 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek
Feb 05, 2026Large Language Models (LLMs) are commonly trained on multilingual corpora that include Greek, yet reliable evaluation benchmarks for Greek-particularly those based on authentic, native-sourced content-remain limited. Existing datasets are often machine-translated from English, failing to capture Greek linguistic and cultural characteristics. We introduce GreekMMLU, a native-sourced benchmark for massive multitask language understanding in Greek, comprising 21,805 multiple-choice questions across 45 subject areas, organized under a newly defined subject taxonomy and annotated with educational difficulty levels spanning primary to professional examinations. All questions are sourced or authored in Greek from academic, professional, and governmental exams. We publicly release 16,857 samples and reserve 4,948 samples for a private leaderboard to enable robust and contamination-resistant evaluation. Evaluations of over 80 open- and closed-source LLMs reveal substantial performance gaps between frontier and open-weight models, as well as between Greek-adapted models and general multilingual ones. Finally, we provide a systematic analysis of factors influencing performance-including model scale, adaptation, and prompting-and derive insights for improving LLM capabilities in Greek.
YaPO: Learnable Sparse Activation Steering Vectors for Domain Adaptation
Jan 13, 2026Steering Large Language Models (LLMs) through activation interventions has emerged as a lightweight alternative to fine-tuning for alignment and personalization. Recent work on Bi-directional Preference Optimization (BiPO) shows that dense steering vectors can be learned directly from preference data in a Direct Preference Optimization (DPO) fashion, enabling control over truthfulness, hallucinations, and safety behaviors. However, dense steering vectors often entangle multiple latent factors due to neuron multi-semanticity, limiting their effectiveness and stability in fine-grained settings such as cultural alignment, where closely related values and behaviors (e.g., among Middle Eastern cultures) must be distinguished. In this paper, we propose Yet another Policy Optimization (YaPO), a \textit{reference-free} method that learns \textit{sparse steering vectors} in the latent space of a Sparse Autoencoder (SAE). By optimizing sparse codes, YaPO produces disentangled, interpretable, and efficient steering directions. Empirically, we show that YaPO converges faster, achieves stronger performance, and exhibits improved training stability compared to dense steering baselines. Beyond cultural alignment, YaPO generalizes to a range of alignment-related behaviors, including hallucination, wealth-seeking, jailbreak, and power-seeking. Importantly, YaPO preserves general knowledge, with no measurable degradation on MMLU. Overall, our results show that YaPO provides a general recipe for efficient, stable, and fine-grained alignment of LLMs, with broad applications to controllability and domain adaptation. The associated code and data are publicly available\footnote{https://github.com/MBZUAI-Paris/YaPO}.
If You Want to Be Robust, Be Wary of Initialization
Oct 26, 2025Graph Neural Networks (GNNs) have demonstrated remarkable performance across a spectrum of graph-related tasks, however concerns persist regarding their vulnerability to adversarial perturbations. While prevailing defense strategies focus primarily on pre-processing techniques and adaptive message-passing schemes, this study delves into an under-explored dimension: the impact of weight initialization and associated hyper-parameters, such as training epochs, on a model's robustness. We introduce a theoretical framework bridging the connection between initialization strategies and a network's resilience to adversarial perturbations. Our analysis reveals a direct relationship between initial weights, number of training epochs and the model's vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms. While our primary focus is on GNNs, we extend our theoretical framework, providing a general upper-bound applicable to Deep Neural Networks. Extensive experiments, spanning diverse models and real-world datasets subjected to various adversarial attacks, validate our findings. We illustrate that selecting appropriate initialization not only ensures performance on clean datasets but also enhances model robustness against adversarial perturbations, with observed gaps of up to 50\% compared to alternative initialization approaches.
Beyond Random Sampling: Efficient Language Model Pretraining via Curriculum Learning
Jun 12, 2025Curriculum learning has shown promise in improving training efficiency and generalization in various machine learning domains, yet its potential in pretraining language models remains underexplored, prompting our work as the first systematic investigation in this area. We experimented with different settings, including vanilla curriculum learning, pacing-based sampling, and interleaved curricula-guided by six difficulty metrics spanning linguistic and information-theoretic perspectives. We train models under these settings and evaluate their performance on eight diverse benchmarks. Our experiments reveal that curriculum learning consistently improves convergence in early and mid-training phases, and can yield lasting gains when used as a warmup strategy with up to $3.5\%$ improvement. Notably, we identify compression ratio, lexical diversity, and readability as effective difficulty signals across settings. Our findings highlight the importance of data ordering in large-scale pretraining and provide actionable insights for scalable, data-efficient model development under realistic training scenarios.
Prediction via Shapley Value Regression
May 07, 2025Shapley values have several desirable, theoretically well-supported, properties for explaining black-box model predictions. Traditionally, Shapley values are computed post-hoc, leading to additional computational cost at inference time. To overcome this, a novel method, called ViaSHAP, is proposed, that learns a function to compute Shapley values, from which the predictions can be derived directly by summation. Two approaches to implement the proposed method are explored; one based on the universal approximation theorem and the other on the Kolmogorov-Arnold representation theorem. Results from a large-scale empirical investigation are presented, showing that ViaSHAP using Kolmogorov-Arnold Networks performs on par with state-of-the-art algorithms for tabular data. It is also shown that the explanations of ViaSHAP are significantly more accurate than the popular approximator FastSHAP on both tabular data and images.
Efficient Data Selection for Training Genomic Perturbation Models
Mar 18, 2025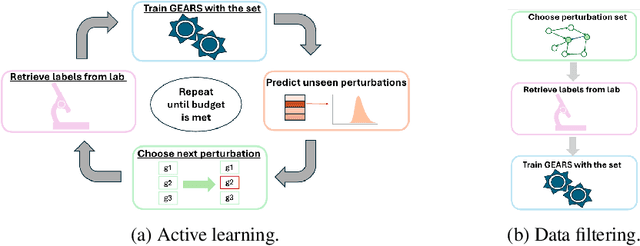
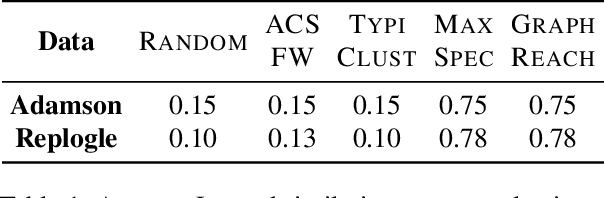
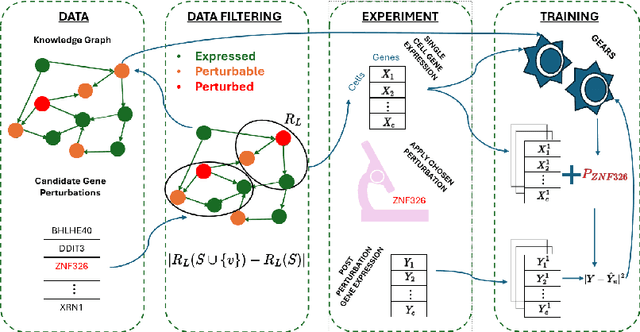
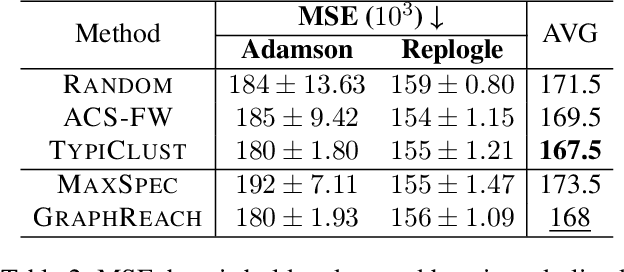
Genomic studies, including CRISPR-based PerturbSeq analyses, face a vast hypothesis space, while gene perturbations remain costly and time-consuming. Gene expression models based on graph neural networks are trained to predict the outcomes of gene perturbations to facilitate such experiments. Active learning methods are often employed to train these models due to the cost of the genomic experiments required to build the training set. However, poor model initialization in active learning can result in suboptimal early selections, wasting time and valuable resources. While typical active learning mitigates this issue over many iterations, the limited number of experimental cycles in genomic studies exacerbates the risk. To this end, we propose graph-based one-shot data selection methods for training gene expression models. Unlike active learning, one-shot data selection predefines the gene perturbations before training, hence removing the initialization bias. The data selection is motivated by theoretical studies of graph neural network generalization. The criteria are defined over the input graph and are optimized with submodular maximization. We compare them empirically to baselines and active learning methods that are state-of-the-art on this problem. The results demonstrate that graph-based one-shot data selection achieves comparable accuracy while alleviating the aforementioned risks.
Rolling Forward: Enhancing LightGCN with Causal Graph Convolution for Credit Bond Recommendation
Mar 18, 2025



Graph Neural Networks have significantly advanced research in recommender systems over the past few years. These methods typically capture global interests using aggregated past interactions and rely on static embeddings of users and items over extended periods of time. While effective in some domains, these methods fall short in many real-world scenarios, especially in finance, where user interests and item popularity evolve rapidly over time. To address these challenges, we introduce a novel extension to Light Graph Convolutional Network (LightGCN) designed to learn temporal node embeddings that capture dynamic interests. Our approach employs causal convolution to maintain a forward-looking model architecture. By preserving the chronological order of user-item interactions and introducing a dynamic update mechanism for embeddings through a sliding window, the proposed model generates well-timed and contextually relevant recommendations. Extensive experiments on a real-world dataset from BNP Paribas demonstrate that our approach significantly enhances the performance of LightGCN while maintaining the simplicity and efficiency of its architecture. Our findings provide new insights into designing graph-based recommender systems in time-sensitive applications, particularly for financial product recommendations.
The Signed Two-Space Proximity Model for Learning Representations in Protein-Protein Interaction Networks
Mar 05, 2025Accurately predicting complex protein-protein interactions (PPIs) is crucial for decoding biological processes, from cellular functioning to disease mechanisms. However, experimental methods for determining PPIs are computationally expensive. Thus, attention has been recently drawn to machine learning approaches. Furthermore, insufficient effort has been made toward analyzing signed PPI networks, which capture both activating (positive) and inhibitory (negative) interactions. To accurately represent biological relationships, we present the Signed Two-Space Proximity Model (S2-SPM) for signed PPI networks, which explicitly incorporates both types of interactions, reflecting the complex regulatory mechanisms within biological systems. This is achieved by leveraging two independent latent spaces to differentiate between positive and negative interactions while representing protein similarity through proximity in these spaces. Our approach also enables the identification of archetypes representing extreme protein profiles. S2-SPM's superior performance in predicting the presence and sign of interactions in SPPI networks is demonstrated in link prediction tasks against relevant baseline methods. Additionally, the biological prevalence of the identified archetypes is confirmed by an enrichment analysis of Gene Ontology (GO) terms, which reveals that distinct biological tasks are associated with archetypal groups formed by both interactions. This study is also validated regarding statistical significance and sensitivity analysis, providing insights into the functional roles of different interaction types. Finally, the robustness and consistency of the extracted archetype structures are confirmed using the Bayesian Normalized Mutual Information (BNMI) metric, proving the model's reliability in capturing meaningful SPPI patterns.
Obtaining Example-Based Explanations from Deep Neural Networks
Feb 27, 2025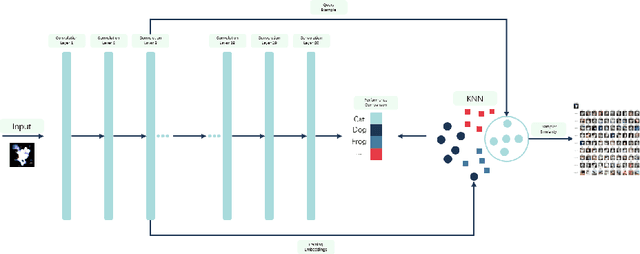


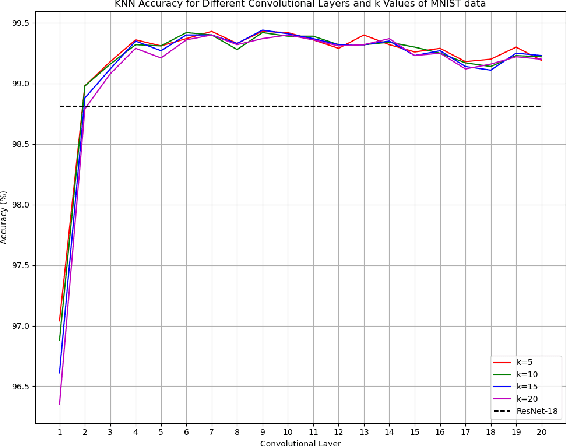
Most techniques for explainable machine learning focus on feature attribution, i.e., values are assigned to the features such that their sum equals the prediction. Example attribution is another form of explanation that assigns weights to the training examples, such that their scalar product with the labels equals the prediction. The latter may provide valuable complementary information to feature attribution, in particular in cases where the features are not easily interpretable. Current example-based explanation techniques have targeted a few model types only, such as k-nearest neighbors and random forests. In this work, a technique for obtaining example-based explanations from deep neural networks (EBE-DNN) is proposed. The basic idea is to use the deep neural network to obtain an embedding, which is employed by a k-nearest neighbor classifier to form a prediction; the example attribution can hence straightforwardly be derived from the latter. Results from an empirical investigation show that EBE-DNN can provide highly concentrated example attributions, i.e., the predictions can be explained with few training examples, without reducing accuracy compared to the original deep neural network. Another important finding from the empirical investigation is that the choice of layer to use for the embeddings may have a large impact on the resulting accuracy.
LLM as a Broken Telephone: Iterative Generation Distorts Information
Feb 27, 2025
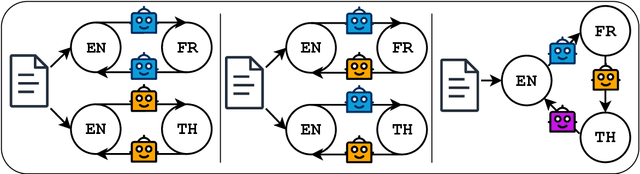
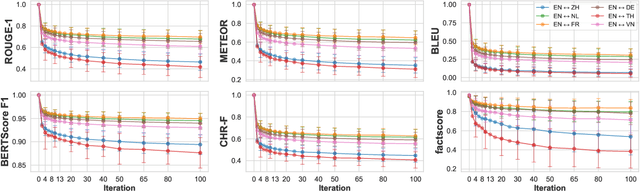

As large language models are increasingly responsible for online content, concerns arise about the impact of repeatedly processing their own outputs. Inspired by the "broken telephone" effect in chained human communication, this study investigates whether LLMs similarly distort information through iterative generation. Through translation-based experiments, we find that distortion accumulates over time, influenced by language choice and chain complexity. While degradation is inevitable, it can be mitigated through strategic prompting techniques. These findings contribute to discussions on the long-term effects of AI-mediated information propagation, raising important questions about the reliability of LLM-generated content in iterative workflows.