 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek
Feb 05, 2026Large Language Models (LLMs) are commonly trained on multilingual corpora that include Greek, yet reliable evaluation benchmarks for Greek-particularly those based on authentic, native-sourced content-remain limited. Existing datasets are often machine-translated from English, failing to capture Greek linguistic and cultural characteristics. We introduce GreekMMLU, a native-sourced benchmark for massive multitask language understanding in Greek, comprising 21,805 multiple-choice questions across 45 subject areas, organized under a newly defined subject taxonomy and annotated with educational difficulty levels spanning primary to professional examinations. All questions are sourced or authored in Greek from academic, professional, and governmental exams. We publicly release 16,857 samples and reserve 4,948 samples for a private leaderboard to enable robust and contamination-resistant evaluation. Evaluations of over 80 open- and closed-source LLMs reveal substantial performance gaps between frontier and open-weight models, as well as between Greek-adapted models and general multilingual ones. Finally, we provide a systematic analysis of factors influencing performance-including model scale, adaptation, and prompting-and derive insights for improving LLM capabilities in Greek.
Graph Linearization Methods for Reasoning on Graphs with Large Language Models
Oct 25, 2024



Large language models have evolved to process multiple modalities beyond text, such as images and audio, which motivates us to explore how to effectively leverage them for graph machine learning tasks. The key question, therefore, is how to transform graphs into linear sequences of tokens, a process we term graph linearization, so that LLMs can handle graphs naturally. We consider that graphs should be linearized meaningfully to reflect certain properties of natural language text, such as local dependency and global alignment, in order to ease contemporary LLMs, trained on trillions of textual tokens, better understand graphs. To achieve this, we developed several graph linearization methods based on graph centrality, degeneracy, and node relabeling schemes. We then investigated their effect on LLM performance in graph reasoning tasks. Experimental results on synthetic graphs demonstrate the effectiveness of our methods compared to random linearization baselines. Our work introduces novel graph representations suitable for LLMs, contributing to the potential integration of graph machine learning with the trend of multi-modal processing using a unified transformer model.
Bias in the Mirror : Are LLMs opinions robust to their own adversarial attacks ?
Oct 17, 2024



Large language models (LLMs) inherit biases from their training data and alignment processes, influencing their responses in subtle ways. While many studies have examined these biases, little work has explored their robustness during interactions. In this paper, we introduce a novel approach where two instances of an LLM engage in self-debate, arguing opposing viewpoints to persuade a neutral version of the model. Through this, we evaluate how firmly biases hold and whether models are susceptible to reinforcing misinformation or shifting to harmful viewpoints. Our experiments span multiple LLMs of varying sizes, origins, and languages, providing deeper insights into bias persistence and flexibility across linguistic and cultural contexts.
GreekBART: The First Pretrained Greek Sequence-to-Sequence Model
Apr 03, 2023



The era of transfer learning has revolutionized the fields of Computer Vision and Natural Language Processing, bringing powerful pretrained models with exceptional performance across a variety of tasks. Specifically, Natural Language Processing tasks have been dominated by transformer-based language models. In Natural Language Inference and Natural Language Generation tasks, the BERT model and its variants, as well as the GPT model and its successors, demonstrated exemplary performance. However, the majority of these models are pretrained and assessed primarily for the English language or on a multilingual corpus. In this paper, we introduce GreekBART, the first Seq2Seq model based on BART-base architecture and pretrained on a large-scale Greek corpus. We evaluate and compare GreekBART against BART-random, Greek-BERT, and XLM-R on a variety of discriminative tasks. In addition, we examine its performance on two NLG tasks from GreekSUM, a newly introduced summarization dataset for the Greek language. The model, the code, and the new summarization dataset will be publicly available.
NLP Research and Resources at DaSciM, Ecole Polytechnique
Dec 01, 2021DaSciM (Data Science and Mining) part of LIX at Ecole Polytechnique, established in 2013 and since then producing research results in the area of large scale data analysis via methods of machine and deep learning. The group has been specifically active in the area of NLP and text mining with interesting results at methodological and resources level. Here follow our different contributions of interest to the AFIA community.
BERTweetFR : Domain Adaptation of Pre-Trained Language Models for French Tweets
Sep 21, 2021

We introduce BERTweetFR, the first large-scale pre-trained language model for French tweets. Our model is initialized using the general-domain French language model CamemBERT which follows the base architecture of RoBERTa. Experiments show that BERTweetFR outperforms all previous general-domain French language models on two downstream Twitter NLP tasks of offensiveness identification and named entity recognition. The dataset used in the offensiveness detection task is first created and annotated by our team, filling in the gap of such analytic datasets in French. We make our model publicly available in the transformers library with the aim of promoting future research in analytic tasks for French tweets.
Evaluation Of Word Embeddings From Large-Scale French Web Content
May 05, 2021

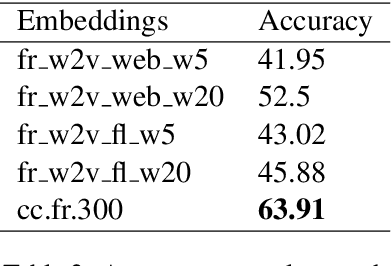
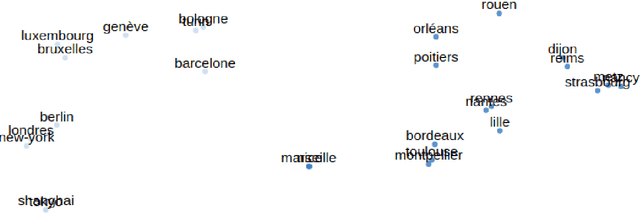
Distributed word representations are popularly used in many tasks in natural language processing, adding that pre-trained word vectors on huge text corpus achieved high performance in many different NLP tasks. This paper introduces multiple high quality word vectors for the French language where two of them are trained on huge crawled French data and the others are trained on an already existing French corpus. We also evaluate the quality of our proposed word vectors and the existing French word vectors on the French word analogy task. In addition, we do the evaluation on multiple real NLP tasks that show the important performance enhancement of the pre-trained word vectors compared to the existing and random ones. Finally, we created a demo web application to test and visualize the obtained word embeddings. The produced French word embeddings are available to the public, along with the fine-tuning code on the NLU tasks and the demo code.
How COVID-19 Is Changing Our Language : Detecting Semantic Shift in Twitter Word Embeddings
Feb 15, 2021
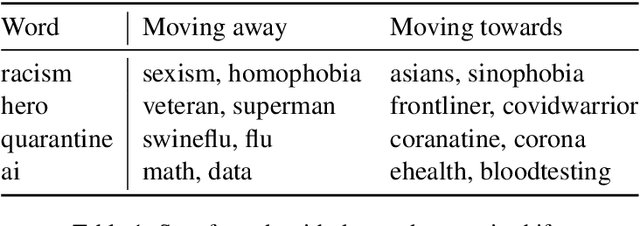
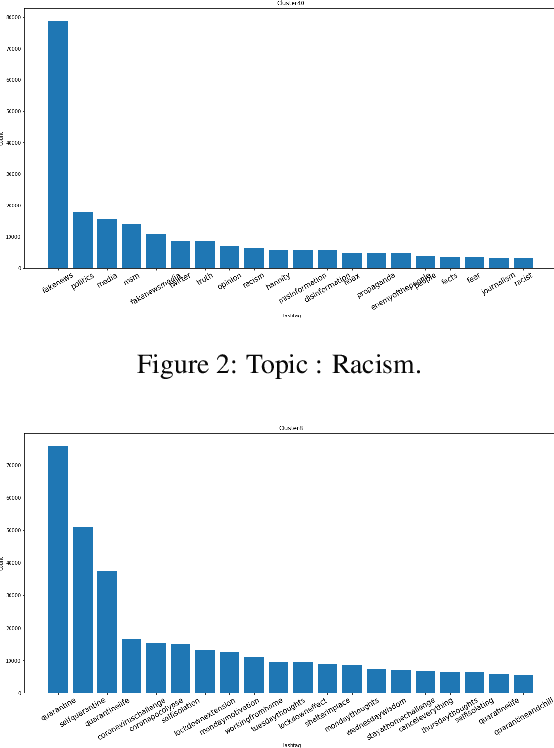
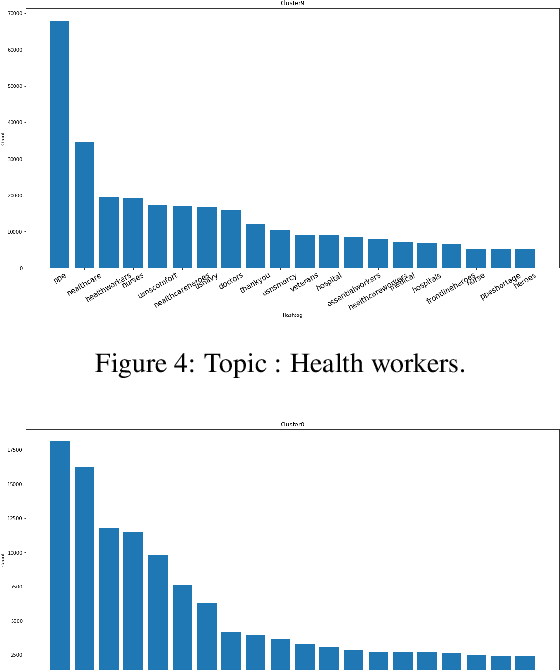
Words are malleable objects, influenced by events that are reflected in written texts. Situated in the global outbreak of COVID-19, our research aims at detecting semantic shifts in social media language triggered by the health crisis. With COVID-19 related big data extracted from Twitter, we train separate word embedding models for different time periods after the outbreak. We employ an alignment-based approach to compare these embeddings with a general-purpose Twitter embedding unrelated to COVID-19. We also compare our trained embeddings among them to observe diachronic evolution. Carrying out case studies on a set of words chosen by topic detection, we verify that our alignment approach is valid. Finally, we quantify the size of global semantic shift by a stability measure based on back-and-forth rotational alignment.
Performance in the Courtroom: Automated Processing and Visualization of Appeal Court Decisions in France
Jul 09, 2020

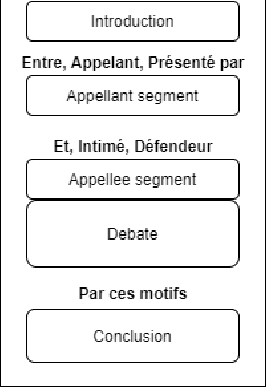
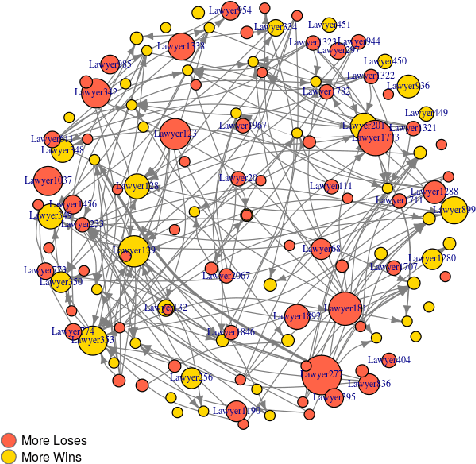
Artificial Intelligence techniques are already popular and important in the legal domain. We extract legal indicators from judicial judgment to decrease the asymmetry of information of the legal system and the access-to-justice gap. We use NLP methods to extract interesting entities/data from judgments to construct networks of lawyers and judgments. We propose metrics to rank lawyers based on their experience, wins/loss ratio and their importance in the network of lawyers. We also perform community detection in the network of judgments and propose metrics to represent the difficulty of cases capitalising on communities features.
Unsupervised Word Polysemy Quantification with Multiresolution Grids of Contextual Embeddings
Mar 23, 2020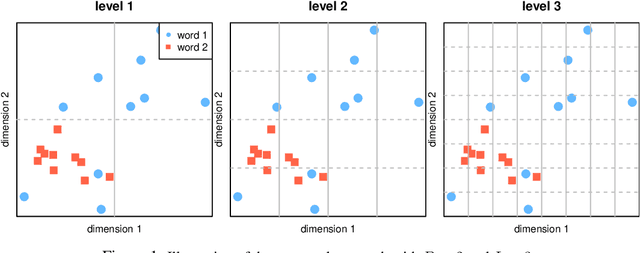

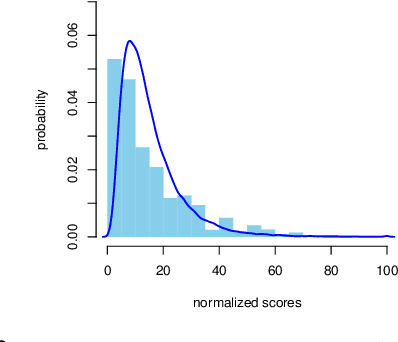

The number of senses of a given word, or polysemy, is a very subjective notion, which varies widely across annotators and resources. We propose a novel method to estimate polysemy, based on simple geometry in the contextual embedding space. Our approach is fully unsupervised and purely data-driven. We show through rigorous experiments that our rankings are well correlated (with strong statistical significance) with 6 different rankings derived from famous human-constructed resources such as WordNet, OntoNotes, Oxford, Wikipedia etc., for 6 different standard metrics. We also visualize and analyze the correlation between the human rankings. A valuable by-product of our method is the ability to sample, at no extra cost, sentences containing different senses of a given word. Finally, the fully unsupervised nature of our method makes it applicable to any language. Code and data are publicly available at https://github.com/ksipos/polysemy-assessment.