 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning the Validity of Summarization Datasets and Improving Their Factual Consistency
Oct 31, 2022The topic of summarization evaluation has recently attracted a surge of attention due to the rapid development of abstractive summarization systems. However, the formulation of the task is rather ambiguous, neither the linguistic nor the natural language processing community has succeeded in giving a mutually agreed-upon definition. Due to this lack of well-defined formulation, a large number of popular abstractive summarization datasets are constructed in a manner that neither guarantees validity nor meets one of the most essential criteria of summarization: factual consistency. In this paper, we address this issue by combining state-of-the-art factual consistency models to identify the problematic instances present in popular summarization datasets. We release SummFC, a filtered summarization dataset with improved factual consistency, and demonstrate that models trained on this dataset achieve improved performance in nearly all quality aspects. We argue that our dataset should become a valid benchmark for developing and evaluating summarization systems.
DATScore: Evaluating Translation with Data Augmented Translations
Oct 12, 2022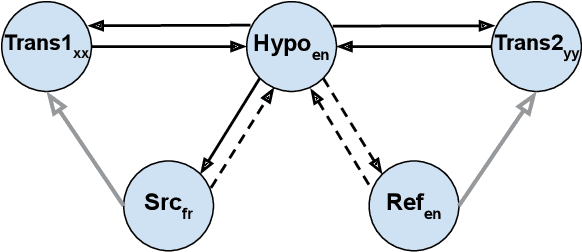
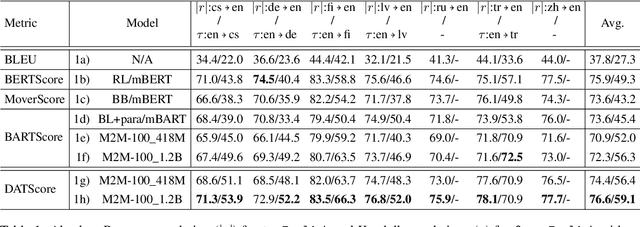
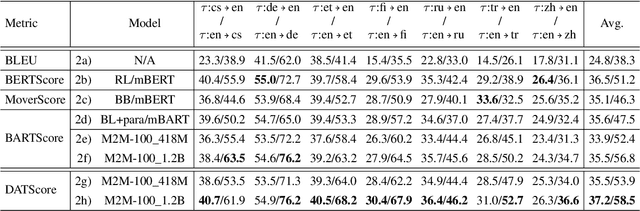
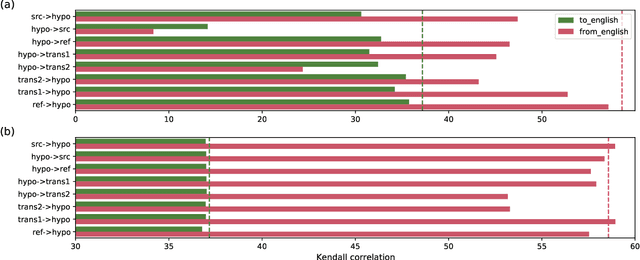
The rapid development of large pretrained language models has revolutionized not only the field of Natural Language Generation (NLG) but also its evaluation. Inspired by the recent work of BARTScore: a metric leveraging the BART language model to evaluate the quality of generated text from various aspects, we introduce DATScore. DATScore uses data augmentation techniques to improve the evaluation of machine translation. Our main finding is that introducing data augmented translations of the source and reference texts is greatly helpful in evaluating the quality of the generated translation. We also propose two novel score averaging and term weighting strategies to improve the original score computing process of BARTScore. Experimental results on WMT show that DATScore correlates better with human meta-evaluations than the other recent state-of-the-art metrics, especially for low-resource languages. Ablation studies demonstrate the value added by our new scoring strategies. Moreover, we report in our extended experiments the performance of DATScore on 3 NLG tasks other than translation.
Word Sense Induction with Hierarchical Clustering and Mutual Information Maximization
Oct 11, 2022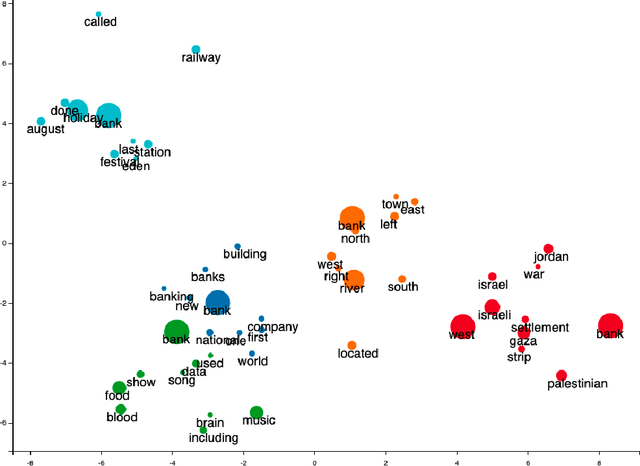
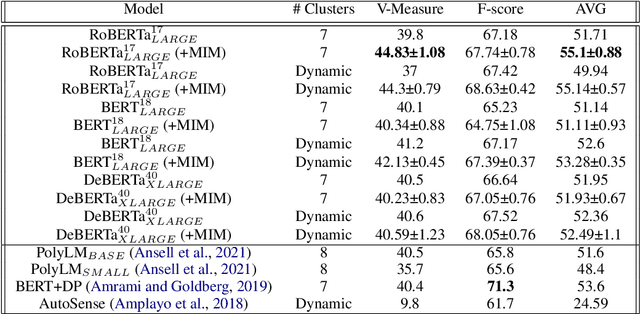
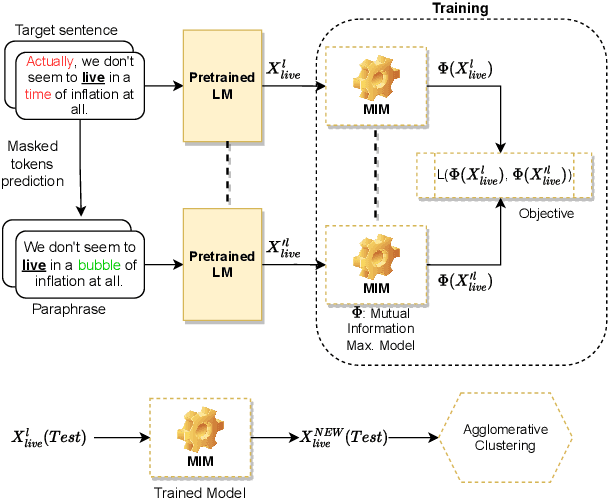
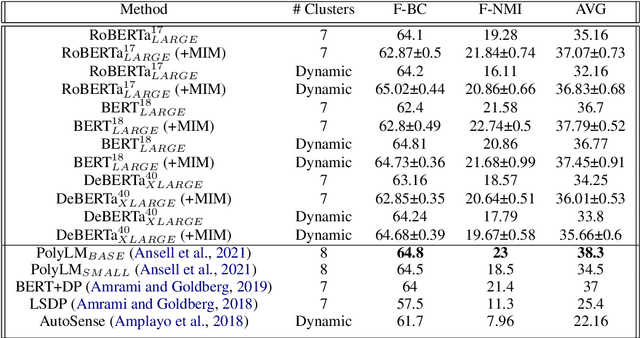
Word sense induction (WSI) is a difficult problem in natural language processing that involves the unsupervised automatic detection of a word's senses (i.e. meanings). Recent work achieves significant results on the WSI task by pre-training a language model that can exclusively disambiguate word senses, whereas others employ previously pre-trained language models in conjunction with additional strategies to induce senses. In this paper, we propose a novel unsupervised method based on hierarchical clustering and invariant information clustering (IIC). The IIC is used to train a small model to optimize the mutual information between two vector representations of a target word occurring in a pair of synthetic paraphrases. This model is later used in inference mode to extract a higher quality vector representation to be used in the hierarchical clustering. We evaluate our method on two WSI tasks and in two distinct clustering configurations (fixed and dynamic number of clusters). We empirically demonstrate that, in certain cases, our approach outperforms prior WSI state-of-the-art methods, while in others, it achieves a competitive performance.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
AraBART: a Pretrained Arabic Sequence-to-Sequence Model for Abstractive Summarization
Mar 21, 2022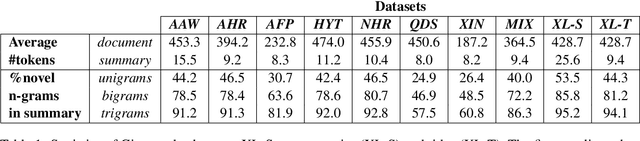
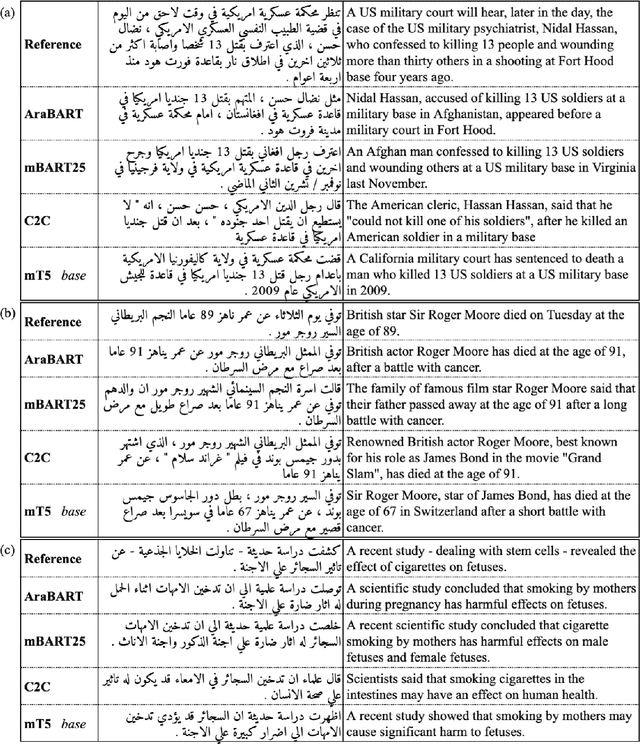
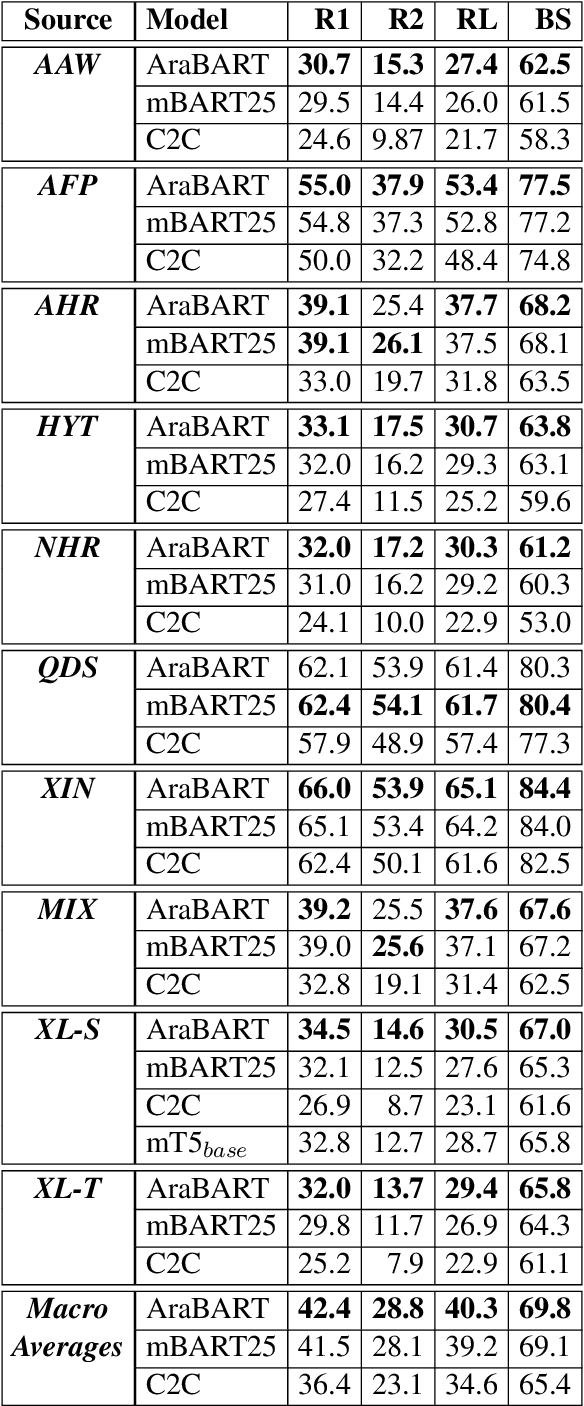
Like most natural language understanding and generation tasks, state-of-the-art models for summarization are transformer-based sequence-to-sequence architectures that are pretrained on large corpora. While most existing models focused on English, Arabic remained understudied. In this paper we propose AraBART, the first Arabic model in which the encoder and the decoder are pretrained end-to-end, based on BART. We show that AraBART achieves the best performance on multiple abstractive summarization datasets, outperforming strong baselines including a pretrained Arabic BERT-based model and multilingual mBART and mT5 models.
NLP Research and Resources at DaSciM, Ecole Polytechnique
Dec 01, 2021DaSciM (Data Science and Mining) part of LIX at Ecole Polytechnique, established in 2013 and since then producing research results in the area of large scale data analysis via methods of machine and deep learning. The group has been specifically active in the area of NLP and text mining with interesting results at methodological and resources level. Here follow our different contributions of interest to the AFIA community.
FrugalScore: Learning Cheaper, Lighter and Faster Evaluation Metricsfor Automatic Text Generation
Oct 16, 2021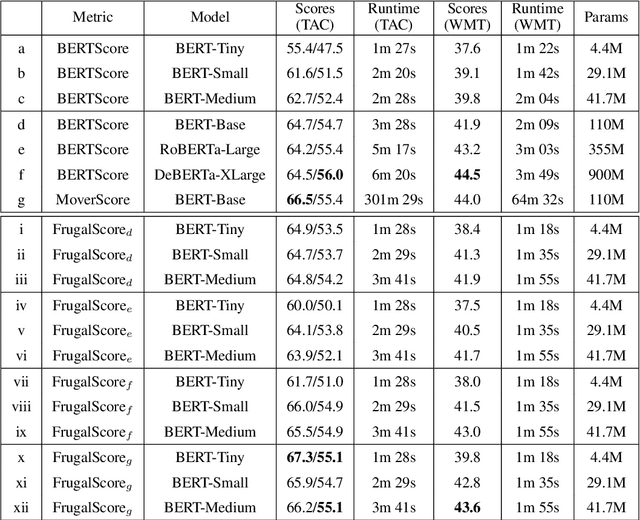
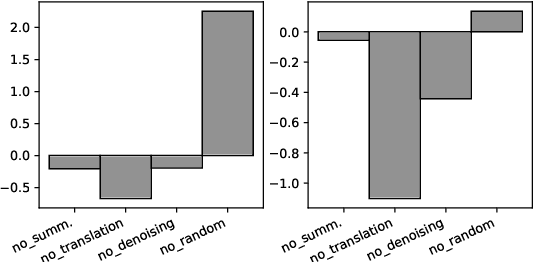


Fast and reliable evaluation metrics are key to R&D progress. While traditional natural language generation metrics are fast, they are not very reliable. Conversely, new metrics based on large pretrained language models are much more reliable, but require significant computational resources. In this paper, we propose FrugalScore, an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance. Experiments with BERTScore and MoverScore on summarization and translation show that FrugalScore is on par with the original metrics (and sometimes better), while having several orders of magnitude less parameters and running several times faster. On average over all learned metrics, tasks, and variants, FrugalScore retains 96.8% of the performance, runs 24 times faster, and has 35 times less parameters than the original metrics. We make our trained metrics publicly available, to benefit the entire NLP community and in particular researchers and practitioners with limited resources.
Evaluation Of Word Embeddings From Large-Scale French Web Content
May 05, 2021

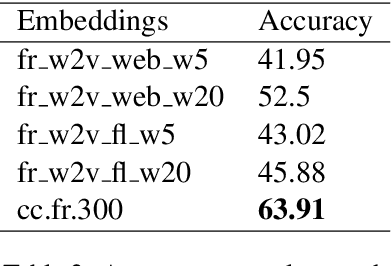
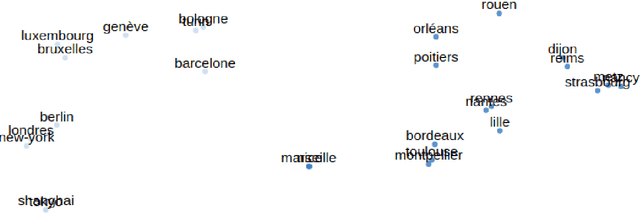
Distributed word representations are popularly used in many tasks in natural language processing, adding that pre-trained word vectors on huge text corpus achieved high performance in many different NLP tasks. This paper introduces multiple high quality word vectors for the French language where two of them are trained on huge crawled French data and the others are trained on an already existing French corpus. We also evaluate the quality of our proposed word vectors and the existing French word vectors on the French word analogy task. In addition, we do the evaluation on multiple real NLP tasks that show the important performance enhancement of the pre-trained word vectors compared to the existing and random ones. Finally, we created a demo web application to test and visualize the obtained word embeddings. The produced French word embeddings are available to the public, along with the fine-tuning code on the NLU tasks and the demo code.
BARThez: a Skilled Pretrained French Sequence-to-Sequence Model
Oct 23, 2020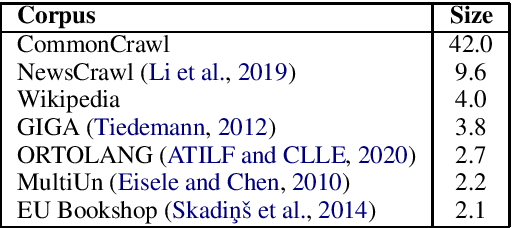
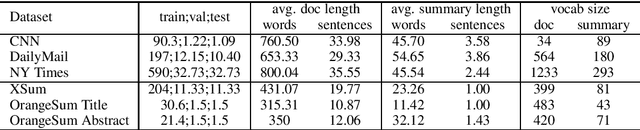


Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing (NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language understanding tasks. While there are some notable exceptions, most of the available models and research have been conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language (to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez, provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.