 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction via Shapley Value Regression
May 07, 2025Shapley values have several desirable, theoretically well-supported, properties for explaining black-box model predictions. Traditionally, Shapley values are computed post-hoc, leading to additional computational cost at inference time. To overcome this, a novel method, called ViaSHAP, is proposed, that learns a function to compute Shapley values, from which the predictions can be derived directly by summation. Two approaches to implement the proposed method are explored; one based on the universal approximation theorem and the other on the Kolmogorov-Arnold representation theorem. Results from a large-scale empirical investigation are presented, showing that ViaSHAP using Kolmogorov-Arnold Networks performs on par with state-of-the-art algorithms for tabular data. It is also shown that the explanations of ViaSHAP are significantly more accurate than the popular approximator FastSHAP on both tabular data and images.
Explaining Predictions by Characteristic Rules
May 31, 2024Characteristic rules have been advocated for their ability to improve interpretability over discriminative rules within the area of rule learning. However, the former type of rule has not yet been used by techniques for explaining predictions. A novel explanation technique, called CEGA (Characteristic Explanatory General Association rules), is proposed, which employs association rule mining to aggregate multiple explanations generated by any standard local explanation technique into a set of characteristic rules. An empirical investigation is presented, in which CEGA is compared to two state-of-the-art methods, Anchors and GLocalX, for producing local and aggregated explanations in the form of discriminative rules. The results suggest that the proposed approach provides a better trade-off between fidelity and complexity compared to the two state-of-the-art approaches; CEGA and Anchors significantly outperform GLocalX with respect to fidelity, while CEGA and GLocalX significantly outperform Anchors with respect to the number of generated rules. The effect of changing the format of the explanations of CEGA to discriminative rules and using LIME and SHAP as local explanation techniques instead of Anchors are also investigated. The results show that the characteristic explanatory rules still compete favorably with rules in the standard discriminative format. The results also indicate that using CEGA in combination with either SHAP or Anchors consistently leads to a higher fidelity compared to using LIME as the local explanation technique.
* Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2022
Approximating Score-based Explanation Techniques Using Conformal Regression
Aug 23, 2023



Score-based explainable machine-learning techniques are often used to understand the logic behind black-box models. However, such explanation techniques are often computationally expensive, which limits their application in time-critical contexts. Therefore, we propose and investigate the use of computationally less costly regression models for approximating the output of score-based explanation techniques, such as SHAP. Moreover, validity guarantees for the approximated values are provided by the employed inductive conformal prediction framework. We propose several non-conformity measures designed to take the difficulty of approximating the explanations into account while keeping the computational cost low. We present results from a large-scale empirical investigation, in which the approximate explanations generated by our proposed models are evaluated with respect to efficiency (interval size). The results indicate that the proposed method can significantly improve execution time compared to the fast version of SHAP, TreeSHAP. The results also suggest that the proposed method can produce tight intervals, while providing validity guarantees. Moreover, the proposed approach allows for comparing explanations of different approximation methods and selecting a method based on how informative (tight) are the predicted intervals.
* 20 pages, 14 figures, The 12th Symposium on Conformal and Probabilistic Prediction with Applications (COPA 2023)
Interpretable Graph Neural Networks for Tabular Data
Aug 17, 2023

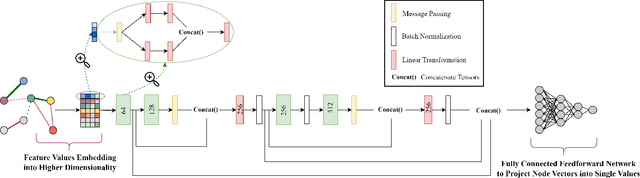
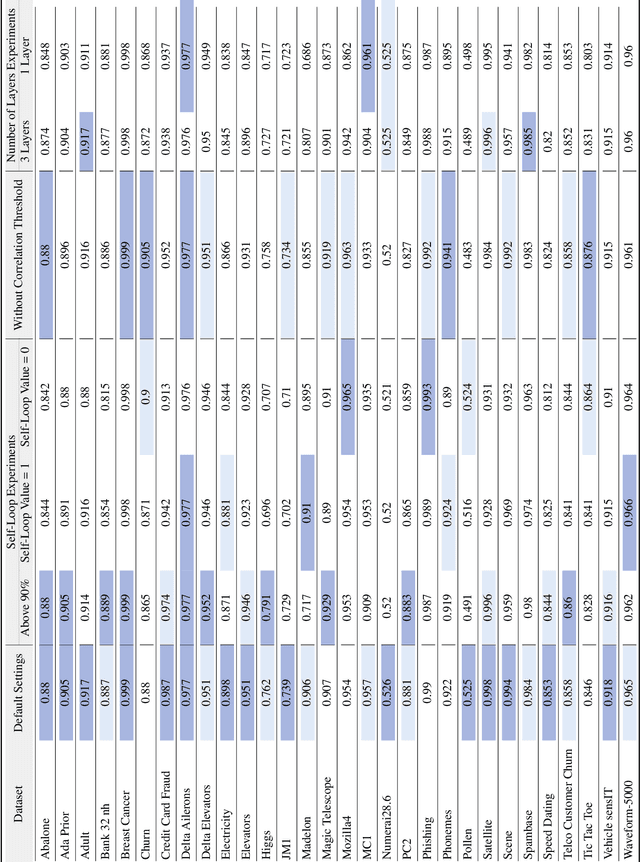
Data in tabular format is frequently occurring in real-world applications. Graph Neural Networks (GNNs) have recently been extended to effectively handle such data, allowing feature interactions to be captured through representation learning. However, these approaches essentially produce black-box models, in the form of deep neural networks, precluding users from following the logic behind the model predictions. We propose an approach, called IGNNet (Interpretable Graph Neural Network for tabular data), which constrains the learning algorithm to produce an interpretable model, where the model shows how the predictions are exactly computed from the original input features. A large-scale empirical investigation is presented, showing that IGNNet is performing on par with state-of-the-art machine-learning algorithms that target tabular data, including XGBoost, Random Forests, and TabNet. At the same time, the results show that the explanations obtained from IGNNet are aligned with the true Shapley values of the features without incurring any additional computational overhead.