 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSE-UOI at SemEval-2026 Task 6: A Two-Stage Heterogeneous Ensemble with Deliberative Complexity Gating for Political Evasion Detection
Mar 12, 2026This paper describes our system for SemEval-2026 Task 6, which classifies clarity of responses in political interviews into three categories: Clear Reply, Ambivalent, and Clear Non-Reply. We propose a heterogeneous dual large language model (LLM) ensemble via self-consistency (SC) and weighted voting, and a novel post-hoc correction mechanism, Deliberative Complexity Gating (DCG). This mechanism uses cross-model behavioral signals and exploits the finding that an LLM response-length proxy correlates strongly with sample ambiguity. To further examine mechanisms for improving ambiguity detection, we evaluated multi-agent debate as an alternative strategy for increasing deliberative capacity. Unlike DCG, which adaptively gates reasoning using cross-model behavioral signals, debate increases agent count without increasing model diversity. Our solution achieved a Macro-F1 score of 0.85 on the evaluation set, securing 3rd place.
GreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek
Feb 05, 2026Large Language Models (LLMs) are commonly trained on multilingual corpora that include Greek, yet reliable evaluation benchmarks for Greek-particularly those based on authentic, native-sourced content-remain limited. Existing datasets are often machine-translated from English, failing to capture Greek linguistic and cultural characteristics. We introduce GreekMMLU, a native-sourced benchmark for massive multitask language understanding in Greek, comprising 21,805 multiple-choice questions across 45 subject areas, organized under a newly defined subject taxonomy and annotated with educational difficulty levels spanning primary to professional examinations. All questions are sourced or authored in Greek from academic, professional, and governmental exams. We publicly release 16,857 samples and reserve 4,948 samples for a private leaderboard to enable robust and contamination-resistant evaluation. Evaluations of over 80 open- and closed-source LLMs reveal substantial performance gaps between frontier and open-weight models, as well as between Greek-adapted models and general multilingual ones. Finally, we provide a systematic analysis of factors influencing performance-including model scale, adaptation, and prompting-and derive insights for improving LLM capabilities in Greek.
On the Lipschitz Continuity of Set Aggregation Functions and Neural Networks for Sets
May 30, 2025The Lipschitz constant of a neural network is connected to several important properties of the network such as its robustness and generalization. It is thus useful in many settings to estimate the Lipschitz constant of a model. Prior work has focused mainly on estimating the Lipschitz constant of multi-layer perceptrons and convolutional neural networks. Here we focus on data modeled as sets or multisets of vectors and on neural networks that can handle such data. These models typically apply some permutation invariant aggregation function, such as the sum, mean or max operator, to the input multisets to produce a single vector for each input sample. In this paper, we investigate whether these aggregation functions are Lipschitz continuous with respect to three distance functions for unordered multisets, and we compute their Lipschitz constants. In the general case, we find that each aggregation function is Lipschitz continuous with respect to only one of the three distance functions. Then, we build on these results to derive upper bounds on the Lipschitz constant of neural networks that can process multisets of vectors, while we also study their stability to perturbations and generalization under distribution shifts. To empirically verify our theoretical analysis, we conduct a series of experiments on datasets from different domains.
Leveraging LLMs for Translating and Classifying Mental Health Data
Oct 16, 2024

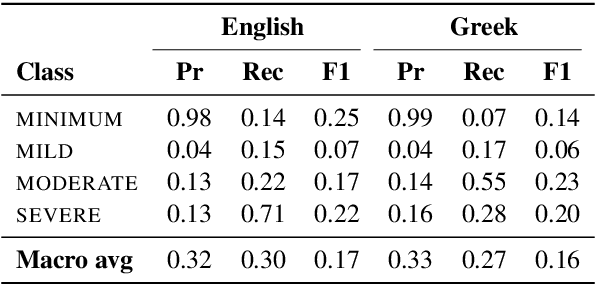

Large language models (LLMs) are increasingly used in medical fields. In mental health support, the early identification of linguistic markers associated with mental health conditions can provide valuable support to mental health professionals, and reduce long waiting times for patients. Despite the benefits of LLMs for mental health support, there is limited research on their application in mental health systems for languages other than English. Our study addresses this gap by focusing on the detection of depression severity in Greek through user-generated posts which are automatically translated from English. Our results show that GPT3.5-turbo is not very successful in identifying the severity of depression in English, and it has a varying performance in Greek as well. Our study underscores the necessity for further research, especially in languages with less resources. Also, careful implementation is necessary to ensure that LLMs are used effectively in mental health platforms, and human supervision remains crucial to avoid misdiagnosis.
Graph Reasoning with Large Language Models via Pseudo-code Prompting
Sep 26, 2024
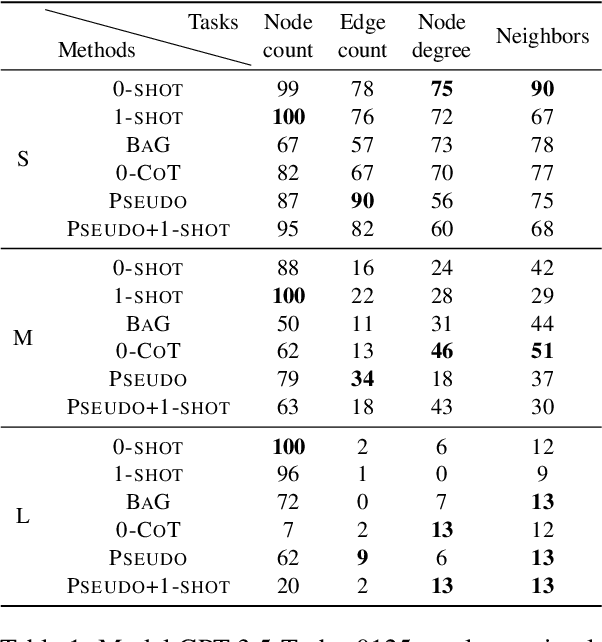
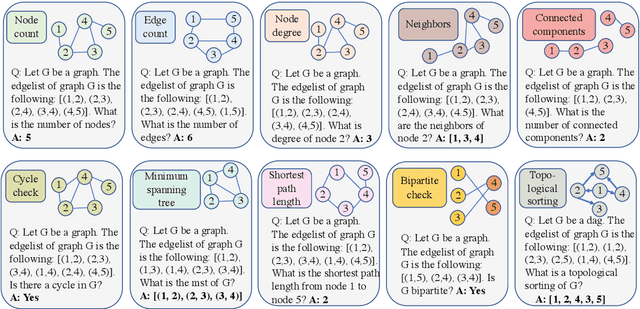
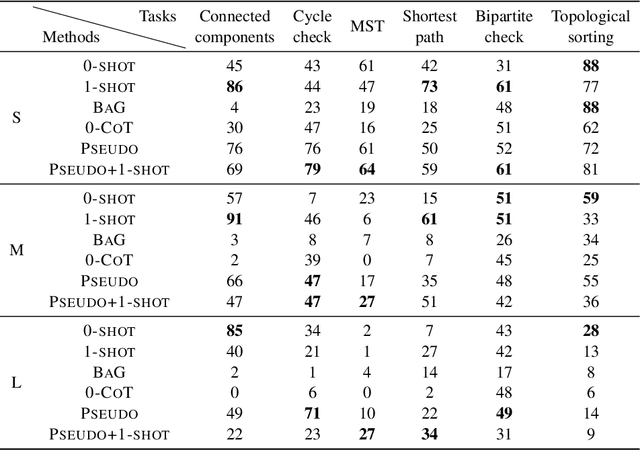
Large language models (LLMs) have recently achieved remarkable success in various reasoning tasks in the field of natural language processing. This success of LLMs has also motivated their use in graph-related tasks. Among others, recent work has explored whether LLMs can solve graph problems such as counting the number of connected components of a graph or computing the shortest path distance between two nodes. Although LLMs possess preliminary graph reasoning abilities, they might still struggle to solve some seemingly simple problems. In this paper, we investigate whether prompting via pseudo-code instructions can improve the performance of LLMs in solving graph problems. Our experiments demonstrate that using pseudo-code instructions generally improves the performance of all considered LLMs. The graphs, pseudo-code prompts, and evaluation code are publicly available.
Severity Prediction in Mental Health: LLM-based Creation, Analysis, Evaluation of a Novel Multilingual Dataset
Sep 25, 2024



Large Language Models (LLMs) are increasingly integrated into various medical fields, including mental health support systems. However, there is a gap in research regarding the effectiveness of LLMs in non-English mental health support applications. To address this problem, we present a novel multilingual adaptation of widely-used mental health datasets, translated from English into six languages (Greek, Turkish, French, Portuguese, German, and Finnish). This dataset enables a comprehensive evaluation of LLM performance in detecting mental health conditions and assessing their severity across multiple languages. By experimenting with GPT and Llama, we observe considerable variability in performance across languages, despite being evaluated on the same translated dataset. This inconsistency underscores the complexities inherent in multilingual mental health support, where language-specific nuances and mental health data coverage can affect the accuracy of the models. Through comprehensive error analysis, we emphasize the risks of relying exclusively on large language models (LLMs) in medical settings (e.g., their potential to contribute to misdiagnoses). Moreover, our proposed approach offers significant cost savings for multilingual tasks, presenting a major advantage for broad-scale implementation.
Towards Fine-Dining Recipe Generation with Generative Pre-trained Transformers
Sep 26, 2022



Food is essential to human survival. So much so that we have developed different recipes to suit our taste needs. In this work, we propose a novel way of creating new, fine-dining recipes from scratch using Transformers, specifically auto-regressive language models. Given a small dataset of food recipes, we try to train models to identify cooking techniques, propose novel recipes, and test the power of fine-tuning with minimal data.
Evaluation of Greek Word Embeddings
Apr 08, 2019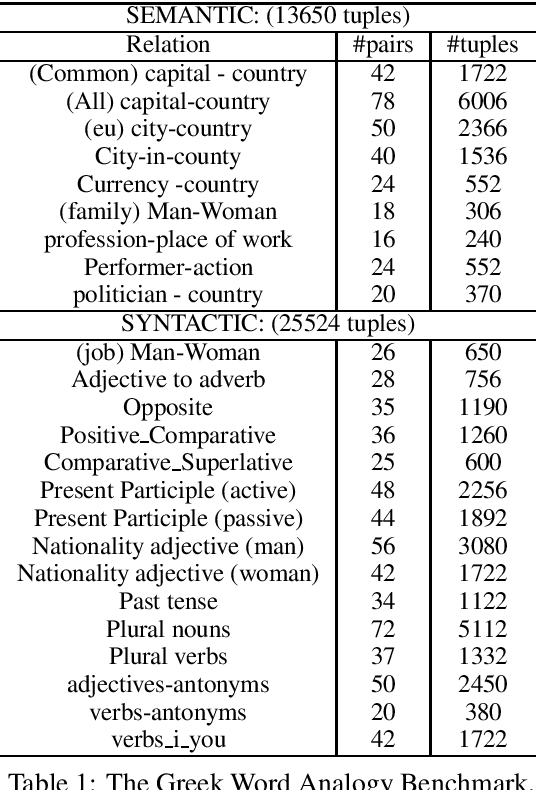



Since word embeddings have been the most popular input for many NLP tasks, evaluating their quality is of critical importance. Most research efforts are focusing on English word embeddings. This paper addresses the problem of constructing and evaluating such models for the Greek language. We created a new word analogy corpus considering the original English Word2vec word analogy corpus and some specific linguistic aspects of the Greek language as well. Moreover, we created a Greek version of WordSim353 corpora for a basic evaluation of word similarities. We tested seven word vector models and our evaluation showed that we are able to create meaningful representations. Last, we discovered that the morphological complexity of the Greek language and polysemy can influence the quality of the resulting word embeddings.
Rep the Set: Neural Networks for Learning Set Representations
Apr 03, 2019



In several domains, data objects can be decomposed into sets of simpler objects. It is then natural to represent each object as the set of its components or parts. Many conventional machine learning algorithms are unable to process this kind of representations, since sets may vary in cardinality and elements lack a meaningful ordering. In this paper, we present a new neural network architecture, called RepSet, that can handle examples that are represented as sets of vectors. The proposed model computes the correspondences between an input set and some hidden sets by solving a series of network flow problems. This representation is then fed to a standard neural network architecture to produce the output. The architecture allows end-to-end gradient-based learning. We demonstrate RepSet on classification tasks, including text categorization, and graph classification, and we show that the proposed neural network achieves performance better or comparable to state-of-the-art algorithms.
Word Embeddings from Large-Scale Greek Web Content
Oct 26, 2018Word embeddings are undoubtedly very useful components in many NLP tasks. In this paper, we present word embeddings and other linguistic resources trained on the largest to date digital Greek language corpus. We also present a live web tool for testing the Greek word embeddings, by offering "analogy", "similarity score" and "most similar words" functions. Through our explorer, one could interact with the Greek word vectors.