 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaPO: Learnable Sparse Activation Steering Vectors for Domain Adaptation
Jan 13, 2026Steering Large Language Models (LLMs) through activation interventions has emerged as a lightweight alternative to fine-tuning for alignment and personalization. Recent work on Bi-directional Preference Optimization (BiPO) shows that dense steering vectors can be learned directly from preference data in a Direct Preference Optimization (DPO) fashion, enabling control over truthfulness, hallucinations, and safety behaviors. However, dense steering vectors often entangle multiple latent factors due to neuron multi-semanticity, limiting their effectiveness and stability in fine-grained settings such as cultural alignment, where closely related values and behaviors (e.g., among Middle Eastern cultures) must be distinguished. In this paper, we propose Yet another Policy Optimization (YaPO), a \textit{reference-free} method that learns \textit{sparse steering vectors} in the latent space of a Sparse Autoencoder (SAE). By optimizing sparse codes, YaPO produces disentangled, interpretable, and efficient steering directions. Empirically, we show that YaPO converges faster, achieves stronger performance, and exhibits improved training stability compared to dense steering baselines. Beyond cultural alignment, YaPO generalizes to a range of alignment-related behaviors, including hallucination, wealth-seeking, jailbreak, and power-seeking. Importantly, YaPO preserves general knowledge, with no measurable degradation on MMLU. Overall, our results show that YaPO provides a general recipe for efficient, stable, and fine-grained alignment of LLMs, with broad applications to controllability and domain adaptation. The associated code and data are publicly available\footnote{https://github.com/MBZUAI-Paris/YaPO}.
Beyond Random Sampling: Efficient Language Model Pretraining via Curriculum Learning
Jun 12, 2025Curriculum learning has shown promise in improving training efficiency and generalization in various machine learning domains, yet its potential in pretraining language models remains underexplored, prompting our work as the first systematic investigation in this area. We experimented with different settings, including vanilla curriculum learning, pacing-based sampling, and interleaved curricula-guided by six difficulty metrics spanning linguistic and information-theoretic perspectives. We train models under these settings and evaluate their performance on eight diverse benchmarks. Our experiments reveal that curriculum learning consistently improves convergence in early and mid-training phases, and can yield lasting gains when used as a warmup strategy with up to $3.5\%$ improvement. Notably, we identify compression ratio, lexical diversity, and readability as effective difficulty signals across settings. Our findings highlight the importance of data ordering in large-scale pretraining and provide actionable insights for scalable, data-efficient model development under realistic training scenarios.
Graph Linearization Methods for Reasoning on Graphs with Large Language Models
Oct 25, 2024



Large language models have evolved to process multiple modalities beyond text, such as images and audio, which motivates us to explore how to effectively leverage them for graph machine learning tasks. The key question, therefore, is how to transform graphs into linear sequences of tokens, a process we term graph linearization, so that LLMs can handle graphs naturally. We consider that graphs should be linearized meaningfully to reflect certain properties of natural language text, such as local dependency and global alignment, in order to ease contemporary LLMs, trained on trillions of textual tokens, better understand graphs. To achieve this, we developed several graph linearization methods based on graph centrality, degeneracy, and node relabeling schemes. We then investigated their effect on LLM performance in graph reasoning tasks. Experimental results on synthetic graphs demonstrate the effectiveness of our methods compared to random linearization baselines. Our work introduces novel graph representations suitable for LLMs, contributing to the potential integration of graph machine learning with the trend of multi-modal processing using a unified transformer model.
Atlas-Chat: Adapting Large Language Models for Low-Resource Moroccan Arabic Dialect
Sep 26, 2024We introduce Atlas-Chat, the first-ever collection of large language models specifically developed for dialectal Arabic. Focusing on Moroccan Arabic, also known as Darija, we construct our instruction dataset by consolidating existing Darija language resources, creating novel datasets both manually and synthetically, and translating English instructions with stringent quality control. Atlas-Chat-9B and 2B models, fine-tuned on the dataset, exhibit superior ability in following Darija instructions and performing standard NLP tasks. Notably, our models outperform both state-of-the-art and Arabic-specialized LLMs like LLaMa, Jais, and AceGPT, e.g., achieving a 13% performance boost over a larger 13B model on DarijaMMLU, in our newly introduced evaluation suite for Darija covering both discriminative and generative tasks. Furthermore, we perform an experimental analysis of various fine-tuning strategies and base model choices to determine optimal configurations. All our resources are publicly accessible, and we believe our work offers comprehensive design methodologies of instruction-tuning for low-resource language variants, which are often neglected in favor of data-rich languages by contemporary LLMs.
Neural Graph Generator: Feature-Conditioned Graph Generation using Latent Diffusion Models
Mar 03, 2024Graph generation has emerged as a crucial task in machine learning, with significant challenges in generating graphs that accurately reflect specific properties. Existing methods often fall short in efficiently addressing this need as they struggle with the high-dimensional complexity and varied nature of graph properties. In this paper, we introduce the Neural Graph Generator (NGG), a novel approach which utilizes conditioned latent diffusion models for graph generation. NGG demonstrates a remarkable capacity to model complex graph patterns, offering control over the graph generation process. NGG employs a variational graph autoencoder for graph compression and a diffusion process in the latent vector space, guided by vectors summarizing graph statistics. We demonstrate NGG's versatility across various graph generation tasks, showing its capability to capture desired graph properties and generalize to unseen graphs. This work signifies a significant shift in graph generation methodologies, offering a more practical and efficient solution for generating diverse types of graphs with specific characteristics.
Prot2Text: Multimodal Protein's Function Generation with GNNs and Transformers
Jul 25, 2023The complex nature of big biological systems pushed some scientists to classify its understanding under the inconceivable missions. Different leveled challenges complicated this task, one of is the prediction of a protein's function. In recent years, significant progress has been made in this field through the development of various machine learning approaches. However, most existing methods formulate the task as a multi-classification problem, i.e assigning predefined labels to proteins. In this work, we propose a novel approach, \textbf{Prot2Text}, which predicts a protein function's in a free text style, moving beyond the conventional binary or categorical classifications. By combining Graph Neural Networks(GNNs) and Large Language Models(LLMs), in an encoder-decoder framework, our model effectively integrates diverse data types including proteins' sequences, structures, and textual annotations. This multimodal approach allows for a holistic representation of proteins' functions, enabling the generation of detailed and accurate descriptions. To evaluate our model, we extracted a multimodal protein dataset from SwissProt, and demonstrate empirically the effectiveness of Prot2Text. These results highlight the transformative impact of multimodal models, specifically the fusion of GNNs and LLMs, empowering researchers with powerful tools for more accurate prediction of proteins' functions. The code, the models and a demo will be publicly released.
GreekBART: The First Pretrained Greek Sequence-to-Sequence Model
Apr 03, 2023



The era of transfer learning has revolutionized the fields of Computer Vision and Natural Language Processing, bringing powerful pretrained models with exceptional performance across a variety of tasks. Specifically, Natural Language Processing tasks have been dominated by transformer-based language models. In Natural Language Inference and Natural Language Generation tasks, the BERT model and its variants, as well as the GPT model and its successors, demonstrated exemplary performance. However, the majority of these models are pretrained and assessed primarily for the English language or on a multilingual corpus. In this paper, we introduce GreekBART, the first Seq2Seq model based on BART-base architecture and pretrained on a large-scale Greek corpus. We evaluate and compare GreekBART against BART-random, Greek-BERT, and XLM-R on a variety of discriminative tasks. In addition, we examine its performance on two NLG tasks from GreekSUM, a newly introduced summarization dataset for the Greek language. The model, the code, and the new summarization dataset will be publicly available.
Word Sense Induction with Hierarchical Clustering and Mutual Information Maximization
Oct 11, 2022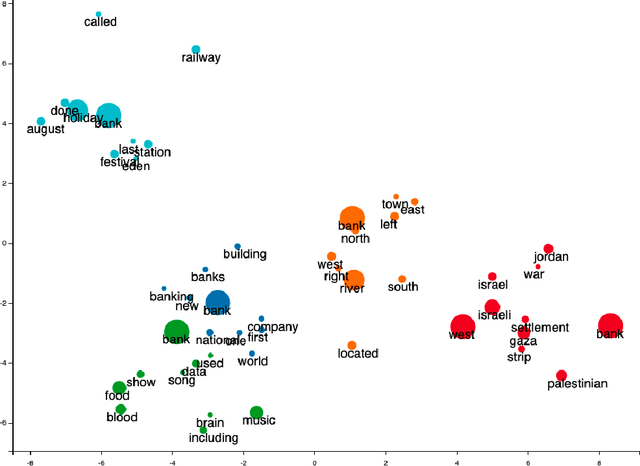
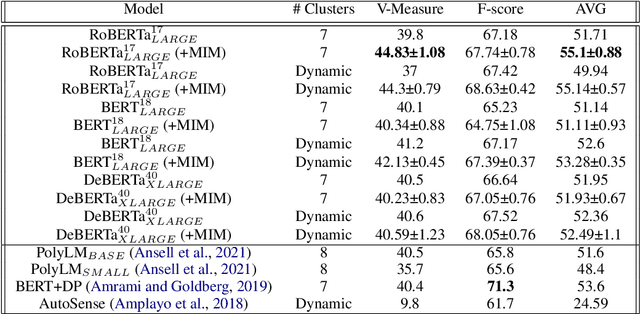
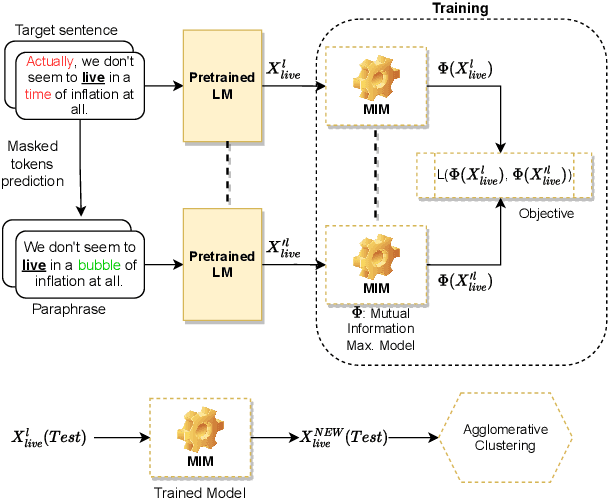
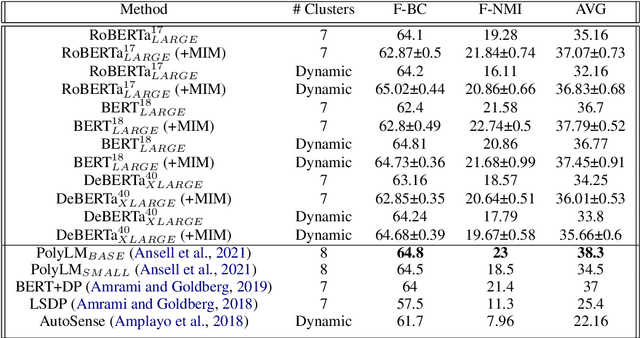
Word sense induction (WSI) is a difficult problem in natural language processing that involves the unsupervised automatic detection of a word's senses (i.e. meanings). Recent work achieves significant results on the WSI task by pre-training a language model that can exclusively disambiguate word senses, whereas others employ previously pre-trained language models in conjunction with additional strategies to induce senses. In this paper, we propose a novel unsupervised method based on hierarchical clustering and invariant information clustering (IIC). The IIC is used to train a small model to optimize the mutual information between two vector representations of a target word occurring in a pair of synthetic paraphrases. This model is later used in inference mode to extract a higher quality vector representation to be used in the hierarchical clustering. We evaluate our method on two WSI tasks and in two distinct clustering configurations (fixed and dynamic number of clusters). We empirically demonstrate that, in certain cases, our approach outperforms prior WSI state-of-the-art methods, while in others, it achieves a competitive performance.
Political Communities on Twitter: Case Study of the 2022 French Presidential Election
Apr 15, 2022
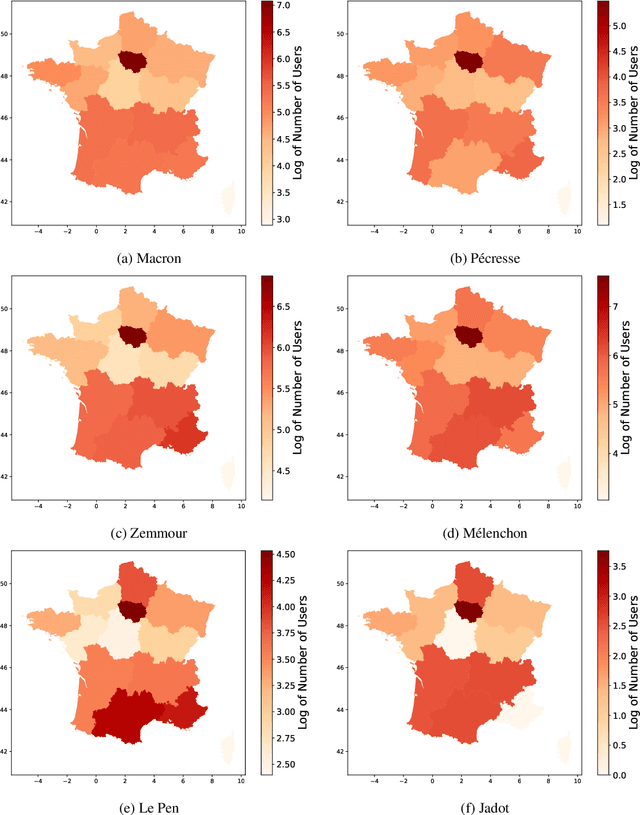
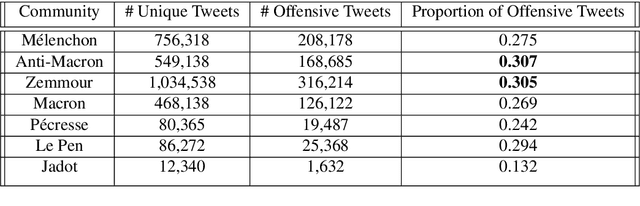
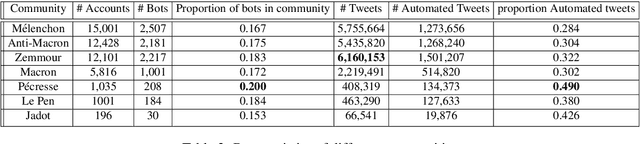
With the significant increase in users on social media platforms, a new means of political campaigning has appeared. Twitter and Facebook are now notable campaigning tools during elections. Indeed, the candidates and their parties now take to the internet to interact and spread their ideas. In this paper, we aim to identify political communities formed on Twitter during the 2022 French presidential election and analyze each respective community. We create a large-scale Twitter dataset containing 1.2 million users and 62.6 million tweets that mention keywords relevant to the election. We perform community detection on a retweet graph of users and propose an in-depth analysis of the stance of each community. Finally, we attempt to detect offensive tweets and automatic bots, comparing across communities in order to gain insight into each candidate's supporter demographics and online campaign strategy.
NLP Research and Resources at DaSciM, Ecole Polytechnique
Dec 01, 2021DaSciM (Data Science and Mining) part of LIX at Ecole Polytechnique, established in 2013 and since then producing research results in the area of large scale data analysis via methods of machine and deep learning. The group has been specifically active in the area of NLP and text mining with interesting results at methodological and resources level. Here follow our different contributions of interest to the AFIA community.