 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMOIR: Lifelong Model Editing with Minimal Overwrite and Informed Retention for LLMs
Jun 09, 2025Language models deployed in real-world systems often require post-hoc updates to incorporate new or corrected knowledge. However, editing such models efficiently and reliably - without retraining or forgetting previous information - remains a major challenge. Existing methods for lifelong model editing either compromise generalization, interfere with past edits, or fail to scale to long editing sequences. We propose MEMOIR, a novel scalable framework that injects knowledge through a residual memory, i.e., a dedicated parameter module, while preserving the core capabilities of the pre-trained model. By sparsifying input activations through sample-dependent masks, MEMOIR confines each edit to a distinct subset of the memory parameters, minimizing interference among edits. At inference, it identifies relevant edits by comparing the sparse activation patterns of new queries to those stored during editing. This enables generalization to rephrased queries by activating only the relevant knowledge while suppressing unnecessary memory activation for unrelated prompts. Experiments on question answering, hallucination correction, and out-of-distribution generalization benchmarks across LLaMA-3 and Mistral demonstrate that MEMOIR achieves state-of-the-art performance across reliability, generalization, and locality metrics, scaling to thousands of sequential edits with minimal forgetting.
Apply Hierarchical-Chain-of-Generation to Complex Attributes Text-to-3D Generation
May 07, 2025Recent text-to-3D models can render high-quality assets, yet they still stumble on objects with complex attributes. The key obstacles are: (1) existing text-to-3D approaches typically lift text-to-image models to extract semantics via text encoders, while the text encoder exhibits limited comprehension ability for long descriptions, leading to deviated cross-attention focus, subsequently wrong attribute binding in generated results. (2) Occluded object parts demand a disciplined generation order and explicit part disentanglement. Though some works introduce manual efforts to alleviate the above issues, their quality is unstable and highly reliant on manual information. To tackle above problems, we propose a automated method Hierarchical-Chain-of-Generation (HCoG). It leverages a large language model to decompose the long description into blocks representing different object parts, and orders them from inside out according to occlusions, forming a hierarchical chain. Within each block we first coarsely create components, then precisely bind attributes via target-region localization and corresponding 3D Gaussian kernel optimization. Between blocks, we introduce Gaussian Extension and Label Elimination to seamlessly generate new parts by extending new Gaussian kernels, re-assigning semantic labels, and eliminating unnecessary kernels, ensuring that only relevant parts are added without disrupting previously optimized parts. Experiments confirm that HCoG yields structurally coherent, attribute-faithful 3D objects with complex attributes. The code is available at https://github.com/Wakals/GASCOL .
DeFoG: Discrete Flow Matching for Graph Generation
Oct 05, 2024


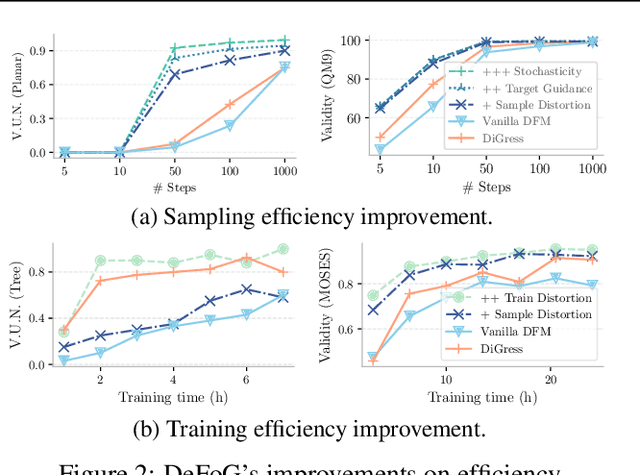
Graph generation is fundamental in diverse scientific applications, due to its ability to reveal the underlying distribution of complex data, and eventually generate new, realistic data points. Despite the success of diffusion models in this domain, those face limitations in sampling efficiency and flexibility, stemming from the tight coupling between the training and sampling stages. To address this, we propose DeFoG, a novel framework using discrete flow matching for graph generation. DeFoG employs a flow-based approach that features an efficient linear interpolation noising process and a flexible denoising process based on a continuous-time Markov chain formulation. We leverage an expressive graph transformer and ensure desirable node permutation properties to respect graph symmetry. Crucially, our framework enables a disentangled design of the training and sampling stages, enabling more effective and efficient optimization of model performance. We navigate this design space by introducing several algorithmic improvements that boost the model performance, consistently surpassing existing diffusion models. We also theoretically demonstrate that, for general discrete data, discrete flow models can faithfully replicate the ground truth distribution - a result that naturally extends to graph data and reinforces DeFoG's foundations. Extensive experiments show that DeFoG achieves state-of-the-art results on synthetic and molecular datasets, improving both training and sampling efficiency over diffusion models, and excels in conditional generation on a digital pathology dataset.
Diff-BGM: A Diffusion Model for Video Background Music Generation
May 20, 2024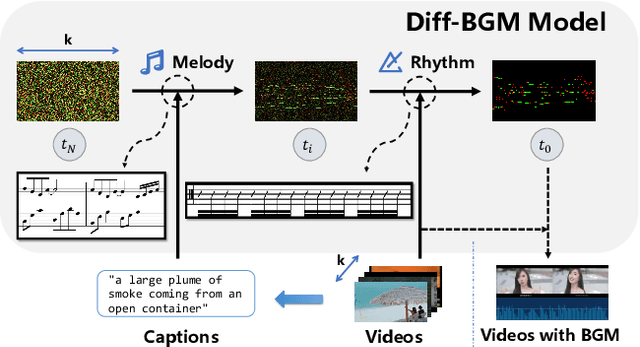

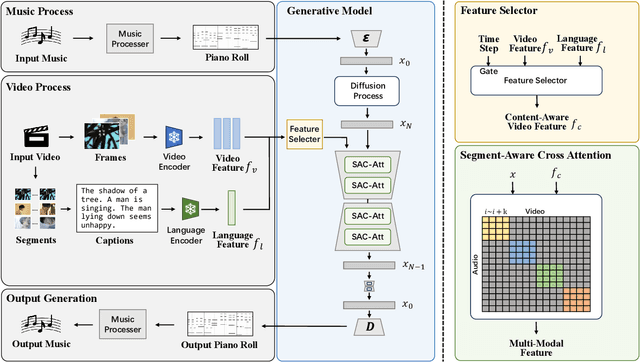

When editing a video, a piece of attractive background music is indispensable. However, video background music generation tasks face several challenges, for example, the lack of suitable training datasets, and the difficulties in flexibly controlling the music generation process and sequentially aligning the video and music. In this work, we first propose a high-quality music-video dataset BGM909 with detailed annotation and shot detection to provide multi-modal information about the video and music. We then present evaluation metrics to assess music quality, including music diversity and alignment between music and video with retrieval precision metrics. Finally, we propose the Diff-BGM framework to automatically generate the background music for a given video, which uses different signals to control different aspects of the music during the generation process, i.e., uses dynamic video features to control music rhythm and semantic features to control the melody and atmosphere. We propose to align the video and music sequentially by introducing a segment-aware cross-attention layer. Experiments verify the effectiveness of our proposed method. The code and models are available at https://github.com/sizhelee/Diff-BGM.
Sparse Training of Discrete Diffusion Models for Graph Generation
Nov 03, 2023



Generative models for graphs often encounter scalability challenges due to the inherent need to predict interactions for every node pair. Despite the sparsity often exhibited by real-world graphs, the unpredictable sparsity patterns of their adjacency matrices, stemming from their unordered nature, leads to quadratic computational complexity. In this work, we introduce SparseDiff, a denoising diffusion model for graph generation that is able to exploit sparsity during its training phase. At the core of SparseDiff is a message-passing neural network tailored to predict only a subset of edges during each forward pass. When combined with a sparsity-preserving noise model, this model can efficiently work with edge lists representations of graphs, paving the way for scalability to much larger structures. During the sampling phase, SparseDiff iteratively populates the adjacency matrix from its prior state, ensuring prediction of the full graph while controlling memory utilization. Experimental results show that SparseDiff simultaneously matches state-of-the-art in generation performance on both small and large graphs, highlighting the versatility of our method.
Class-Balancing Diffusion Models
Apr 30, 2023



Diffusion-based models have shown the merits of generating high-quality visual data while preserving better diversity in recent studies. However, such observation is only justified with curated data distribution, where the data samples are nicely pre-processed to be uniformly distributed in terms of their labels. In practice, a long-tailed data distribution appears more common and how diffusion models perform on such class-imbalanced data remains unknown. In this work, we first investigate this problem and observe significant degradation in both diversity and fidelity when the diffusion model is trained on datasets with class-imbalanced distributions. Especially in tail classes, the generations largely lose diversity and we observe severe mode-collapse issues. To tackle this problem, we set from the hypothesis that the data distribution is not class-balanced, and propose Class-Balancing Diffusion Models (CBDM) that are trained with a distribution adjustment regularizer as a solution. Experiments show that images generated by CBDM exhibit higher diversity and quality in both quantitative and qualitative ways. Our method benchmarked the generation results on CIFAR100/CIFAR100LT dataset and shows outstanding performance on the downstream recognition task.