 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking LLMs: Addressing Scarce Data and Bias Challenges in Mental Health
Dec 17, 2024



Large language models (LLMs) have shown promising capabilities in healthcare analysis but face several challenges like hallucinations, parroting, and bias manifestation. These challenges are exacerbated in complex, sensitive, and low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by generating in-context conversational dialogues leveraging LLMs, particularly ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues and tailored information, taking into account therapy style (empathy, reflection), contextual relevance, and false semantic change. Subsequently, the dialogues are annotated by experts, strictly adhering to the Motivational Interviewing Skills Code (MISC), focusing on both the psychological and linguistic dimensions of MI dialogues. We comprehensively evaluate the IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding of domain intricacies by modeling novel classification tasks employing several classical machine learning and current state-of-the-art transformer approaches. Finally, we discuss the effects of progressive prompting strategies and the impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our contributions provide the MI community with not only a comprehensive dataset but also valuable insights for using LLMs in empathetic text generation for conversational therapy in supervised settings.
How Fair is Your Diffusion Recommender Model?
Sep 06, 2024



Diffusion-based recommender systems have recently proven to outperform traditional generative recommendation approaches, such as variational autoencoders and generative adversarial networks. Nevertheless, the machine learning literature has raised several concerns regarding the possibility that diffusion models, while learning the distribution of data samples, may inadvertently carry information bias and lead to unfair outcomes. In light of this aspect, and considering the relevance that fairness has held in recommendations over the last few decades, we conduct one of the first fairness investigations in the literature on DiffRec, a pioneer approach in diffusion-based recommendation. First, we propose an experimental setting involving DiffRec (and its variant L-DiffRec) along with nine state-of-the-art recommendation models, two popular recommendation datasets from the fairness-aware literature, and six metrics accounting for accuracy and consumer/provider fairness. Then, we perform a twofold analysis, one assessing models' performance under accuracy and recommendation fairness separately, and the other identifying if and to what extent such metrics can strike a performance trade-off. Experimental results from both studies confirm the initial unfairness warnings but pave the way for how to address them in future research directions.
Fair Augmentation for Graph Collaborative Filtering
Aug 22, 2024
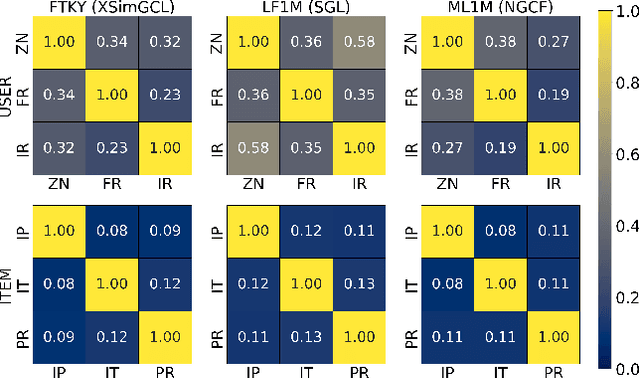


Recent developments in recommendation have harnessed the collaborative power of graph neural networks (GNNs) in learning users' preferences from user-item networks. Despite emerging regulations addressing fairness of automated systems, unfairness issues in graph collaborative filtering remain underexplored, especially from the consumer's perspective. Despite numerous contributions on consumer unfairness, only a few of these works have delved into GNNs. A notable gap exists in the formalization of the latest mitigation algorithms, as well as in their effectiveness and reliability on cutting-edge models. This paper serves as a solid response to recent research highlighting unfairness issues in graph collaborative filtering by reproducing one of the latest mitigation methods. The reproduced technique adjusts the system fairness level by learning a fair graph augmentation. Under an experimental setup based on 11 GNNs, 5 non-GNN models, and 5 real-world networks across diverse domains, our investigation reveals that fair graph augmentation is consistently effective on high-utility models and large datasets. Experiments on the transferability of the fair augmented graph open new issues for future recommendation studies. Source code: https://github.com/jackmedda/FA4GCF.
Robustness in Fairness against Edge-level Perturbations in GNN-based Recommendation
Jan 26, 2024
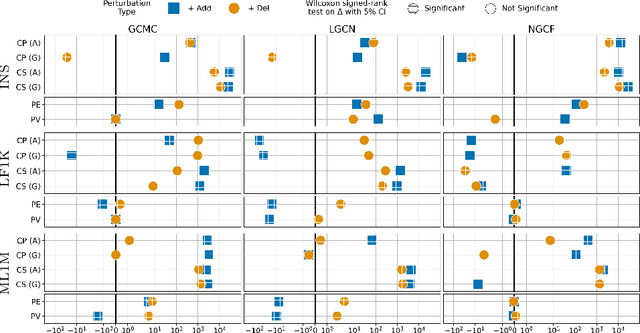

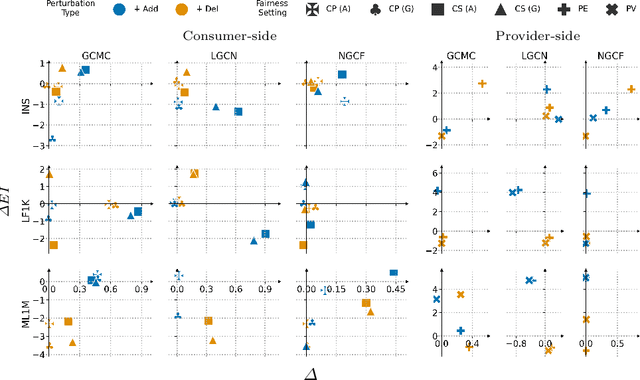
Efforts in the recommendation community are shifting from the sole emphasis on utility to considering beyond-utility factors, such as fairness and robustness. Robustness of recommendation models is typically linked to their ability to maintain the original utility when subjected to attacks. Limited research has explored the robustness of a recommendation model in terms of fairness, e.g., the parity in performance across groups, under attack scenarios. In this paper, we aim to assess the robustness of graph-based recommender systems concerning fairness, when exposed to attacks based on edge-level perturbations. To this end, we considered four different fairness operationalizations, including both consumer and provider perspectives. Experiments on three datasets shed light on the impact of perturbations on the targeted fairness notion, uncovering key shortcomings in existing evaluation protocols for robustness. As an example, we observed perturbations affect consumer fairness on a higher extent than provider fairness, with alarming unfairness for the former. Source code: https://github.com/jackmedda/CPFairRobust
Counterfactual Graph Augmentation for Consumer Unfairness Mitigation in Recommender Systems
Aug 23, 2023In recommendation literature, explainability and fairness are becoming two prominent perspectives to consider. However, prior works have mostly addressed them separately, for instance by explaining to consumers why a certain item was recommended or mitigating disparate impacts in recommendation utility. None of them has leveraged explainability techniques to inform unfairness mitigation. In this paper, we propose an approach that relies on counterfactual explanations to augment the set of user-item interactions, such that using them while inferring recommendations leads to fairer outcomes. Modeling user-item interactions as a bipartite graph, our approach augments the latter by identifying new user-item edges that not only can explain the original unfairness by design, but can also mitigate it. Experiments on two public data sets show that our approach effectively leads to a better trade-off between fairness and recommendation utility compared with state-of-the-art mitigation procedures. We further analyze the characteristics of added edges to highlight key unfairness patterns. Source code available at https://github.com/jackmedda/RS-BGExplainer/tree/cikm2023.
GNNUERS: Fairness Explanation in GNNs for Recommendation via Counterfactual Reasoning
Apr 14, 2023



In recent years, personalization research has been delving into issues of explainability and fairness. While some techniques have emerged to provide post-hoc and self-explanatory individual recommendations, there is still a lack of methods aimed at uncovering unfairness in recommendation systems beyond identifying biased user and item features. This paper proposes a new algorithm, GNNUERS, which uses counterfactuals to pinpoint user unfairness explanations in terms of user-item interactions within a bi-partite graph. By perturbing the graph topology, GNNUERS reduces differences in utility between protected and unprotected demographic groups. The paper evaluates the approach using four real-world graphs from different domains and demonstrates its ability to systematically explain user unfairness in three state-of-the-art GNN-based recommendation models. This perturbed network analysis reveals insightful patterns that confirm the nature of the unfairness underlying the explanations. The source code and preprocessed datasets are available at https://github.com/jackmedda/RS-BGExplainer
Consumer Fairness in Recommender Systems: Contextualizing Definitions and Mitigations
Feb 05, 2022
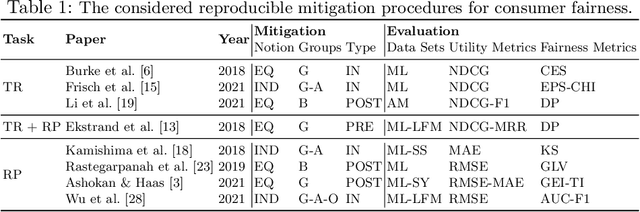

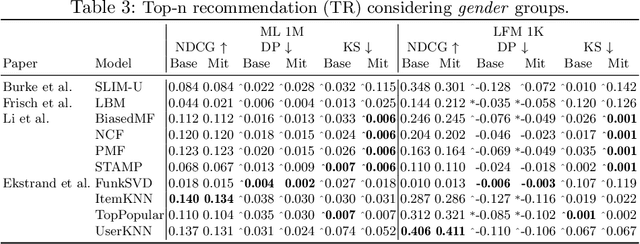
Enabling non-discrimination for end-users of recommender systems by introducing consumer fairness is a key problem, widely studied in both academia and industry. Current research has led to a variety of notions, metrics, and unfairness mitigation procedures. The evaluation of each procedure has been heterogeneous and limited to a mere comparison with models not accounting for fairness. It is hence hard to contextualize the impact of each mitigation procedure w.r.t. the others. In this paper, we conduct a systematic analysis of mitigation procedures against consumer unfairness in rating prediction and top-n recommendation tasks. To this end, we collected 15 procedures proposed in recent top-tier conferences and journals. Only 8 of them could be reproduced. Under a common evaluation protocol, based on two public data sets, we then studied the extent to which recommendation utility and consumer fairness are impacted by these procedures, the interplay between two primary fairness notions based on equity and independence, and the demographic groups harmed by the disparate impact. Our study finally highlights open challenges and future directions in this field. The source code is available at https://github.com/jackmedda/C-Fairness-RecSys.
Improving Fairness in Speaker Recognition
Apr 30, 2021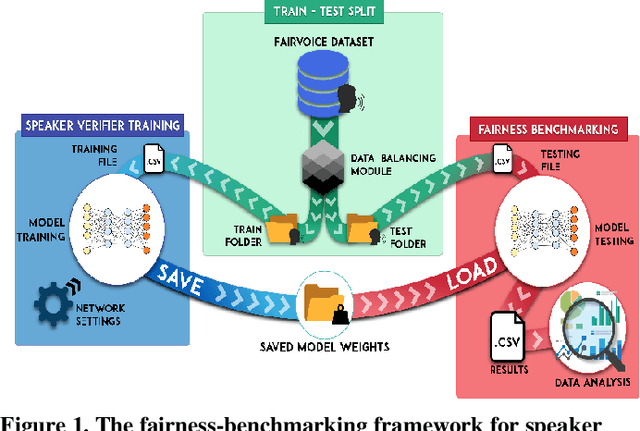
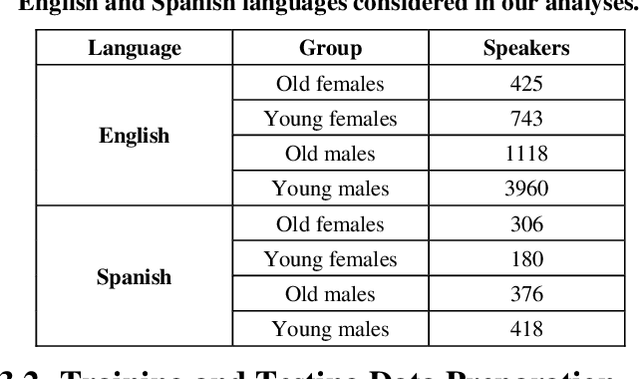
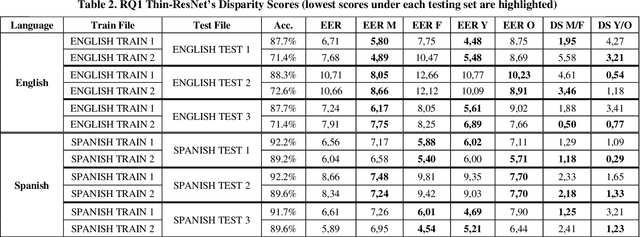

The human voice conveys unique characteristics of an individual, making voice biometrics a key technology for verifying identities in various industries. Despite the impressive progress of speaker recognition systems in terms of accuracy, a number of ethical and legal concerns has been raised, specifically relating to the fairness of such systems. In this paper, we aim to explore the disparity in performance achieved by state-of-the-art deep speaker recognition systems, when different groups of individuals characterized by a common sensitive attribute (e.g., gender) are considered. In order to mitigate the unfairness we uncovered by means of an exploratory study, we investigate whether balancing the representation of the different groups of individuals in the training set can lead to a more equal treatment of these demographic groups. Experiments on two state-of-the-art neural architectures and a large-scale public dataset show that models trained with demographically-balanced training sets exhibit a fairer behavior on different groups, while still being accurate. Our study is expected to provide a solid basis for instilling beyond-accuracy objectives (e.g., fairness) in speaker recognition.