 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Graph Shift Operator? A Spectral Answer to an Empirical Question
Feb 06, 2026Graph Neural Networks (GNNs) have established themselves as the leading models for learning on graph-structured data, generally categorized into spatial and spectral approaches. Central to these architectures is the Graph Shift Operator (GSO), a matrix representation of the graph structure used to filter node signals. However, selecting the optimal GSO, whether fixed or learnable, remains largely empirical. In this paper, we introduce a novel alignment gain metric that quantifies the geometric distortion between the input signal and label subspaces. Crucially, our theoretical analysis connects this alignment directly to generalization bounds via a spectral proxy for the Lipschitz constant. This yields a principled, computation-efficient criterion to rank and select the optimal GSO for any prediction task prior to training, eliminating the need for extensive search.
Key Principles of Graph Machine Learning: Representation, Robustness, and Generalization
Feb 01, 2026Graph Neural Networks (GNNs) have emerged as powerful tools for learning representations from structured data. Despite their growing popularity and success across various applications, GNNs encounter several challenges that limit their performance. in their generalization, robustness to adversarial perturbations, and the effectiveness of their representation learning capabilities. In this dissertation, I investigate these core aspects through three main contributions: (1) developing new representation learning techniques based on Graph Shift Operators (GSOs, aiming for enhanced performance across various contexts and applications, (2) introducing generalization-enhancing methods through graph data augmentation, and (3) developing more robust GNNs by leveraging orthonormalization techniques and noise-based defenses against adversarial attacks. By addressing these challenges, my work provides a more principled understanding of the limitations and potential of GNNs.
Enhancing Graph Classification Robustness with Singular Pooling
Oct 26, 2025Graph Neural Networks (GNNs) have achieved strong performance across a range of graph representation learning tasks, yet their adversarial robustness in graph classification remains underexplored compared to node classification. While most existing defenses focus on the message-passing component, this work investigates the overlooked role of pooling operations in shaping robustness. We present a theoretical analysis of standard flat pooling methods (sum, average and max), deriving upper bounds on their adversarial risk and identifying their vulnerabilities under different attack scenarios and graph structures. Motivated by these insights, we propose \textit{Robust Singular Pooling (RS-Pool)}, a novel pooling strategy that leverages the dominant singular vector of the node embedding matrix to construct a robust graph-level representation. We theoretically investigate the robustness of RS-Pool and interpret the resulting bound leading to improved understanding of our proposed pooling operator. While our analysis centers on Graph Convolutional Networks (GCNs), RS-Pool is model-agnostic and can be implemented efficiently via power iteration. Empirical results on real-world benchmarks show that RS-Pool provides better robustness than the considered pooling methods when subject to state-of-the-art adversarial attacks while maintaining competitive clean accuracy. Our code is publicly available at:\href{https://github.com/king/rs-pool}{https://github.com/king/rs-pool}.
Grassmannian Geometry Meets Dynamic Mode Decomposition in DMD-GEN: A New Metric for Mode Collapse in Time Series Generative Models
Dec 15, 2024



Generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) often fail to capture the full diversity of their training data, leading to mode collapse. While this issue is well-explored in image generation, it remains underinvestigated for time series data. We introduce a new definition of mode collapse specific to time series and propose a novel metric, DMD-GEN, to quantify its severity. Our metric utilizes Dynamic Mode Decomposition (DMD), a data-driven technique for identifying coherent spatiotemporal patterns, and employs Optimal Transport between DMD eigenvectors to assess discrepancies between the underlying dynamics of the original and generated data. This approach not only quantifies the preservation of essential dynamic characteristics but also provides interpretability by pinpointing which modes have collapsed. We validate DMD-GEN on both synthetic and real-world datasets using various generative models, including TimeGAN, TimeVAE, and DiffusionTS. The results demonstrate that DMD-GEN correlates well with traditional evaluation metrics for static data while offering the advantage of applicability to dynamic data. This work offers for the first time a definition of mode collapse for time series, improving understanding, and forming the basis of our tool for assessing and improving generative models in the time series domain.
Gaussian Mixture Models Based Augmentation Enhances GNN Generalization
Nov 13, 2024



Graph Neural Networks (GNNs) have shown great promise in tasks like node and graph classification, but they often struggle to generalize, particularly to unseen or out-of-distribution (OOD) data. These challenges are exacerbated when training data is limited in size or diversity. To address these issues, we introduce a theoretical framework using Rademacher complexity to compute a regret bound on the generalization error and then characterize the effect of data augmentation. This framework informs the design of GMM-GDA, an efficient graph data augmentation (GDA) algorithm leveraging the capability of Gaussian Mixture Models (GMMs) to approximate any distribution. Our approach not only outperforms existing augmentation techniques in terms of generalization but also offers improved time complexity, making it highly suitable for real-world applications.
Post-Hoc Robustness Enhancement in Graph Neural Networks with Conditional Random Fields
Nov 08, 2024Graph Neural Networks (GNNs), which are nowadays the benchmark approach in graph representation learning, have been shown to be vulnerable to adversarial attacks, raising concerns about their real-world applicability. While existing defense techniques primarily concentrate on the training phase of GNNs, involving adjustments to message passing architectures or pre-processing methods, there is a noticeable gap in methods focusing on increasing robustness during inference. In this context, this study introduces RobustCRF, a post-hoc approach aiming to enhance the robustness of GNNs at the inference stage. Our proposed method, founded on statistical relational learning using a Conditional Random Field, is model-agnostic and does not require prior knowledge about the underlying model architecture. We validate the efficacy of this approach across various models, leveraging benchmark node classification datasets.
Centrality Graph Shift Operators for Graph Neural Networks
Nov 07, 2024
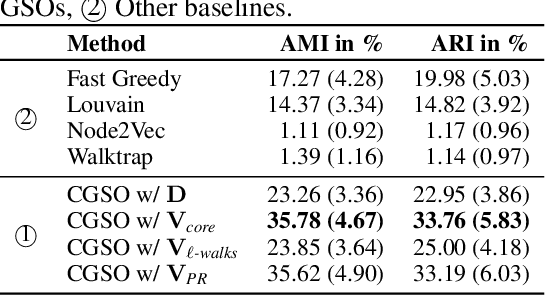
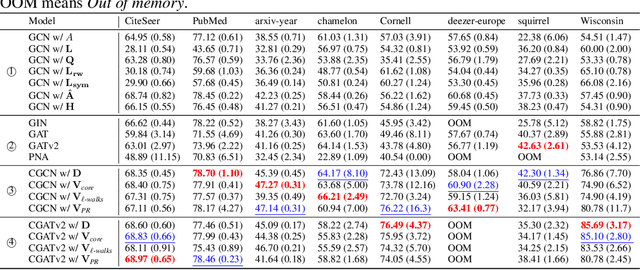
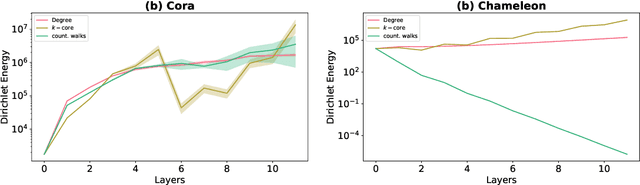
Graph Shift Operators (GSOs), such as the adjacency and graph Laplacian matrices, play a fundamental role in graph theory and graph representation learning. Traditional GSOs are typically constructed by normalizing the adjacency matrix by the degree matrix, a local centrality metric. In this work, we instead propose and study Centrality GSOs (CGSOs), which normalize adjacency matrices by global centrality metrics such as the PageRank, $k$-core or count of fixed length walks. We study spectral properties of the CGSOs, allowing us to get an understanding of their action on graph signals. We confirm this understanding by defining and running the spectral clustering algorithm based on different CGSOs on several synthetic and real-world datasets. We furthermore outline how our CGSO can act as the message passing operator in any Graph Neural Network and in particular demonstrate strong performance of a variant of the Graph Convolutional Network and Graph Attention Network using our CGSOs on several real-world benchmark datasets.
Graph Neural Networks on Discriminative Graphs of Words
Oct 27, 2024



In light of the recent success of Graph Neural Networks (GNNs) and their ability to perform inference on complex data structures, many studies apply GNNs to the task of text classification. In most previous methods, a heterogeneous graph, containing both word and document nodes, is constructed using the entire corpus and a GNN is used to classify document nodes. In this work, we explore a new Discriminative Graph of Words Graph Neural Network (DGoW-GNN) approach encapsulating both a novel discriminative graph construction and model to classify text. In our graph construction, containing only word nodes and no document nodes, we split the training corpus into disconnected subgraphs according to their labels and weight edges by the pointwise mutual information of the represented words. Our graph construction, for which we provide theoretical motivation, allows us to reformulate the task of text classification as the task of walk classification. We also propose a new model for the graph-based classification of text, which combines a GNN and a sequence model. We evaluate our approach on seven benchmark datasets and find that it is outperformed by several state-of-the-art baseline models. We analyse reasons for this performance difference and hypothesise under which conditions it is likely to change.
Atlas-Chat: Adapting Large Language Models for Low-Resource Moroccan Arabic Dialect
Sep 26, 2024We introduce Atlas-Chat, the first-ever collection of large language models specifically developed for dialectal Arabic. Focusing on Moroccan Arabic, also known as Darija, we construct our instruction dataset by consolidating existing Darija language resources, creating novel datasets both manually and synthetically, and translating English instructions with stringent quality control. Atlas-Chat-9B and 2B models, fine-tuned on the dataset, exhibit superior ability in following Darija instructions and performing standard NLP tasks. Notably, our models outperform both state-of-the-art and Arabic-specialized LLMs like LLaMa, Jais, and AceGPT, e.g., achieving a 13% performance boost over a larger 13B model on DarijaMMLU, in our newly introduced evaluation suite for Darija covering both discriminative and generative tasks. Furthermore, we perform an experimental analysis of various fine-tuning strategies and base model choices to determine optimal configurations. All our resources are publicly accessible, and we believe our work offers comprehensive design methodologies of instruction-tuning for low-resource language variants, which are often neglected in favor of data-rich languages by contemporary LLMs.
Bounding the Expected Robustness of Graph Neural Networks Subject to Node Feature Attacks
Apr 27, 2024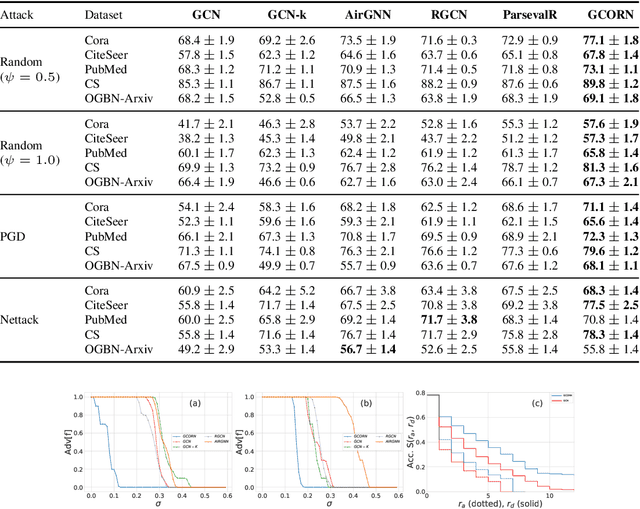
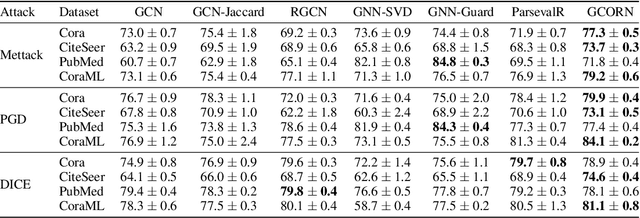


Graph Neural Networks (GNNs) have demonstrated state-of-the-art performance in various graph representation learning tasks. Recently, studies revealed their vulnerability to adversarial attacks. In this work, we theoretically define the concept of expected robustness in the context of attributed graphs and relate it to the classical definition of adversarial robustness in the graph representation learning literature. Our definition allows us to derive an upper bound of the expected robustness of Graph Convolutional Networks (GCNs) and Graph Isomorphism Networks subject to node feature attacks. Building on these findings, we connect the expected robustness of GNNs to the orthonormality of their weight matrices and consequently propose an attack-independent, more robust variant of the GCN, called the Graph Convolutional Orthonormal Robust Networks (GCORNs). We further introduce a probabilistic method to estimate the expected robustness, which allows us to evaluate the effectiveness of GCORN on several real-world datasets. Experimental experiments showed that GCORN outperforms available defense methods. Our code is publicly available at: \href{https://github.com/Sennadir/GCORN}{https://github.com/Sennadir/GCORN}.