglement of shared (common) and layer-specific (private) information, which limits generalization and interpretability. In this work, we introduce a causal inference-based framework that disentangles common and private components in a self-supervised manner. CaDeM jointly (i) aligns shared embeddings across layers, (ii) enforces private embeddings to capture layer-specific signals, and (iii) applies backdoor adjustment to ensure that the common embeddings capture only global information while being separated from the private representations. Experiments on synthetic and real-world datasets demonstrate consistent improvements over existing baselines, highlighting the effectiveness of our approach for robust and interpretable multiplex graph representation learning.
ODySSeI: An Open-Source End-to-End Framework for Automated Detection, Segmentation, and Severity Estimation of Lesions in Invasive Coronary Angiography Images
Mar 20, 2026Invasive Coronary Angiography (ICA) is the clinical gold standard for the assessment of coronary artery disease. However, its interpretation remains subjective and prone to intra- and inter-operator variability. In this work, we introduce ODySSeI: an Open-source end-to-end framework for automated Detection, Segmentation, and Severity estimation of lesions in ICA images. ODySSeI integrates deep learning-based lesion detection and lesion segmentation models trained using a novel Pyramidal Augmentation Scheme (PAS) to enhance robustness and real-time performance across diverse patient cohorts (2149 patients from Europe, North America, and Asia). Furthermore, we propose a quantitative coronary angiography-free Lesion Severity Estimation (LSE) technique that directly computes the Minimum Lumen Diameter (MLD) and diameter stenosis from the predicted lesion geometry. Extensive evaluation on both in-distribution and out-of-distribution clinical datasets demonstrates ODySSeI's strong generalizability. Our PAS yields large performance gains in highly complex tasks as compared to relatively simpler ones, notably, a 2.5-fold increase in lesion detection performance versus a 1-3\% increase in lesion segmentation performance over their respective baselines. Our LSE technique achieves high accuracy, with predicted MLD values differing by only $\pm$ 2-3 pixels from the corresponding ground truths. On average, ODySSeI processes a raw ICA image within only a few seconds on a CPU and in a fraction of a second on a GPU and is available as a plug-and-play web interface at swisscardia.epfl.ch. Overall, this work establishes ODySSeI as a comprehensive and open-source framework which supports automated, reproducible, and scalable ICA analysis for real-time clinical decision-making.
CM-UNet: A Self-Supervised Learning-Based Model for Coronary Artery Segmentation in X-Ray Angiography
Jul 22, 2025Accurate segmentation of coronary arteries remains a significant challenge in clinical practice, hindering the ability to effectively diagnose and manage coronary artery disease. The lack of large, annotated datasets for model training exacerbates this issue, limiting the development of automated tools that could assist radiologists. To address this, we introduce CM-UNet, which leverages self-supervised pre-training on unannotated datasets and transfer learning on limited annotated data, enabling accurate disease detection while minimizing the need for extensive manual annotations. Fine-tuning CM-UNet with only 18 annotated images instead of 500 resulted in a 15.2% decrease in Dice score, compared to a 46.5% drop in baseline models without pre-training. This demonstrates that self-supervised learning can enhance segmentation performance and reduce dependence on large datasets. This is one of the first studies to highlight the importance of self-supervised learning in improving coronary artery segmentation from X-ray angiography, with potential implications for advancing diagnostic accuracy in clinical practice. By enhancing segmentation accuracy in X-ray angiography images, the proposed approach aims to improve clinical workflows, reduce radiologists' workload, and accelerate disease detection, ultimately contributing to better patient outcomes. The source code is publicly available at https://github.com/CamilleChallier/Contrastive-Masked-UNet.
Revisiting Automatic Data Curation for Vision Foundation Models in Digital Pathology
Mar 24, 2025Vision foundation models (FMs) are accelerating the development of digital pathology algorithms and transforming biomedical research. These models learn, in a self-supervised manner, to represent histological features in highly heterogeneous tiles extracted from whole-slide images (WSIs) of real-world patient samples. The performance of these FMs is significantly influenced by the size, diversity, and balance of the pre-training data. However, data selection has been primarily guided by expert knowledge at the WSI level, focusing on factors such as disease classification and tissue types, while largely overlooking the granular details available at the tile level. In this paper, we investigate the potential of unsupervised automatic data curation at the tile-level, taking into account 350 million tiles. Specifically, we apply hierarchical clustering trees to pre-extracted tile embeddings, allowing us to sample balanced datasets uniformly across the embedding space of the pretrained FM. We further identify these datasets are subject to a trade-off between size and balance, potentially compromising the quality of representations learned by FMs, and propose tailored batch sampling strategies to mitigate this effect. We demonstrate the effectiveness of our method through improved performance on a diverse range of clinically relevant downstream tasks.
COSMOS: Continuous Simplicial Neural Networks
Mar 17, 2025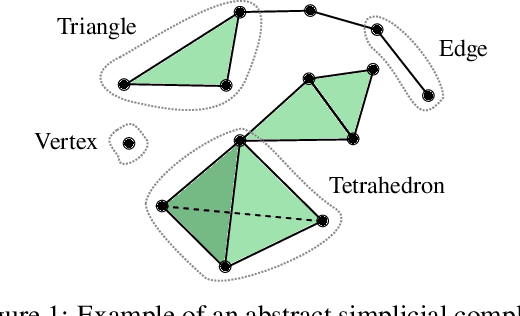
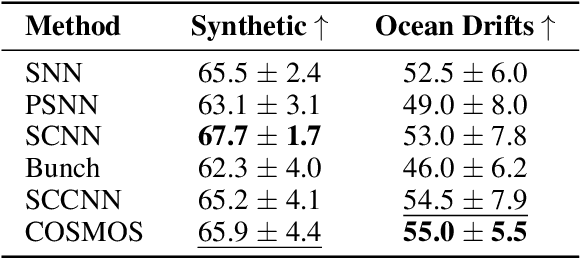


Simplicial complexes provide a powerful framework for modeling high-order interactions in structured data, making them particularly suitable for applications such as trajectory prediction and mesh processing. However, existing simplicial neural networks (SNNs), whether convolutional or attention-based, rely primarily on discrete filtering techniques, which can be restrictive. In contrast, partial differential equations (PDEs) on simplicial complexes offer a principled approach to capture continuous dynamics in such structures. In this work, we introduce COntinuous SiMplicial neural netwOrkS (COSMOS), a novel SNN architecture derived from PDEs on simplicial complexes. We provide theoretical and experimental justifications of COSMOS's stability under simplicial perturbations. Furthermore, we investigate the over-smoothing phenomenon, a common issue in geometric deep learning, demonstrating that COSMOS offers better control over this effect than discrete SNNs. Our experiments on real-world datasets of ocean trajectory prediction and regression on partial deformable shapes demonstrate that COSMOS achieves competitive performance compared to state-of-the-art SNNs in complex and noisy environments.
DeFoG: Discrete Flow Matching for Graph Generation
Oct 05, 2024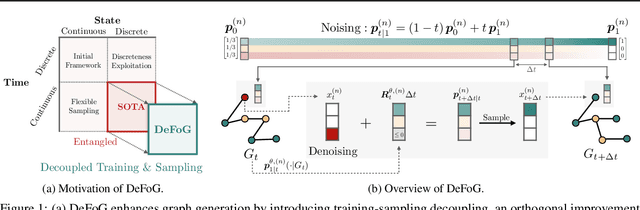


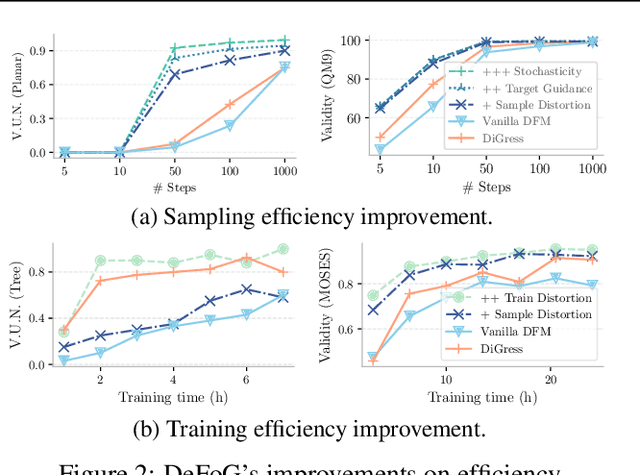
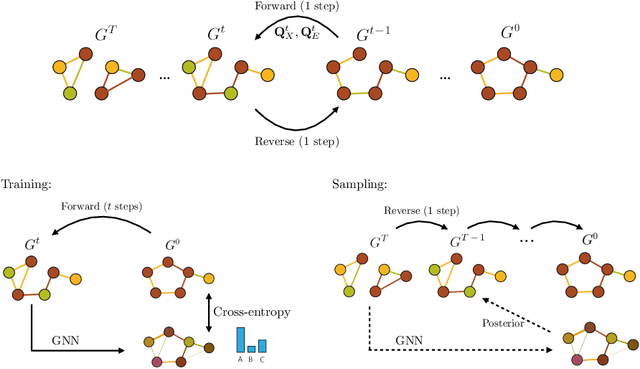
Graph generation is fundamental in diverse scientific applications, due to its ability to reveal the underlying distribution of complex data, and eventually generate new, realistic data points. Despite the success of diffusion models in this domain, those face limitations in sampling efficiency and flexibility, stemming from the tight coupling between the training and sampling stages. To address this, we propose DeFoG, a novel framework using discrete flow matching for graph generation. DeFoG employs a flow-based approach that features an efficient linear interpolation noising process and a flexible denoising process based on a continuous-time Markov chain formulation. We leverage an expressive graph transformer and ensure desirable node permutation properties to respect graph symmetry. Crucially, our framework enables a disentangled design of the training and sampling stages, enabling more effective and efficient optimization of model performance. We navigate this design space by introducing several algorithmic improvements that boost the model performance, consistently surpassing existing diffusion models. We also theoretically demonstrate that, for general discrete data, discrete flow models can faithfully replicate the ground truth distribution - a result that naturally extends to graph data and reinforces DeFoG's foundations. Extensive experiments show that DeFoG achieves state-of-the-art results on synthetic and molecular datasets, improving both training and sampling efficiency over diffusion models, and excels in conditional generation on a digital pathology dataset.
Generative Modelling of Structurally Constrained Graphs
Jun 25, 2024


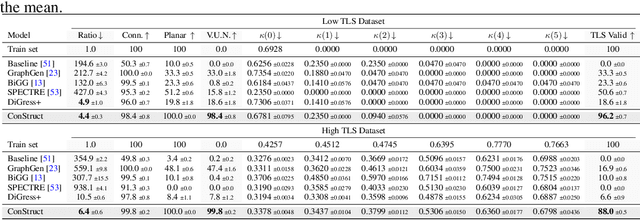
Graph diffusion models have emerged as state-of-the-art techniques in graph generation, yet integrating domain knowledge into these models remains challenging. Domain knowledge is particularly important in real-world scenarios, where invalid generated graphs hinder deployment in practical applications. Unconstrained and conditioned graph generative models fail to guarantee such domain-specific structural properties. We present ConStruct, a novel framework that allows for hard-constraining graph diffusion models to incorporate specific properties, such as planarity or acyclicity. Our approach ensures that the sampled graphs remain within the domain of graphs that verify the specified property throughout the entire trajectory in both the forward and reverse processes. This is achieved by introducing a specific edge-absorbing noise model and a new projector operator. ConStruct demonstrates versatility across several structural and edge-deletion invariant constraints and achieves state-of-the-art performance for both synthetic benchmarks and attributed real-world datasets. For example, by leveraging planarity in digital pathology graph datasets, the proposed method outperforms existing baselines and enhances generated data validity by up to 71.1 percentage points.
Tertiary Lymphoid Structures Generation through Graph-based Diffusion
Oct 10, 2023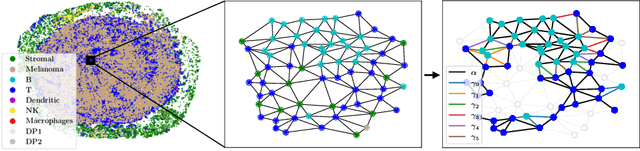


Graph-based representation approaches have been proven to be successful in the analysis of biomedical data, due to their capability of capturing intricate dependencies between biological entities, such as the spatial organization of different cell types in a tumor tissue. However, to further enhance our understanding of the underlying governing biological mechanisms, it is important to accurately capture the actual distributions of such complex data. Graph-based deep generative models are specifically tailored to accomplish that. In this work, we leverage state-of-the-art graph-based diffusion models to generate biologically meaningful cell-graphs. In particular, we show that the adopted graph diffusion model is able to accurately learn the distribution of cells in terms of their tertiary lymphoid structures (TLS) content, a well-established biomarker for evaluating the cancer progression in oncology research. Additionally, we further illustrate the utility of the learned generative models for data augmentation in a TLS classification task. To the best of our knowledge, this is the first work that leverages the power of graph diffusion models in generating meaningful biological cell structures.