 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Explanations for Regression
Sep 01, 2023Artificial Intelligence (AI) is often an integral part of modern decision support systems (DSSs). The best-performing predictive models used in AI-based DSSs lack transparency. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance. However, a critical drawback of existing local explanation methods is their inability to quantify the uncertainty associated with a feature's importance. This paper introduces an extension of a feature importance explanation method, Calibrated Explanations (CE), previously only supporting classification, with support for standard regression and probabilistic regression, i.e., the probability that the target is above an arbitrary threshold. The extension for regression keeps all the benefits of CE, such as calibration of the prediction from the underlying model with confidence intervals, uncertainty quantification of feature importance, and allows both factual and counterfactual explanations. CE for standard regression provides fast, reliable, stable, and robust explanations. CE for probabilistic regression provides an entirely new way of creating probabilistic explanations from any ordinary regression model and with a dynamic selection of thresholds. The performance of CE for probabilistic regression regarding stability and speed is comparable to LIME. The method is model agnostic with easily understood conditional rules. An implementation in Python is freely available on GitHub and for installation using pip making the results in this paper easily replicable.
Approximating Score-based Explanation Techniques Using Conformal Regression
Aug 23, 2023



Score-based explainable machine-learning techniques are often used to understand the logic behind black-box models. However, such explanation techniques are often computationally expensive, which limits their application in time-critical contexts. Therefore, we propose and investigate the use of computationally less costly regression models for approximating the output of score-based explanation techniques, such as SHAP. Moreover, validity guarantees for the approximated values are provided by the employed inductive conformal prediction framework. We propose several non-conformity measures designed to take the difficulty of approximating the explanations into account while keeping the computational cost low. We present results from a large-scale empirical investigation, in which the approximate explanations generated by our proposed models are evaluated with respect to efficiency (interval size). The results indicate that the proposed method can significantly improve execution time compared to the fast version of SHAP, TreeSHAP. The results also suggest that the proposed method can produce tight intervals, while providing validity guarantees. Moreover, the proposed approach allows for comparing explanations of different approximation methods and selecting a method based on how informative (tight) are the predicted intervals.
* 20 pages, 14 figures, The 12th Symposium on Conformal and Probabilistic Prediction with Applications (COPA 2023)
Well-Calibrated Probabilistic Predictive Maintenance using Venn-Abers
Jun 11, 2023



When using machine learning for fault detection, a common problem is the fact that most data sets are very unbalanced, with the minority class (a fault) being the interesting one. In this paper, we investigate the usage of Venn-Abers predictors, looking specifically at the effect on the minority class predictions. A key property of Venn-Abers predictors is that they output well-calibrated probability intervals. In the experiments, we apply Venn-Abers calibration to decision trees, random forests and XGBoost models, showing how both overconfident and underconfident models are corrected. In addition, the benefit of using the valid probability intervals produced by Venn-Abers for decision support is demonstrated. When using techniques producing opaque underlying models, e.g., random forest and XGBoost, each prediction will consist of not only the label, but also a valid probability interval, where the width is an indication of the confidence in the estimate. Adding Venn-Abers on top of a decision tree allows inspection and analysis of the model, to understand both the underlying relationship, and finding out in which parts of feature space that the model is accurate and/or confident.
Calibrated Explanations: with Uncertainty Information and Counterfactuals
May 03, 2023



Artificial Intelligence (AI) has become an integral part of decision support systems (DSSs) in various domains, but the lack of transparency in the predictive models used in AI-based DSSs can lead to misuse or disuse. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance, but they suffer from drawbacks such as instability. To address these issues, we propose a new feature importance explanation method, Calibrated Explanations (CE), which is based on Venn-Abers and calibrates the underlying model while generating feature importance explanations. CE provides fast, reliable, stable, and robust explanations, along with uncertainty quantification of the probability estimates and feature importance weights. Furthermore, the method is model agnostic with easily understood conditional rules and can also generate counterfactual explanations with uncertainty quantification.
A Meta Survey of Quality Evaluation Criteria in Explanation Methods
Mar 25, 2022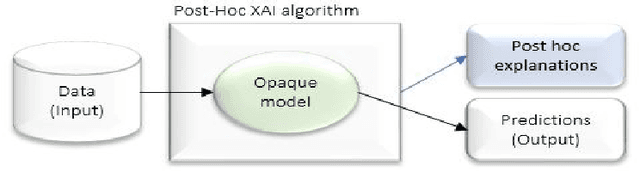
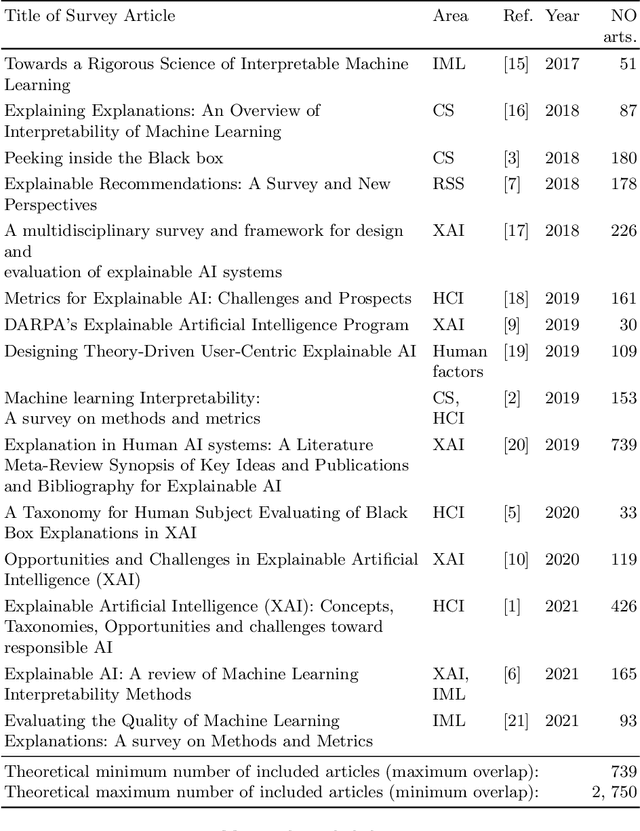
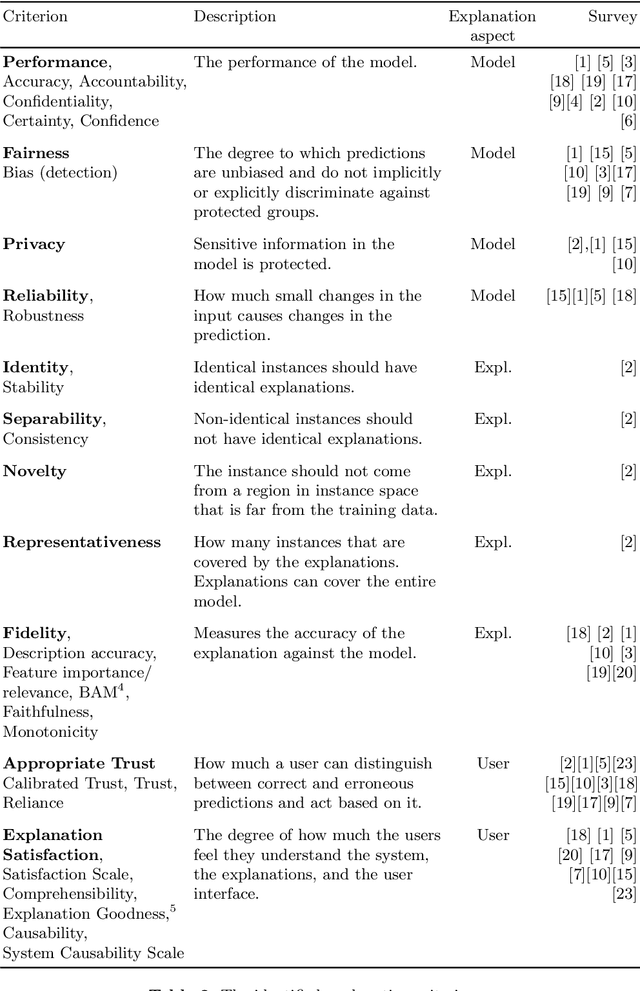
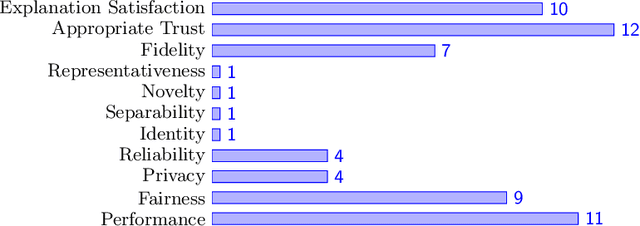
Explanation methods and their evaluation have become a significant issue in explainable artificial intelligence (XAI) due to the recent surge of opaque AI models in decision support systems (DSS). Since the most accurate AI models are opaque with low transparency and comprehensibility, explanations are essential for bias detection and control of uncertainty. There are a plethora of criteria to choose from when evaluating explanation method quality. However, since existing criteria focus on evaluating single explanation methods, it is not obvious how to compare the quality of different methods. This lack of consensus creates a critical shortage of rigour in the field, although little is written about comparative evaluations of explanation methods. In this paper, we have conducted a semi-systematic meta-survey over fifteen literature surveys covering the evaluation of explainability to identify existing criteria usable for comparative evaluations of explanation methods. The main contribution in the paper is the suggestion to use appropriate trust as a criterion to measure the outcome of the subjective evaluation criteria and consequently make comparative evaluations possible. We also present a model of explanation quality aspects. In the model, criteria with similar definitions are grouped and related to three identified aspects of quality; model, explanation, and user. We also notice four commonly accepted criteria (groups) in the literature, covering all aspects of explanation quality: Performance, appropriate trust, explanation satisfaction, and fidelity. We suggest the model be used as a chart for comparative evaluations to create more generalisable research in explanation quality.