 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinTO Audio and Textual Datasets to Train and Evaluate Automatic Speech Recognition in Tunisian Arabic Dialect
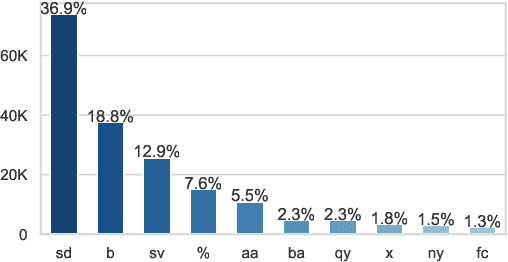
Apr 03, 2025Developing Automatic Speech Recognition (ASR) systems for Tunisian Arabic Dialect is challenging due to the dialect's linguistic complexity and the scarcity of annotated speech datasets. To address these challenges, we propose the LinTO audio and textual datasets -- comprehensive resources that capture phonological and lexical features of Tunisian Arabic Dialect. These datasets include a variety of texts from numerous sources and real-world audio samples featuring diverse speakers and code-switching between Tunisian Arabic Dialect and English or French. By providing high-quality audio paired with precise transcriptions, the LinTO audio and textual datasets aim to provide qualitative material to build and benchmark ASR systems for the Tunisian Arabic Dialect. Keywords -- Tunisian Arabic Dialect, Speech-to-Text, Low-Resource Languages, Audio Data Augmentation
The Lucie-7B LLM and the Lucie Training Dataset: Open resources for multilingual language generation
Mar 15, 2025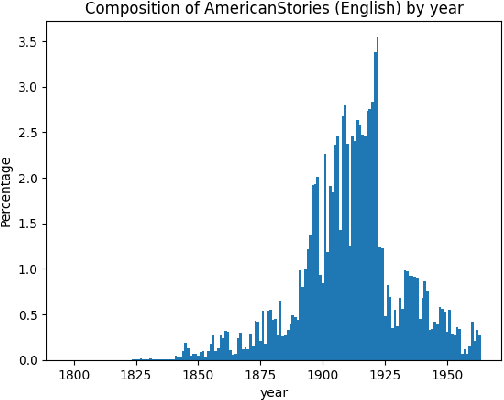

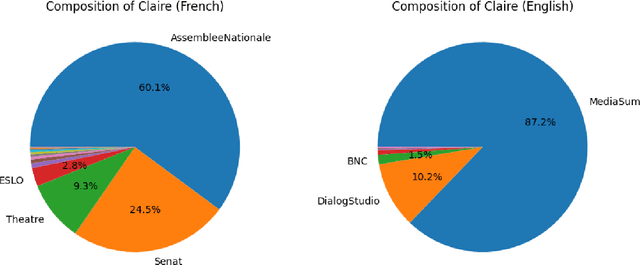
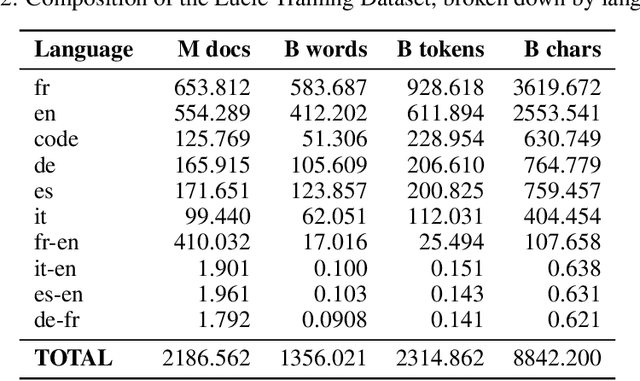
We present both the Lucie Training Dataset and the Lucie-7B foundation model. The Lucie Training Dataset is a multilingual collection of textual corpora centered around French and designed to offset anglo-centric biases found in many datasets for large language model pretraining. Its French data is pulled not only from traditional web sources, but also from French cultural heritage documents, filling an important gap in modern datasets. Beyond French, which makes up the largest share of the data, we added documents to support several other European languages, including English, Spanish, German, and Italian. Apart from its value as a resource for French language and culture, an important feature of this dataset is that it prioritizes data rights by minimizing copyrighted material. In addition, building on the philosophy of past open projects, it is redistributed in the form used for training and its processing is described on Hugging Face and GitHub. The Lucie-7B foundation model is trained on equal amounts of data in French and English -- roughly 33% each -- in an effort to better represent cultural aspects of French-speaking communities. We also describe two instruction fine-tuned models, Lucie-7B-Instruct-v1.1 and Lucie-7B-Instruct-human-data, which we release as demonstrations of Lucie-7B in use. These models achieve promising results compared to state-of-the-art models, demonstrating that an open approach prioritizing data rights can still deliver strong performance. We see these models as an initial step toward developing more performant, aligned models in the near future. Model weights for Lucie-7B and the Lucie instruct models, along with intermediate checkpoints for the former, are published on Hugging Face, while model training and data preparation code is available on GitHub. This makes Lucie-7B one of the first OSI compliant language models according to the new OSI definition.
The Claire French Dialogue Dataset
Nov 28, 2023We present the Claire French Dialogue Dataset (CFDD), a resource created by members of LINAGORA Labs in the context of the OpenLLM France initiative. CFDD is a corpus containing roughly 160 million words from transcripts and stage plays in French that we have assembled and publicly released in an effort to further the development of multilingual, open source language models. This paper describes the 24 individual corpora of which CFDD is composed and provides links and citations to their original sources. It also provides our proposed breakdown of the full CFDD dataset into eight categories of subcorpora and describes the process we followed to standardize the format of the final dataset. We conclude with a discussion of similar work and future directions.
Speaker-change Aware CRF for Dialogue Act Classification
Apr 06, 2020
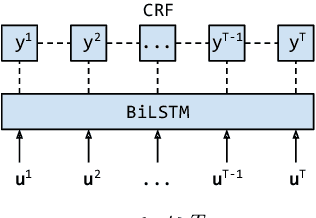
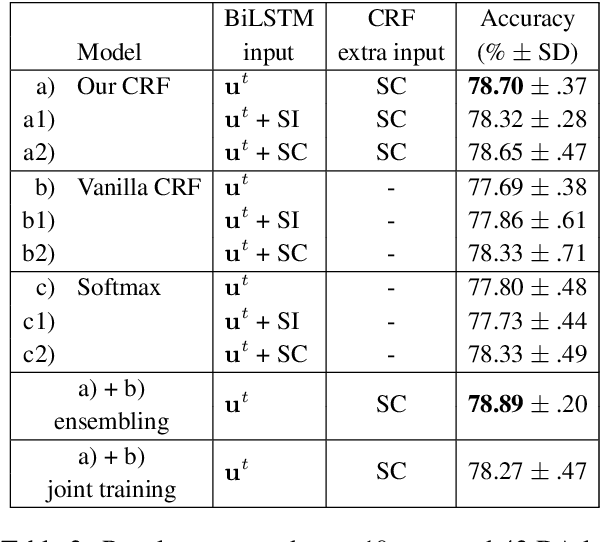
Recent work in Dialogue Act (DA) classification approaches the task as a sequence labeling problem, using neural network models coupled with a Conditional Random Field (CRF) as the last layer. CRF models the conditional probability of the target DA label sequence given the input utterance sequence. However, the task involves another important input sequence, that of speakers, which is ignored by previous work. To address this limitation, this paper proposes a simple modification of the CRF layer that takes speaker-change into account. Experiments on the SwDA corpus show that our modified CRF layer outperforms the original one, with very wide margins for some DA labels. Further, visualizations demonstrate that our CRF layer can learn meaningful, sophisticated transition patterns between DA label pairs conditioned on speaker-change in an end-to-end way. Code is publicly available.
Energy-based Self-attentive Learning of Abstractive Communities for Spoken Language Understanding
Apr 20, 2019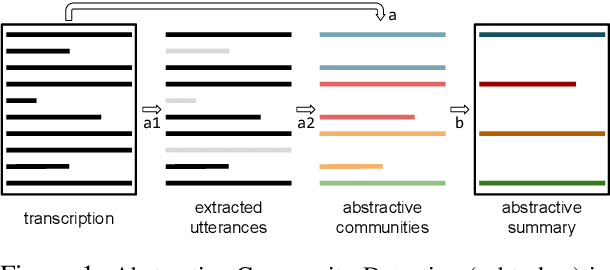

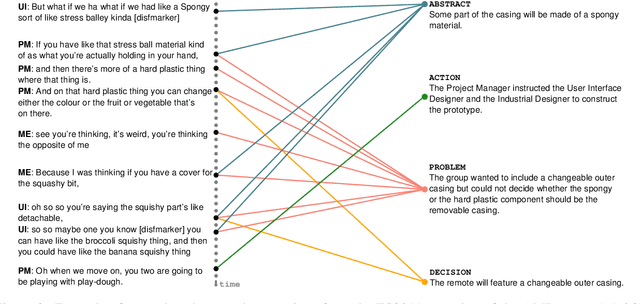
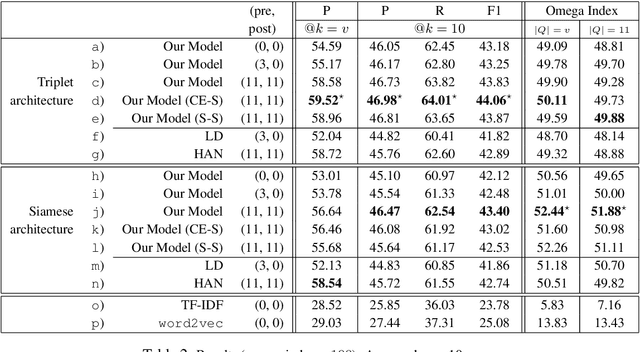
Abstractive Community Detection is an important Spoken Language Understanding task, whose goal is to group utterances in a conversation according to whether they can be jointly summarized by a common abstractive sentence. This paper provides a novel approach to this task. We first introduce a neural contextual utterance encoder featuring three types of self-attention mechanisms. We then evaluate it against multiple baselines within the powerful siamese and triplet energy-based meta-architectures. Moreover, we propose a general sampling scheme that enables the triplet architecture to capture subtle clustering patterns, such as overlapping and nested communities. Experiments on the AMI corpus show that our system improves on the state-of-the-art and that our triplet sampling scheme is effective. Code and data are publicly available.
Unsupervised Abstractive Meeting Summarization with Multi-Sentence Compression and Budgeted Submodular Maximization
May 14, 2018
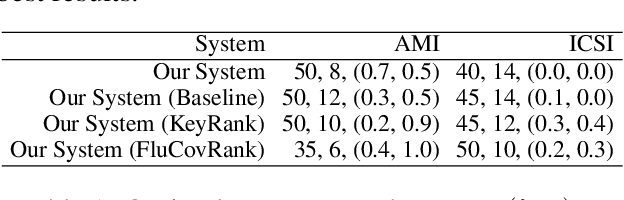
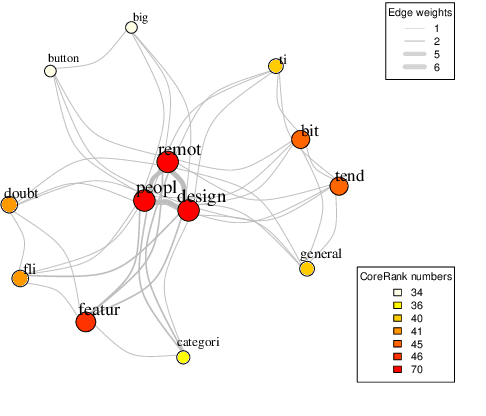
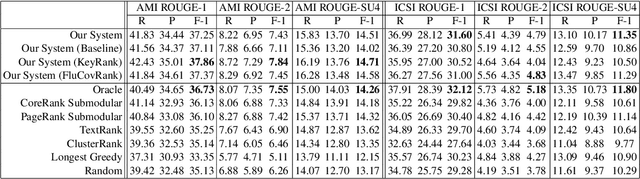
We introduce a novel graph-based framework for abstractive meeting speech summarization that is fully unsupervised and does not rely on any annotations. Our work combines the strengths of multiple recent approaches while addressing their weaknesses. Moreover, we leverage recent advances in word embeddings and graph degeneracy applied to NLP to take exterior semantic knowledge into account, and to design custom diversity and informativeness measures. Experiments on the AMI and ICSI corpus show that our system improves on the state-of-the-art. Code and data are publicly available, and our system can be interactively tested.
Knowledge-based system for collaborative process specification
Sep 30, 2015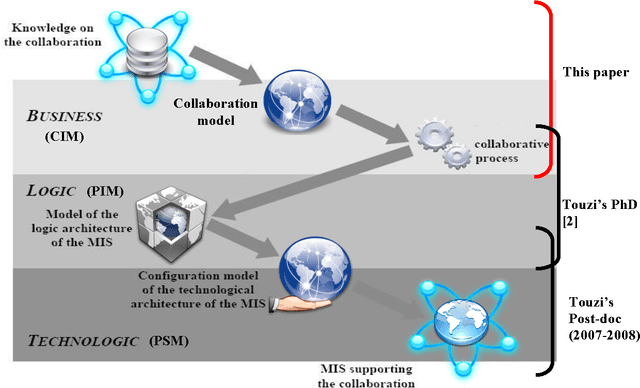
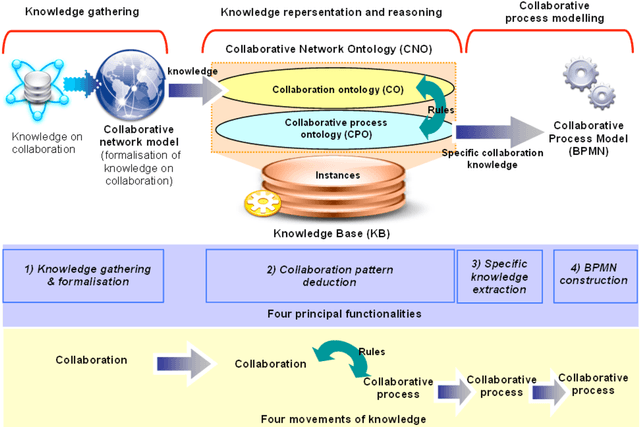
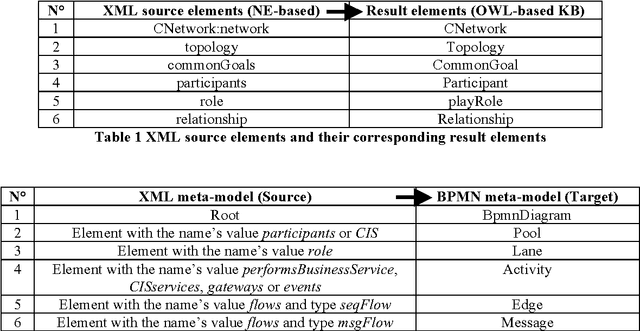
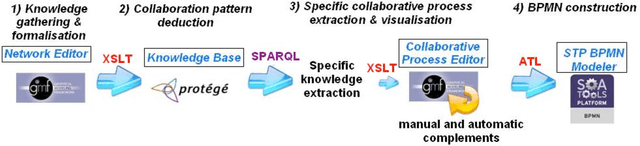
This paper presents an ontology-based approach for the design of a collaborative business process model (CBP). This CBP is considered as a specification of needs in order to build a collaboration information system (CIS) for a network of organisations. The study is a part of a model driven engineering approach of the CIS in a specific enterprise interoperability framework that will be summarised. An adaptation of the Business Process Modeling Notation (BPMN) is used to represent the CBP model. We develop a knowledge-based system (KbS) which is composed of three main parts: knowledge gathering, knowledge representation and reasoning, and collaborative business process modelling. The first part starts from a high abstraction level where knowledge from business partners is captured. A collaboration ontology is defined in order to provide a structure to store and use the knowledge captured. In parallel, we try to reuse generic existing knowledge about business processes from the MIT Process Handbook repository. This results in a collaboration process ontology that is also described. A set of rules is defined in order to extract knowledge about fragments of the CBP model from the two previous ontologies. These fragments are finally assembled in the third part of the KbS. A prototype of the KbS has been developed in order to implement and support this approach. The prototype is a computer-aided design tool of the CBP. In this paper, we will present the theoretical aspects of each part of this KbS as well as the tools that we developed and used in order to support its functionalities.
* \<10.1016/j.compind.2009.10.012\>