 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Maximize Influence
Aug 10, 2021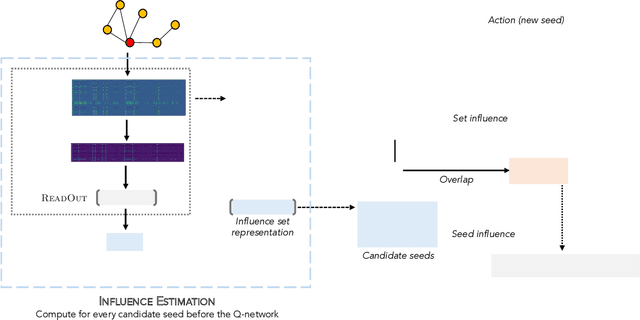


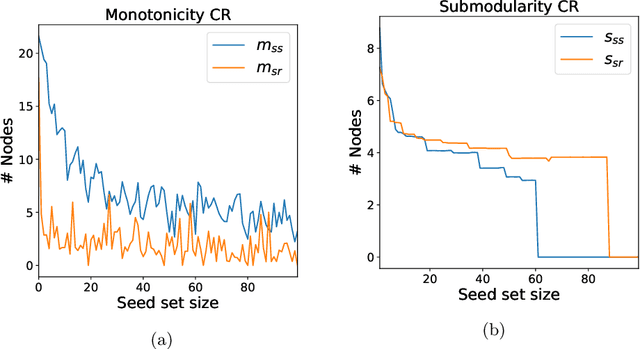
As the field of machine learning for combinatorial optimization advances, traditional problems are resurfaced and readdressed through this new perspective. The overwhelming majority of the literature focuses on small graph problems, while several real-world problems are devoted to large graphs. Here, we focus on two such problems that are related: influence estimation, a \#P-hard counting problem, and influence maximization, an NP-hard problem. We develop GLIE, a Graph Neural Network (GNN) that inherently parameterizes an upper bound of influence estimation and train it on small simulated graphs. Experiments show that GLIE can provide accurate predictions faster than the alternatives for graphs 10 times larger than the train set. More importantly, it can be used on arbitrary large graphs for influence maximization, as the predictions can rank effectively seed sets even when the accuracy deteriorates. To showcase this, we propose a version of a standard Influence Maximization (IM) algorithm where we substitute traditional influence estimation with the predictions of GLIE.We also transfer GLIE into a reinforcement learning model that learns how to choose seeds to maximize influence sequentially using GLIE's hidden representations and predictions. The final results show that the proposed methods surpasses a previous GNN-RL approach and perform on par with a state-of-the-art IM algorithm.
Predicting conversions in display advertising based on URL embeddings
Aug 28, 2020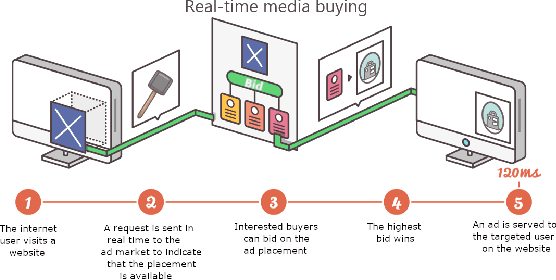
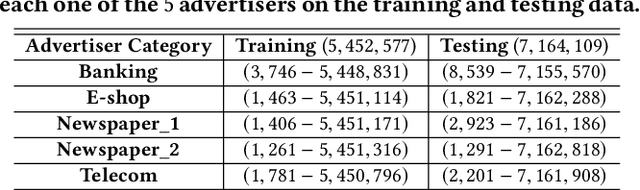
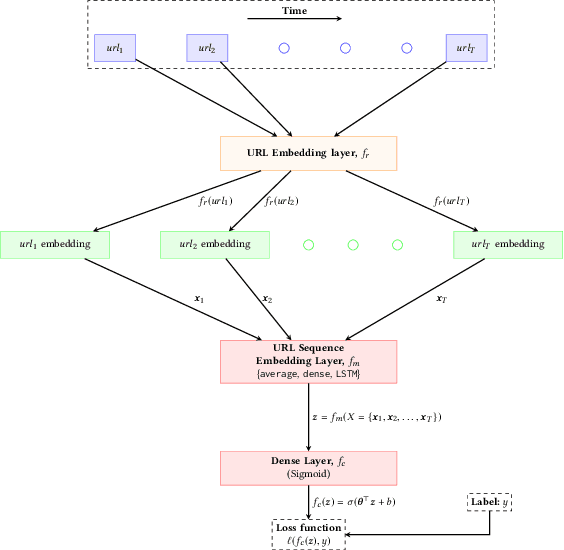
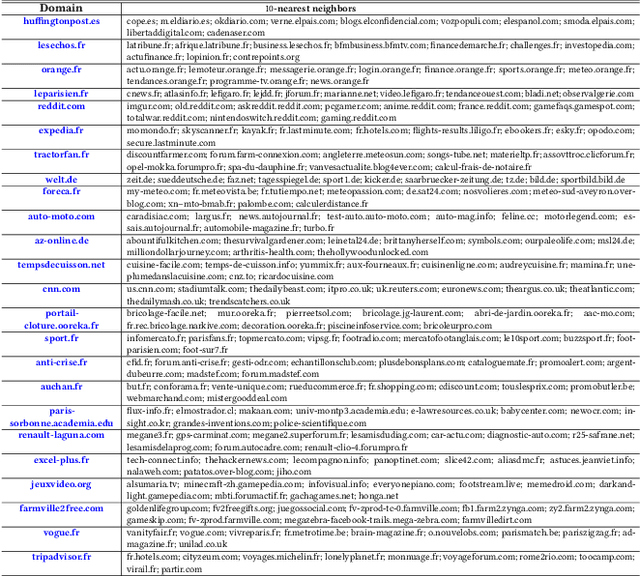
Online display advertising is growing rapidly in recent years thanks to the automation of the ad buying process. Real-time bidding (RTB) allows the automated trading of ad impressions between advertisers and publishers through real-time auctions. In order to increase the effectiveness of their campaigns, advertisers should deliver ads to the users who are highly likely to be converted (i.e., purchase, registration, website visit, etc.) in the near future. In this study, we introduce and examine different models for estimating the probability of a user converting, given their history of visited URLs. Inspired by natural language processing, we introduce three URL embedding models to compute semantically meaningful URL representations. To demonstrate the effectiveness of the different proposed representation and conversion prediction models, we have conducted experiments on real logged events collected from an advertising platform.
Randomised Bayesian Least-Squares Policy Iteration
Apr 06, 2019



We introduce Bayesian least-squares policy iteration (BLSPI), an off-policy, model-free, policy iteration algorithm that uses the Bayesian least-squares temporal-difference (BLSTD) learning algorithm to evaluate policies. An online variant of BLSPI has been also proposed, called randomised BLSPI (RBLSPI), that improves its policy based on an incomplete policy evaluation step. In online setting, the exploration-exploitation dilemma should be addressed as we try to discover the optimal policy by using samples collected by ourselves. RBLSPI exploits the advantage of BLSTD to quantify our uncertainty about the value function. Inspired by Thompson sampling, RBLSPI first samples a value function from a posterior distribution over value functions, and then selects actions based on the sampled value function. The effectiveness and the exploration abilities of RBLSPI are demonstrated experimentally in several environments.
Orthogonal Matching Pursuit for Text Classification
Oct 09, 2018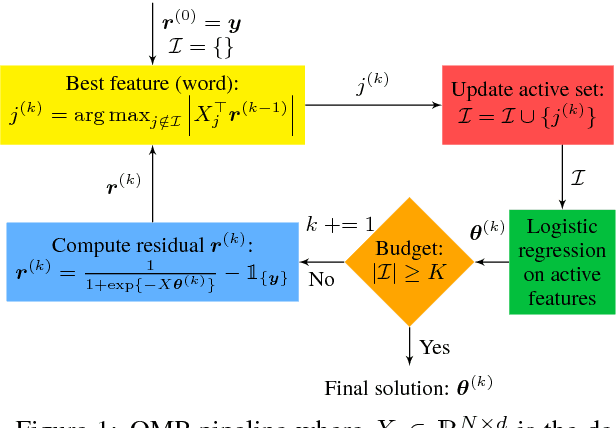


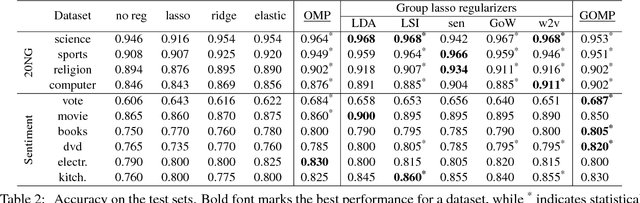
In text classification, the problem of overfitting arises due to the high dimensionality, making regularization essential. Although classic regularizers provide sparsity, they fail to return highly accurate models. On the contrary, state-of-the-art group-lasso regularizers provide better results at the expense of low sparsity. In this paper, we apply a greedy variable selection algorithm, called Orthogonal Matching Pursuit, for the text classification task. We also extend standard group OMP by introducing overlapping Group OMP to handle overlapping groups of features. Empirical analysis verifies that both OMP and overlapping GOMP constitute powerful regularizers, able to produce effective and very sparse models. Code and data are available online: https://github.com/y3nk0/OMP-for-Text-Classification .
A Bayesian Ensemble Regression Framework on the Angry Birds Game
Aug 25, 2014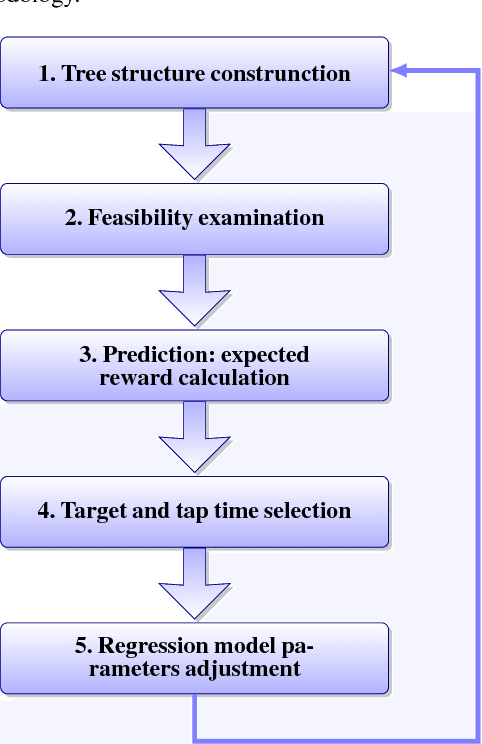
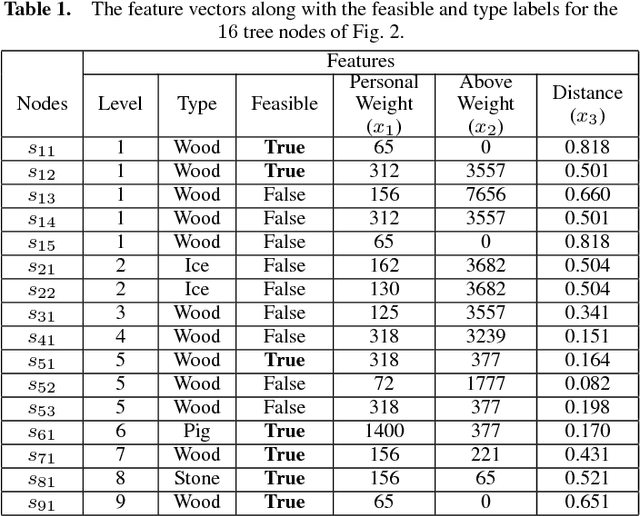
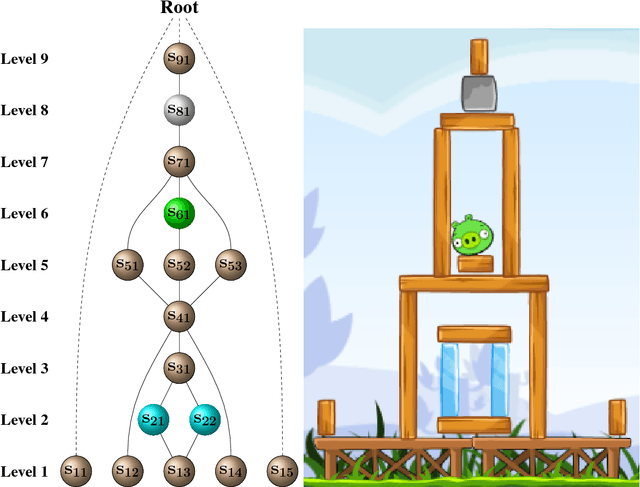
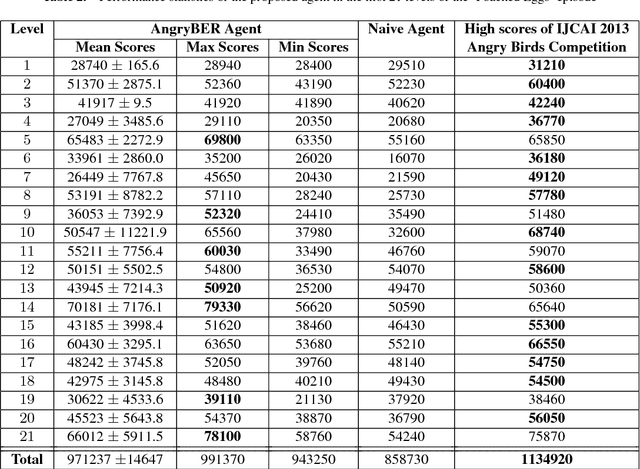
An ensemble inference mechanism is proposed on the Angry Birds domain. It is based on an efficient tree structure for encoding and representing game screenshots, where it exploits its enhanced modeling capability. This has the advantage to establish an informative feature space and modify the task of game playing to a regression analysis problem. To this direction, we assume that each type of object material and bird pair has its own Bayesian linear regression model. In this way, a multi-model regression framework is designed that simultaneously calculates the conditional expectations of several objects and makes a target decision through an ensemble of regression models. Learning procedure is performed according to an online estimation strategy for the model parameters. We provide comparative experimental results on several game levels that empirically illustrate the efficiency of the proposed methodology.
Cover Tree Bayesian Reinforcement Learning
May 02, 2014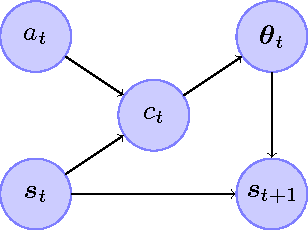
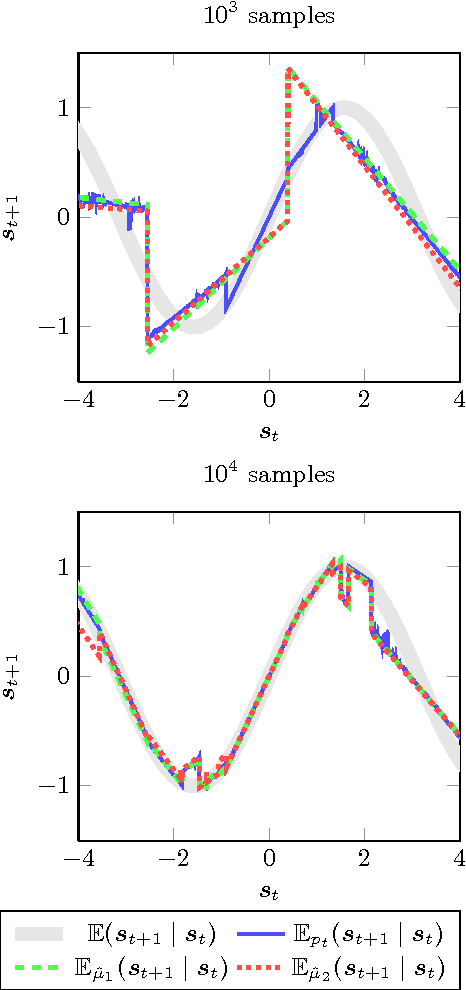
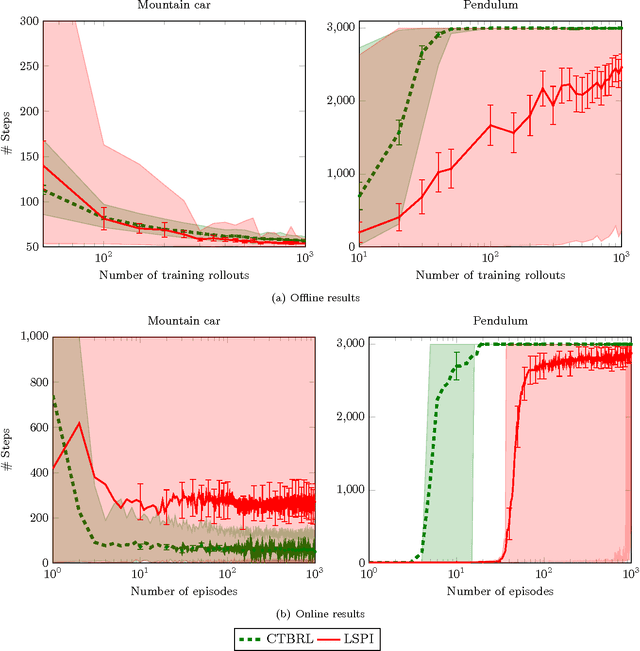
This paper proposes an online tree-based Bayesian approach for reinforcement learning. For inference, we employ a generalised context tree model. This defines a distribution on multivariate Gaussian piecewise-linear models, which can be updated in closed form. The tree structure itself is constructed using the cover tree method, which remains efficient in high dimensional spaces. We combine the model with Thompson sampling and approximate dynamic programming to obtain effective exploration policies in unknown environments. The flexibility and computational simplicity of the model render it suitable for many reinforcement learning problems in continuous state spaces. We demonstrate this in an experimental comparison with least squares policy iteration.
ABC Reinforcement Learning
Jun 28, 2013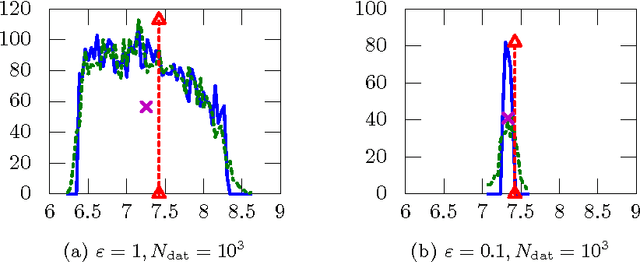
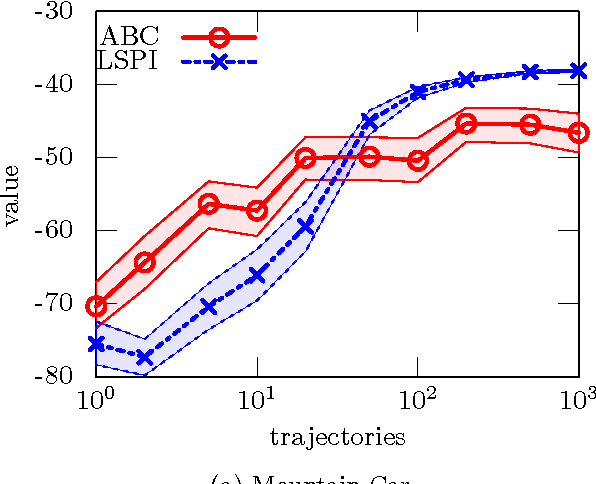
This paper introduces a simple, general framework for likelihood-free Bayesian reinforcement learning, through Approximate Bayesian Computation (ABC). The main advantage is that we only require a prior distribution on a class of simulators (generative models). This is useful in domains where an analytical probabilistic model of the underlying process is too complex to formulate, but where detailed simulation models are available. ABC-RL allows the use of any Bayesian reinforcement learning technique, even in this case. In addition, it can be seen as an extension of rollout algorithms to the case where we do not know what the correct model to draw rollouts from is. We experimentally demonstrate the potential of this approach in a comparison with LSPI. Finally, we introduce a theorem showing that ABC is a sound methodology in principle, even when non-sufficient statistics are used.