 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Of Word Embeddings From Large-Scale French Web Content
Paper and Code


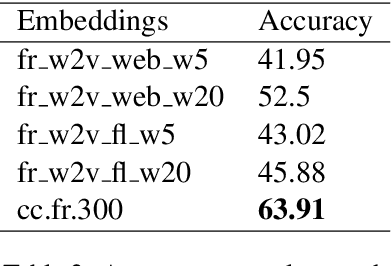
Distributed word representations are popularly used in many tasks in natural language processing, adding that pre-trained word vectors on huge text corpus achieved high performance in many different NLP tasks. This paper introduces multiple high quality word vectors for the French language where two of them are trained on huge crawled French data and the others are trained on an already existing French corpus. We also evaluate the quality of our proposed word vectors and the existing French word vectors on the French word analogy task. In addition, we do the evaluation on multiple real NLP tasks that show the important performance enhancement of the pre-trained word vectors compared to the existing and random ones. Finally, we created a demo web application to test and visualize the obtained word embeddings. The produced French word embeddings are available to the public, along with the fine-tuning code on the NLU tasks and the demo code.