 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Style is Worth One Code: Unlocking Code-to-Style Image Generation with Discrete Style Space
Nov 19, 2025Innovative visual stylization is a cornerstone of artistic creation, yet generating novel and consistent visual styles remains a significant challenge. Existing generative approaches typically rely on lengthy textual prompts, reference images, or parameter-efficient fine-tuning to guide style-aware image generation, but often struggle with style consistency, limited creativity, and complex style representations. In this paper, we affirm that a style is worth one numerical code by introducing the novel task, code-to-style image generation, which produces images with novel, consistent visual styles conditioned solely on a numerical style code. To date, this field has only been primarily explored by the industry (e.g., Midjourney), with no open-source research from the academic community. To fill this gap, we propose CoTyle, the first open-source method for this task. Specifically, we first train a discrete style codebook from a collection of images to extract style embeddings. These embeddings serve as conditions for a text-to-image diffusion model (T2I-DM) to generate stylistic images. Subsequently, we train an autoregressive style generator on the discrete style embeddings to model their distribution, allowing the synthesis of novel style embeddings. During inference, a numerical style code is mapped to a unique style embedding by the style generator, and this embedding guides the T2I-DM to generate images in the corresponding style. Unlike existing methods, our method offers unparalleled simplicity and diversity, unlocking a vast space of reproducible styles from minimal input. Extensive experiments validate that CoTyle effectively turns a numerical code into a style controller, demonstrating a style is worth one code.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025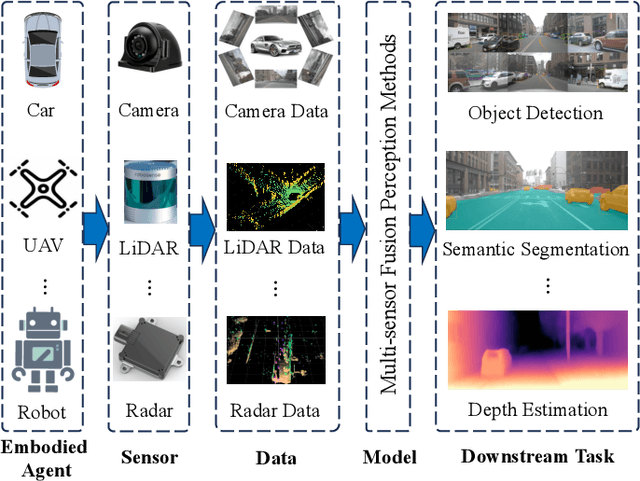
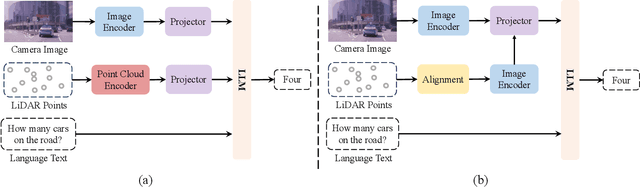
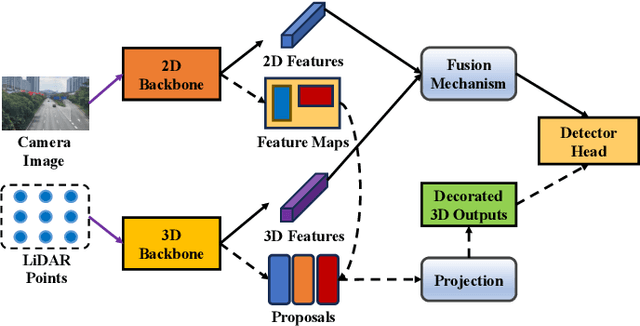
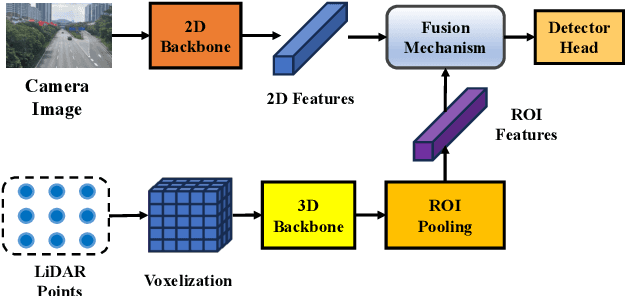
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
Omni-Dish: Photorealistic and Faithful Image Generation and Editing for Arbitrary Chinese Dishes
Apr 14, 2025



Dish images play a crucial role in the digital era, with the demand for culturally distinctive dish images continuously increasing due to the digitization of the food industry and e-commerce. In general cases, existing text-to-image generation models excel in producing high-quality images; however, they struggle to capture diverse characteristics and faithful details of specific domains, particularly Chinese dishes. To address this limitation, we propose Omni-Dish, the first text-to-image generation model specifically tailored for Chinese dishes. We develop a comprehensive dish curation pipeline, building the largest dish dataset to date. Additionally, we introduce a recaption strategy and employ a coarse-to-fine training scheme to help the model better learn fine-grained culinary nuances. During inference, we enhance the user's textual input using a pre-constructed high-quality caption library and a large language model, enabling more photorealistic and faithful image generation. Furthermore, to extend our model's capability for dish editing tasks, we propose Concept-Enhanced P2P. Based on this approach, we build a dish editing dataset and train a specialized editing model. Extensive experiments demonstrate the superiority of our methods.
FreeInv: Free Lunch for Improving DDIM Inversion
Mar 29, 2025



Naive DDIM inversion process usually suffers from a trajectory deviation issue, i.e., the latent trajectory during reconstruction deviates from the one during inversion. To alleviate this issue, previous methods either learn to mitigate the deviation or design cumbersome compensation strategy to reduce the mismatch error, exhibiting substantial time and computation cost. In this work, we present a nearly free-lunch method (named FreeInv) to address the issue more effectively and efficiently. In FreeInv, we randomly transform the latent representation and keep the transformation the same between the corresponding inversion and reconstruction time-step. It is motivated from a statistical perspective that an ensemble of DDIM inversion processes for multiple trajectories yields a smaller trajectory mismatch error on expectation. Moreover, through theoretical analysis and empirical study, we show that FreeInv performs an efficient ensemble of multiple trajectories. FreeInv can be freely integrated into existing inversion-based image and video editing techniques. Especially for inverting video sequences, it brings more significant fidelity and efficiency improvements. Comprehensive quantitative and qualitative evaluation on PIE benchmark and DAVIS dataset shows that FreeInv remarkably outperforms conventional DDIM inversion, and is competitive among previous state-of-the-art inversion methods, with superior computation efficiency.
SentiFormer: Metadata Enhanced Transformer for Image Sentiment Analysis
Feb 21, 2025As more and more internet users post images online to express their daily emotions, image sentiment analysis has attracted increasing attention. Recently, researchers generally tend to design different neural networks to extract visual features from images for sentiment analysis. Despite the significant progress, metadata, the data (e.g., text descriptions and keyword tags) for describing the image, has not been sufficiently explored in this task. In this paper, we propose a novel Metadata Enhanced Transformer for sentiment analysis (SentiFormer) to fuse multiple metadata and the corresponding image into a unified framework. Specifically, we first obtain multiple metadata of the image and unify the representations of diverse data. To adaptively learn the appropriate weights for each metadata, we then design an adaptive relevance learning module to highlight more effective information while suppressing weaker ones. Moreover, we further develop a cross-modal fusion module to fuse the adaptively learned representations and make the final prediction. Extensive experiments on three publicly available datasets demonstrate the superiority and rationality of our proposed method.
Separate Motion from Appearance: Customizing Motion via Customizing Text-to-Video Diffusion Models
Jan 28, 2025Motion customization aims to adapt the diffusion model (DM) to generate videos with the motion specified by a set of video clips with the same motion concept. To realize this goal, the adaptation of DM should be possible to model the specified motion concept, without compromising the ability to generate diverse appearances. Thus, the key to solving this problem lies in how to separate the motion concept from the appearance in the adaptation process of DM. Typical previous works explore different ways to represent and insert a motion concept into large-scale pretrained text-to-video diffusion models, e.g., learning a motion LoRA, using latent noise residuals, etc. While those methods can encode the motion concept, they also inevitably encode the appearance in the reference videos, resulting in weakened appearance generation capability. In this paper, we follow the typical way to learn a motion LoRA to encode the motion concept, but propose two novel strategies to enhance motion-appearance separation, including temporal attention purification (TAP) and appearance highway (AH). Specifically, we assume that in the temporal attention module, the pretrained Value embeddings are sufficient to serve as basic components needed by producing a new motion. Thus, in TAP, we choose only to reshape the temporal attention with motion LoRAs so that Value embeddings can be reorganized to produce a new motion. Further, in AH, we alter the starting point of each skip connection in U-Net from the output of each temporal attention module to the output of each spatial attention module. Extensive experiments demonstrate that compared to previous works, our method can generate videos with appearance more aligned with the text descriptions and motion more consistent with the reference videos.
DFC: Deep Feature Consistency for Robust Point Cloud Registration
Nov 16, 2021



How to extract significant point cloud features and estimate the pose between them remains a challenging question, due to the inherent lack of structure and ambiguous order permutation of point clouds. Despite significant improvements in applying deep learning-based methods for most 3D computer vision tasks, such as object classification, object segmentation and point cloud registration, the consistency between features is still not attractive in existing learning-based pipelines. In this paper, we present a novel learning-based alignment network for complex alignment scenes, titled deep feature consistency and consisting of three main modules: a multiscale graph feature merging network for converting the geometric correspondence set into high-dimensional features, a correspondence weighting module for constructing multiple candidate inlier subsets, and a Procrustes approach named deep feature matching for giving a closed-form solution to estimate the relative pose. As the most important step of the deep feature matching module, the feature consistency matrix for each inlier subset is constructed to obtain its principal vectors as the inlier likelihoods of the corresponding subset. We comprehensively validate the robustness and effectiveness of our approach on both the 3DMatch dataset and the KITTI odometry dataset. For large indoor scenes, registration results on the 3DMatch dataset demonstrate that our method outperforms both the state-of-the-art traditional and learning-based methods. For KITTI outdoor scenes, our approach remains quite capable of lowering the transformation errors. We also explore its strong generalization capability over cross-datasets.