 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-change Aware CRF for Dialogue Act Classification
Apr 06, 2020
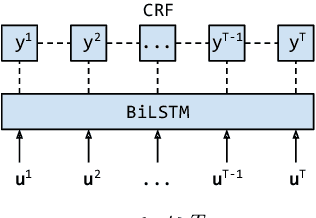
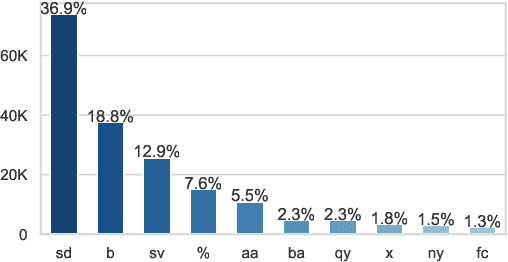
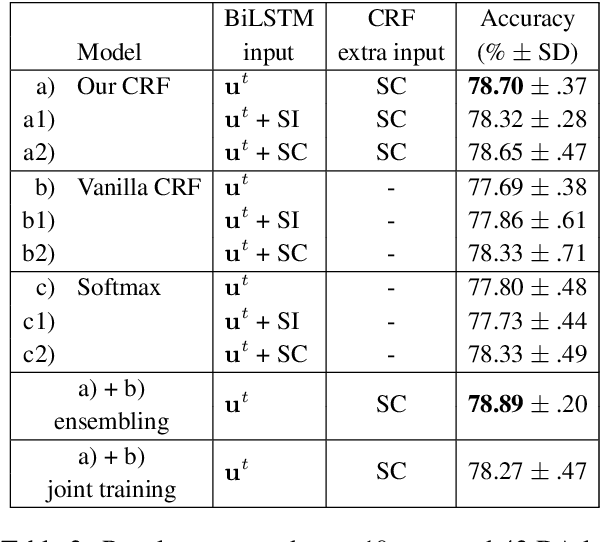
Recent work in Dialogue Act (DA) classification approaches the task as a sequence labeling problem, using neural network models coupled with a Conditional Random Field (CRF) as the last layer. CRF models the conditional probability of the target DA label sequence given the input utterance sequence. However, the task involves another important input sequence, that of speakers, which is ignored by previous work. To address this limitation, this paper proposes a simple modification of the CRF layer that takes speaker-change into account. Experiments on the SwDA corpus show that our modified CRF layer outperforms the original one, with very wide margins for some DA labels. Further, visualizations demonstrate that our CRF layer can learn meaningful, sophisticated transition patterns between DA label pairs conditioned on speaker-change in an end-to-end way. Code is publicly available.
Bidirectional Context-Aware Hierarchical Attention Network for Document Understanding
Aug 16, 2019


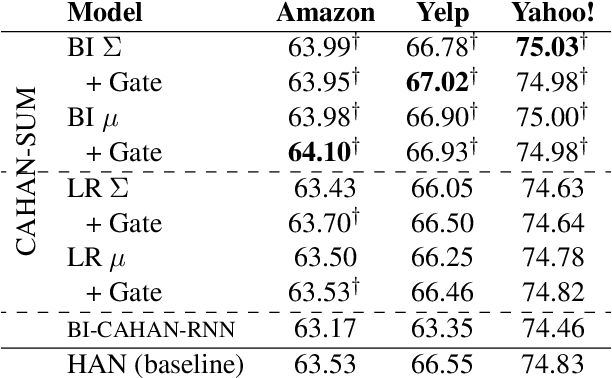
The Hierarchical Attention Network (HAN) has made great strides, but it suffers a major limitation: at level 1, each sentence is encoded in complete isolation. In this work, we propose and compare several modifications of HAN in which the sentence encoder is able to make context-aware attentional decisions (CAHAN). Furthermore, we propose a bidirectional document encoder that processes the document forwards and backwards, using the preceding and following sentences as context. Experiments on three large-scale sentiment and topic classification datasets show that the bidirectional version of CAHAN outperforms HAN everywhere, with only a modest increase in computation time. While results are promising, we expect the superiority of CAHAN to be even more evident on tasks requiring a deeper understanding of the input documents, such as abstractive summarization. Code is publicly available.
Energy-based Self-attentive Learning of Abstractive Communities for Spoken Language Understanding
Apr 20, 2019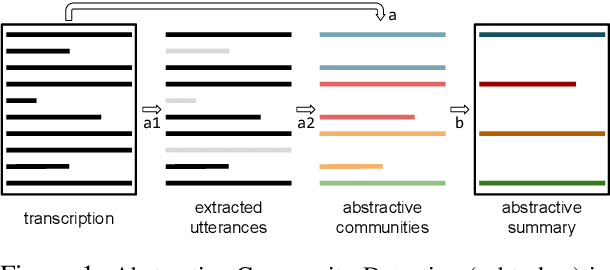

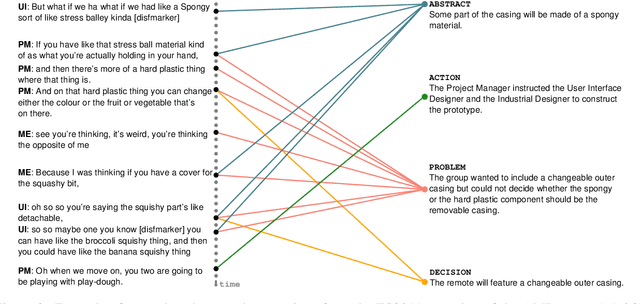
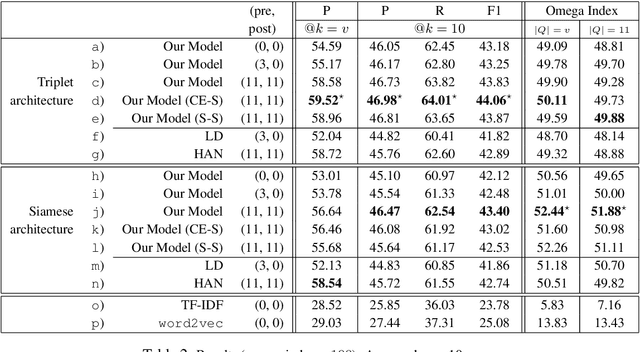
Abstractive Community Detection is an important Spoken Language Understanding task, whose goal is to group utterances in a conversation according to whether they can be jointly summarized by a common abstractive sentence. This paper provides a novel approach to this task. We first introduce a neural contextual utterance encoder featuring three types of self-attention mechanisms. We then evaluate it against multiple baselines within the powerful siamese and triplet energy-based meta-architectures. Moreover, we propose a general sampling scheme that enables the triplet architecture to capture subtle clustering patterns, such as overlapping and nested communities. Experiments on the AMI corpus show that our system improves on the state-of-the-art and that our triplet sampling scheme is effective. Code and data are publicly available.
Kernel Graph Convolutional Neural Networks
Sep 07, 2018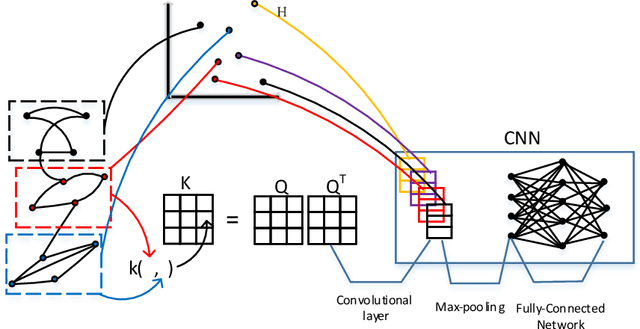


Graph kernels have been successfully applied to many graph classification problems. Typically, a kernel is first designed, and then an SVM classifier is trained based on the features defined implicitly by this kernel. This two-stage approach decouples data representation from learning, which is suboptimal. On the other hand, Convolutional Neural Networks (CNNs) have the capability to learn their own features directly from the raw data during training. Unfortunately, they cannot handle irregular data such as graphs. We address this challenge by using graph kernels to embed meaningful local neighborhoods of the graphs in a continuous vector space. A set of filters is then convolved with these patches, pooled, and the output is then passed to a feedforward network. With limited parameter tuning, our approach outperforms strong baselines on 7 out of 10 benchmark datasets.
Unsupervised Abstractive Meeting Summarization with Multi-Sentence Compression and Budgeted Submodular Maximization
May 14, 2018
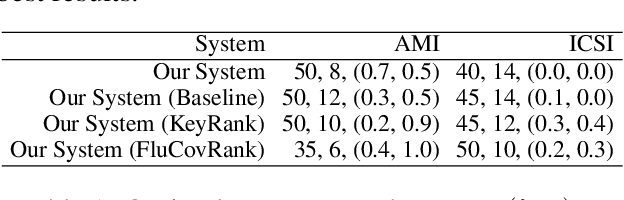
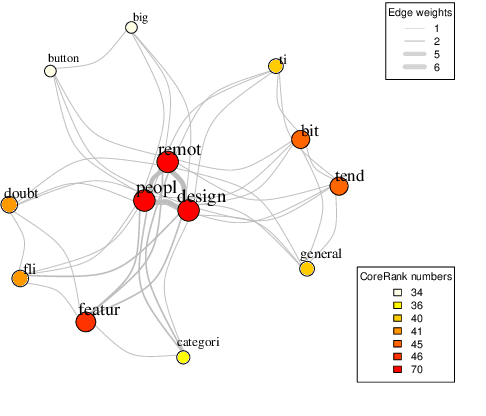
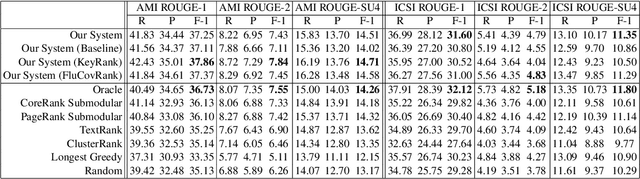
We introduce a novel graph-based framework for abstractive meeting speech summarization that is fully unsupervised and does not rely on any annotations. Our work combines the strengths of multiple recent approaches while addressing their weaknesses. Moreover, we leverage recent advances in word embeddings and graph degeneracy applied to NLP to take exterior semantic knowledge into account, and to design custom diversity and informativeness measures. Experiments on the AMI and ICSI corpus show that our system improves on the state-of-the-art. Code and data are publicly available, and our system can be interactively tested.
Graph Classification with 2D Convolutional Neural Networks
Feb 12, 2018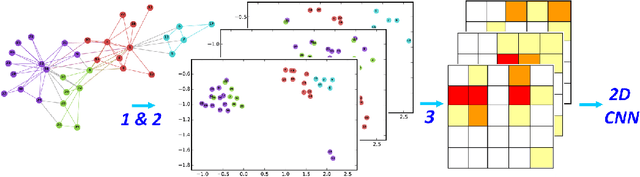
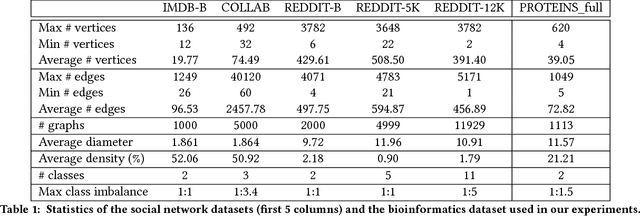
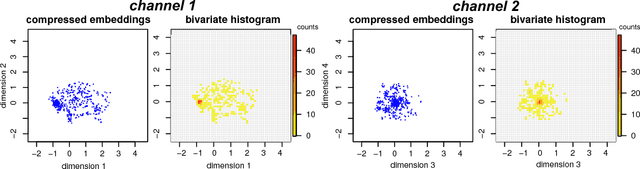

Graph learning is currently dominated by graph kernels, which, while powerful, suffer some significant limitations. Convolutional Neural Networks (CNNs) offer a very appealing alternative, but processing graphs with CNNs is not trivial. To address this challenge, many sophisticated extensions of CNNs have recently been introduced. In this paper, we reverse the problem: rather than proposing yet another graph CNN model, we introduce a novel way to represent graphs as multi-channel image-like structures that allows them to be handled by vanilla 2D CNNs. Experiments reveal that our method is more accurate than state-of-the-art graph kernels and graph CNNs on 4 out of 6 real-world datasets (with and without continuous node attributes), and close elsewhere. Our approach is also preferable to graph kernels in terms of time complexity. Code and data are publicly available.