 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract-Custom: Customized Human Object Interaction Image Generation
Aug 28, 2025Compositional Customized Image Generation aims to customize multiple target concepts within generation content, which has gained attention for its wild application. Existing approaches mainly concentrate on the target entity's appearance preservation, while neglecting the fine-grained interaction control among target entities. To enable the model of such interaction control capability, we focus on human object interaction scenario and propose the task of Customized Human Object Interaction Image Generation(CHOI), which simultaneously requires identity preservation for target human object and the interaction semantic control between them. Two primary challenges exist for CHOI:(1)simultaneous identity preservation and interaction control demands require the model to decompose the human object into self-contained identity features and pose-oriented interaction features, while the current HOI image datasets fail to provide ideal samples for such feature-decomposed learning.(2)inappropriate spatial configuration between human and object may lead to the lack of desired interaction semantics. To tackle it, we first process a large-scale dataset, where each sample encompasses the same pair of human object involving different interactive poses. Then we design a two-stage model Interact-Custom, which firstly explicitly models the spatial configuration by generating a foreground mask depicting the interaction behavior, then under the guidance of this mask, we generate the target human object interacting while preserving their identities features. Furthermore, if the background image and the union location of where the target human object should appear are provided by users, Interact-Custom also provides the optional functionality to specify them, offering high content controllability. Extensive experiments on our tailored metrics for CHOI task demonstrate the effectiveness of our approach.
Investigating Domain Gaps for Indoor 3D Object Detection
Aug 24, 2025As a fundamental task for indoor scene understanding, 3D object detection has been extensively studied, and the accuracy on indoor point cloud data has been substantially improved. However, existing researches have been conducted on limited datasets, where the training and testing sets share the same distribution. In this paper, we consider the task of adapting indoor 3D object detectors from one dataset to another, presenting a comprehensive benchmark with ScanNet, SUN RGB-D and 3D Front datasets, as well as our newly proposed large-scale datasets ProcTHOR-OD and ProcFront generated by a 3D simulator. Since indoor point cloud datasets are collected and constructed in different ways, the object detectors are likely to overfit to specific factors within each dataset, such as point cloud quality, bounding box layout and instance features. We conduct experiments across datasets on different adaptation scenarios including synthetic-to-real adaptation, point cloud quality adaptation, layout adaptation and instance feature adaptation, analyzing the impact of different domain gaps on 3D object detectors. We also introduce several approaches to improve adaptation performances, providing baselines for domain adaptive indoor 3D object detection, hoping that future works may propose detectors with stronger generalization ability across domains. Our project homepage can be found in https://jeremyzhao1998.github.io/DAVoteNet-release/.
TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
Aug 07, 2025Dynamic Scene Graph Generation (DSGG) aims to create a scene graph for each video frame by detecting objects and predicting their relationships. Weakly Supervised DSGG (WS-DSGG) reduces annotation workload by using an unlocalized scene graph from a single frame per video for training. Existing WS-DSGG methods depend on an off-the-shelf external object detector to generate pseudo labels for subsequent DSGG training. However, detectors trained on static, object-centric images struggle in dynamic, relation-aware scenarios required for DSGG, leading to inaccurate localization and low-confidence proposals. To address the challenges posed by external object detectors in WS-DSGG, we propose a Temporal-enhanced Relation-aware Knowledge Transferring (TRKT) method, which leverages knowledge to enhance detection in relation-aware dynamic scenarios. TRKT is built on two key components:(1)Relation-aware knowledge mining: we first employ object and relation class decoders that generate category-specific attention maps to highlight both object regions and interactive areas. Then we propose an Inter-frame Attention Augmentation strategy that exploits optical flow for neighboring frames to enhance the attention maps, making them motion-aware and robust to motion blur. This step yields relation- and motion-aware knowledge mining for WS-DSGG. (2) we introduce a Dual-stream Fusion Module that integrates category-specific attention maps into external detections to refine object localization and boost confidence scores for object proposals. Extensive experiments demonstrate that TRKT achieves state-of-the-art performance on Action Genome dataset. Our code is avaliable at https://github.com/XZPKU/TRKT.git.
Hierarchical Sub-action Tree for Continuous Sign Language Recognition
Jun 26, 2025Continuous sign language recognition (CSLR) aims to transcribe untrimmed videos into glosses, which are typically textual words. Recent studies indicate that the lack of large datasets and precise annotations has become a bottleneck for CSLR due to insufficient training data. To address this, some works have developed cross-modal solutions to align visual and textual modalities. However, they typically extract textual features from glosses without fully utilizing their knowledge. In this paper, we propose the Hierarchical Sub-action Tree (HST), termed HST-CSLR, to efficiently combine gloss knowledge with visual representation learning. By incorporating gloss-specific knowledge from large language models, our approach leverages textual information more effectively. Specifically, we construct an HST for textual information representation, aligning visual and textual modalities step-by-step and benefiting from the tree structure to reduce computational complexity. Additionally, we impose a contrastive alignment enhancement to bridge the gap between the two modalities. Experiments on four datasets (PHOENIX-2014, PHOENIX-2014T, CSL-Daily, and Sign Language Gesture) demonstrate the effectiveness of our HST-CSLR.
Apply Hierarchical-Chain-of-Generation to Complex Attributes Text-to-3D Generation
May 07, 2025Recent text-to-3D models can render high-quality assets, yet they still stumble on objects with complex attributes. The key obstacles are: (1) existing text-to-3D approaches typically lift text-to-image models to extract semantics via text encoders, while the text encoder exhibits limited comprehension ability for long descriptions, leading to deviated cross-attention focus, subsequently wrong attribute binding in generated results. (2) Occluded object parts demand a disciplined generation order and explicit part disentanglement. Though some works introduce manual efforts to alleviate the above issues, their quality is unstable and highly reliant on manual information. To tackle above problems, we propose a automated method Hierarchical-Chain-of-Generation (HCoG). It leverages a large language model to decompose the long description into blocks representing different object parts, and orders them from inside out according to occlusions, forming a hierarchical chain. Within each block we first coarsely create components, then precisely bind attributes via target-region localization and corresponding 3D Gaussian kernel optimization. Between blocks, we introduce Gaussian Extension and Label Elimination to seamlessly generate new parts by extending new Gaussian kernels, re-assigning semantic labels, and eliminating unnecessary kernels, ensuring that only relevant parts are added without disrupting previously optimized parts. Experiments confirm that HCoG yields structurally coherent, attribute-faithful 3D objects with complex attributes. The code is available at https://github.com/Wakals/GASCOL .
Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Nov 26, 2024Tokenization techniques such as Byte-Pair Encoding (BPE) and Byte-Level BPE (BBPE) have significantly improved the computational efficiency and vocabulary representation stability of large language models (LLMs) by segmenting text into tokens. However, this segmentation often obscures the internal character structures and sequences within tokens, preventing models from fully learning these intricate details during training. Consequently, LLMs struggle to comprehend the character compositions and positional relationships within tokens, especially when fine-tuned on downstream tasks with limited data. In this paper, we introduce Token Internal Position Awareness (TIPA), a novel approach that enhances LLMs' understanding of internal token structures by training them on reverse character prediction tasks using the tokenizer's own vocabulary. This method enables models to effectively learn and generalize character positions and internal structures. Experimental results demonstrate that LLMs trained with TIPA outperform baseline models in predicting character positions at the token level. Furthermore, when applied to the downstream task of Chinese Spelling Correction (CSC), TIPA not only accelerates model convergence but also significantly improves task performance.
3D Vision and Language Pretraining with Large-Scale Synthetic Data
Jul 08, 2024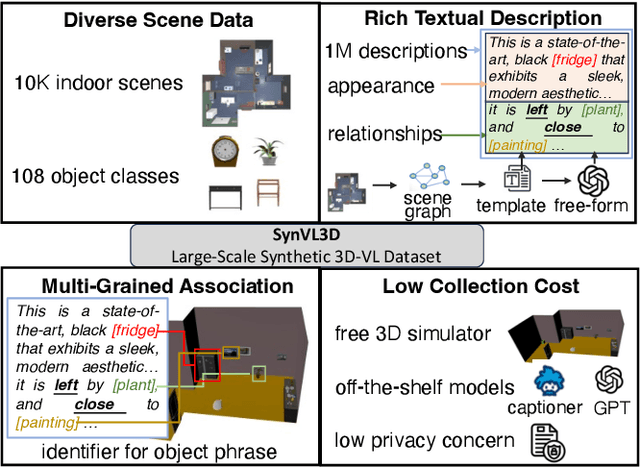
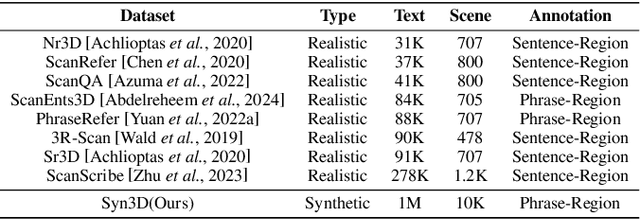
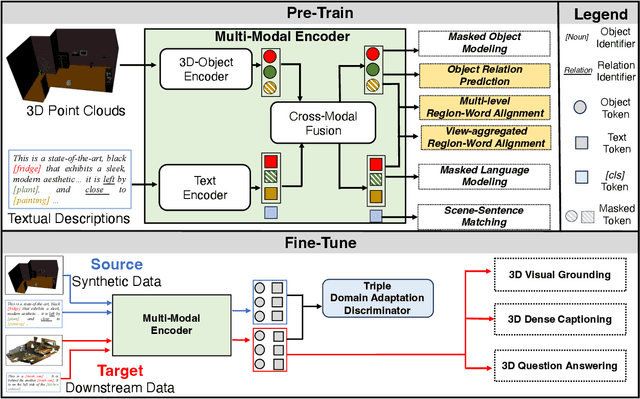
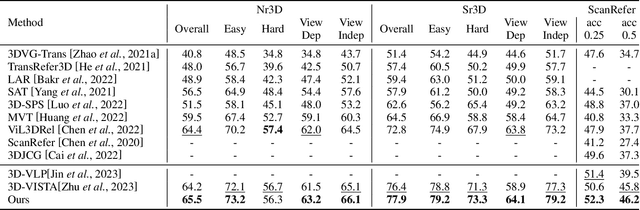
3D Vision-Language Pre-training (3D-VLP) aims to provide a pre-train model which can bridge 3D scenes with natural language, which is an important technique for embodied intelligence. However, current 3D-VLP datasets are hindered by limited scene-level diversity and insufficient fine-grained annotations (only 1.2K scenes and 280K textual annotations in ScanScribe), primarily due to the labor-intensive of collecting and annotating 3D scenes. To overcome these obstacles, we construct SynVL3D, a comprehensive synthetic scene-text corpus with 10K indoor scenes and 1M descriptions at object, view, and room levels, which has the advantages of diverse scene data, rich textual descriptions, multi-grained 3D-text associations, and low collection cost. Utilizing the rich annotations in SynVL3D, we pre-train a simple and unified Transformer for aligning 3D and language with multi-grained pretraining tasks. Moreover, we propose a synthetic-to-real domain adaptation in downstream task fine-tuning process to address the domain shift. Through extensive experiments, we verify the effectiveness of our model design by achieving state-of-the-art performance on downstream tasks including visual grounding, dense captioning, and question answering.
DFC: Deep Feature Consistency for Robust Point Cloud Registration
Nov 16, 2021



How to extract significant point cloud features and estimate the pose between them remains a challenging question, due to the inherent lack of structure and ambiguous order permutation of point clouds. Despite significant improvements in applying deep learning-based methods for most 3D computer vision tasks, such as object classification, object segmentation and point cloud registration, the consistency between features is still not attractive in existing learning-based pipelines. In this paper, we present a novel learning-based alignment network for complex alignment scenes, titled deep feature consistency and consisting of three main modules: a multiscale graph feature merging network for converting the geometric correspondence set into high-dimensional features, a correspondence weighting module for constructing multiple candidate inlier subsets, and a Procrustes approach named deep feature matching for giving a closed-form solution to estimate the relative pose. As the most important step of the deep feature matching module, the feature consistency matrix for each inlier subset is constructed to obtain its principal vectors as the inlier likelihoods of the corresponding subset. We comprehensively validate the robustness and effectiveness of our approach on both the 3DMatch dataset and the KITTI odometry dataset. For large indoor scenes, registration results on the 3DMatch dataset demonstrate that our method outperforms both the state-of-the-art traditional and learning-based methods. For KITTI outdoor scenes, our approach remains quite capable of lowering the transformation errors. We also explore its strong generalization capability over cross-datasets.