 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Adaptive High-Probability Regret Bounds for Online Convex Optimization
Jun 06, 2026We study high-probability regret bounds for online convex optimization (OCO) with strongly convex losses and establish three results that resolve open questions at the intersection of noise adaptivity, feedback structure, and constraint satisfaction. For the full-information setting with sub-Gaussian stochastic gradients, we prove a noise-adaptive high-probability regret bound in which the martingale deviation term scales with the noise level $σ$ rather than the gradient bound $G$, yielding a multiplicative improvement of $G/σ$ over the classical Azuma-Hoeffding baseline. Our analysis introduces an exponential supermartingale argument that bypasses the bounded-difference requirement of Freedman's inequality, enabling direct treatment of unbounded sub-Gaussian noise without truncation artifacts. For bandit feedback, we prove a minimax lower bound: the high-probability regret scales linearly in $\log(1/δ)$, in contrast to the $\sqrt{\log(1/δ)}$ confidence cost under full information. This constitutes a formal separation in the confidence cost of strongly convex OCO across feedback models. Regarding constrained OCO with stochastic constraints satisfying a Slater condition, we provide simultaneous high-probability guarantees for both cumulative regret and long-run constraint violation, achieving $\mathcal{O}(\sqrt{T\log(m/δ)})$ regret and $\mathcal{O}(\sqrt{T}/(ζδ) + m\sqrt{T\log(m/δ)})$ violation. Synthetic experiments corroborate all theoretical predictions.
Distilling Neuro-Symbolic Programs into 3D Multi-modal LLMs
May 31, 2026Current 3D spatial reasoning methods face a fundamental trade-off: neuro-symbolic 3D (NS3D) concept learners achieve interpretable reasoning through compositional programs but are constrained to closed-set concept vocabularies and simple programs; end-to-end 3D multi-modal LLMs (3D MLLMs) could handle complex natural language and open-vocabulary concepts but suffer from black-box reasoning without explicit spatial verification. We introduce APEIRIA, a neuro-symbolic 3D MLLM to bridge two paradigms by distilling symbolic reasoning patterns into MLLMs with natural language chain-of-thought. Our three-stage curriculum progressively builds reasoning capabilities: a) 3D perception alignment grounds object visual-geometric features to the LLM, b) CoT-SFT teaches query decomposition and stepwise verification from symbolic program traces, and c) CoT-RL extends reasoning patterns to open-set concepts and deeply nested instructions. By transferring reasoning patterns rather than concept-specific knowledge, APEIRIA preserves key NS3D virtues: transparent reasoning and modular interchangeability of planning and perception components. Evaluations on grounding, question answering, and captioning show that APEIRIA surpasses prior NS3D methods and matches state-of-the-art 3D MLLMs on 3D spatial reasoning datasets, unifying symbolic methods' systematic reasoning with MLLMs' flexibility. Code is available at https://github.com/oceanflowlab/APEIRIA.
Universal Smoothness via Bernstein Polynomials: A Constructive Approximation Approach for Activation Functions
May 04, 2026The efficacy of deep neural networks is heavily reliant on the design of non-linear activation functions, yet existing approaches often struggle to balance optimization stability with computational efficiency. While piecewise linear functions offer inference speed, they suffer from optimization instability due to non-differentiability at the origin, whereas smooth counterparts typically incur significant computational overhead through their reliance on transcendental operations. To address these limitations, this paper proposes a general smoothing framework based on constructive approximation theory and introduces the Bernstein Linear Unit (BerLU). This novel activation function utilizes Bernstein polynomials to construct a differentiable quadratic transition region that effectively eliminates singularities while maintaining a piecewise linear structure. Theoretical analysis demonstrates that the proposed method guarantees strictly continuous differentiability and a non-expansive Lipschitz constant of one, which ensures stable gradient propagation and prevents the gradient explosion problems common in deep architectures. Comprehensive empirical evaluations across representative Vision Transformer and Convolutional Neural Network architectures confirm that this approach consistently outperforms state-of-the-art baselines on standard image classification benchmarks while delivering superior computational and memory efficiency.
From Knowing to Doing Precisely: A General Self-Correction and Termination Framework for VLA models
Feb 02, 2026While vision-language-action (VLA) models for embodied agents integrate perception, reasoning, and control, they remain constrained by two critical weaknesses: first, during grasping tasks, the action tokens generated by the language model often exhibit subtle spatial deviations from the target object, resulting in grasp failures; second, they lack the ability to reliably recognize task completion, which leads to redundant actions and frequent timeout errors. To address these challenges and enhance robustness, we propose a lightweight, training-free framework, VLA-SCT. This framework operates as a self-correcting control loop, combining data-driven action refinement with conditional logic for termination. Consequently, compared to baseline approaches, our method achieves consistent improvements across all datasets in the LIBERO benchmark, significantly increasing the success rate of fine manipulation tasks and ensuring accurate task completion, thereby promoting the deployment of more reliable VLA agents in complex, unstructured environments.
Image-based Multimodal Models as Intruders: Transferable Multimodal Attacks on Video-based MLLMs
Jan 02, 2025



Video-based multimodal large language models (V-MLLMs) have shown vulnerability to adversarial examples in video-text multimodal tasks. However, the transferability of adversarial videos to unseen models--a common and practical real world scenario--remains unexplored. In this paper, we pioneer an investigation into the transferability of adversarial video samples across V-MLLMs. We find that existing adversarial attack methods face significant limitations when applied in black-box settings for V-MLLMs, which we attribute to the following shortcomings: (1) lacking generalization in perturbing video features, (2) focusing only on sparse key-frames, and (3) failing to integrate multimodal information. To address these limitations and deepen the understanding of V-MLLM vulnerabilities in black-box scenarios, we introduce the Image-to-Video MLLM (I2V-MLLM) attack. In I2V-MLLM, we utilize an image-based multimodal model (IMM) as a surrogate model to craft adversarial video samples. Multimodal interactions and temporal information are integrated to disrupt video representations within the latent space, improving adversarial transferability. In addition, a perturbation propagation technique is introduced to handle different unknown frame sampling strategies. Experimental results demonstrate that our method can generate adversarial examples that exhibit strong transferability across different V-MLLMs on multiple video-text multimodal tasks. Compared to white-box attacks on these models, our black-box attacks (using BLIP-2 as surrogate model) achieve competitive performance, with average attack success rates of 55.48% on MSVD-QA and 58.26% on MSRVTT-QA for VideoQA tasks, respectively. Our code will be released upon acceptance.
3D Vision and Language Pretraining with Large-Scale Synthetic Data
Jul 08, 2024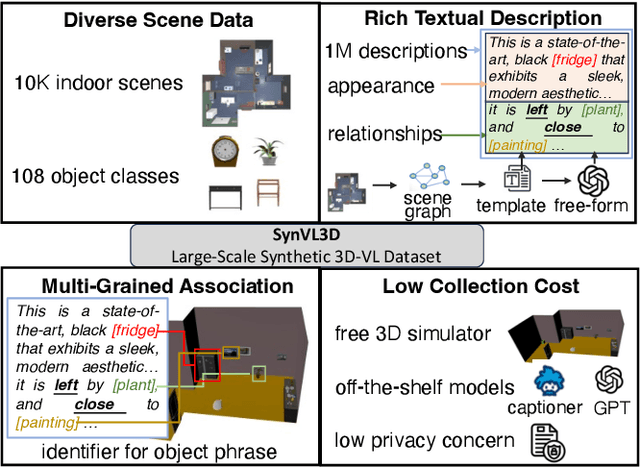
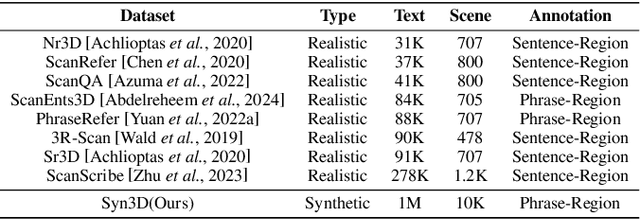
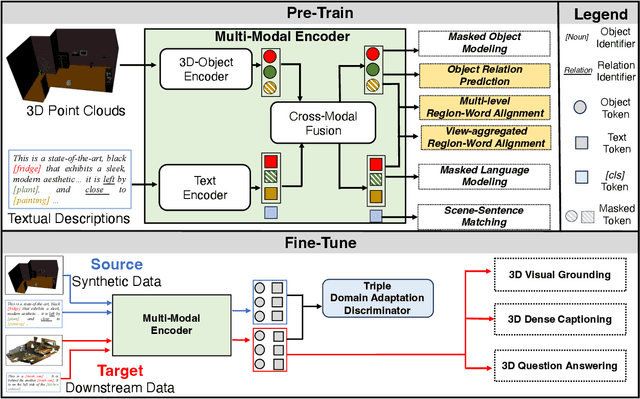
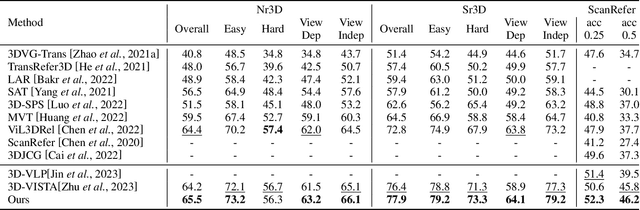
3D Vision-Language Pre-training (3D-VLP) aims to provide a pre-train model which can bridge 3D scenes with natural language, which is an important technique for embodied intelligence. However, current 3D-VLP datasets are hindered by limited scene-level diversity and insufficient fine-grained annotations (only 1.2K scenes and 280K textual annotations in ScanScribe), primarily due to the labor-intensive of collecting and annotating 3D scenes. To overcome these obstacles, we construct SynVL3D, a comprehensive synthetic scene-text corpus with 10K indoor scenes and 1M descriptions at object, view, and room levels, which has the advantages of diverse scene data, rich textual descriptions, multi-grained 3D-text associations, and low collection cost. Utilizing the rich annotations in SynVL3D, we pre-train a simple and unified Transformer for aligning 3D and language with multi-grained pretraining tasks. Moreover, we propose a synthetic-to-real domain adaptation in downstream task fine-tuning process to address the domain shift. Through extensive experiments, we verify the effectiveness of our model design by achieving state-of-the-art performance on downstream tasks including visual grounding, dense captioning, and question answering.
Bridging the Gap between 2D and 3D Visual Question Answering: A Fusion Approach for 3D VQA
Feb 24, 2024In 3D Visual Question Answering (3D VQA), the scarcity of fully annotated data and limited visual content diversity hampers the generalization to novel scenes and 3D concepts (e.g., only around 800 scenes are utilized in ScanQA and SQA dataset). Current approaches resort supplement 3D reasoning with 2D information. However, these methods face challenges: either they use top-down 2D views that introduce overly complex and sometimes question-irrelevant visual clues, or they rely on globally aggregated scene/image-level representations from 2D VLMs, losing the fine-grained vision-language correlations. To overcome these limitations, our approach utilizes question-conditional 2D view selection procedure, pinpointing semantically relevant 2D inputs for crucial visual clues. We then integrate this 2D knowledge into the 3D-VQA system via a two-branch Transformer structure. This structure, featuring a Twin-Transformer design, compactly combines 2D and 3D modalities and captures fine-grained correlations between modalities, allowing them mutually augmenting each other. Integrating proposed mechanisms above, we present BridgeQA, that offers a fresh perspective on multi-modal transformer-based architectures for 3D-VQA. Experiments validate that BridgeQA achieves state-of-the-art on 3D-VQA datasets and significantly outperforms existing solutions. Code is available at $\href{https://github.com/matthewdm0816/BridgeQA}{\text{this URL}}$.