 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in the Mirror : Are LLMs opinions robust to their own adversarial attacks ?
Oct 17, 2024



Large language models (LLMs) inherit biases from their training data and alignment processes, influencing their responses in subtle ways. While many studies have examined these biases, little work has explored their robustness during interactions. In this paper, we introduce a novel approach where two instances of an LLM engage in self-debate, arguing opposing viewpoints to persuade a neutral version of the model. Through this, we evaluate how firmly biases hold and whether models are susceptible to reinforcing misinformation or shifting to harmful viewpoints. Our experiments span multiple LLMs of varying sizes, origins, and languages, providing deeper insights into bias persistence and flexibility across linguistic and cultural contexts.
Leveraging Discourse Structure for Extractive Meeting Summarization
May 21, 2024We introduce an extractive summarization system for meetings that leverages discourse structure to better identify salient information from complex multi-party discussions. Using discourse graphs to represent semantic relations between the contents of utterances in a meeting, we train a GNN-based node classification model to select the most important utterances, which are then combined to create an extractive summary. Experimental results on AMI and ICSI demonstrate that our approach surpasses existing text-based and graph-based extractive summarization systems, as measured by both classification and summarization metrics. Additionally, we conduct ablation studies on discourse structure and relation type to provide insights for future NLP applications leveraging discourse analysis theory.
FREDSum: A Dialogue Summarization Corpus for French Political Debates
Dec 08, 2023Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. The majority of research has focused on written documents, however, neglecting the problem of multi-party dialogue summarization. In this paper, we present a dataset of French political debates for the purpose of enhancing resources for multi-lingual dialogue summarization. Our dataset consists of manually transcribed and annotated political debates, covering a range of topics and perspectives. We highlight the importance of high quality transcription and annotations for training accurate and effective dialogue summarization models, and emphasize the need for multilingual resources to support dialogue summarization in non-English languages. We also provide baseline experiments using state-of-the-art methods, and encourage further research in this area to advance the field of dialogue summarization. Our dataset will be made publicly available for use by the research community.
The Claire French Dialogue Dataset
Nov 28, 2023We present the Claire French Dialogue Dataset (CFDD), a resource created by members of LINAGORA Labs in the context of the OpenLLM France initiative. CFDD is a corpus containing roughly 160 million words from transcripts and stage plays in French that we have assembled and publicly released in an effort to further the development of multilingual, open source language models. This paper describes the 24 individual corpora of which CFDD is composed and provides links and citations to their original sources. It also provides our proposed breakdown of the full CFDD dataset into eight categories of subcorpora and describes the process we followed to standardize the format of the final dataset. We conclude with a discussion of similar work and future directions.
Automatic Analysis of Substantiation in Scientific Peer Reviews
Nov 20, 2023With the increasing amount of problematic peer reviews in top AI conferences, the community is urgently in need of automatic quality control measures. In this paper, we restrict our attention to substantiation -- one popular quality aspect indicating whether the claims in a review are sufficiently supported by evidence -- and provide a solution automatizing this evaluation process. To achieve this goal, we first formulate the problem as claim-evidence pair extraction in scientific peer reviews, and collect SubstanReview, the first annotated dataset for this task. SubstanReview consists of 550 reviews from NLP conferences annotated by domain experts. On the basis of this dataset, we train an argument mining system to automatically analyze the level of substantiation in peer reviews. We also perform data analysis on the SubstanReview dataset to obtain meaningful insights on peer reviewing quality in NLP conferences over recent years.
Abstractive Meeting Summarization: A Survey
Aug 08, 2022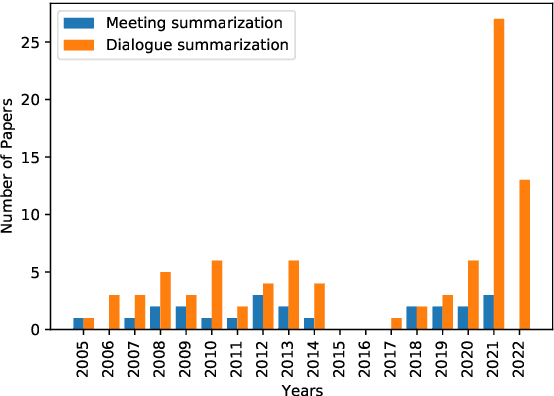
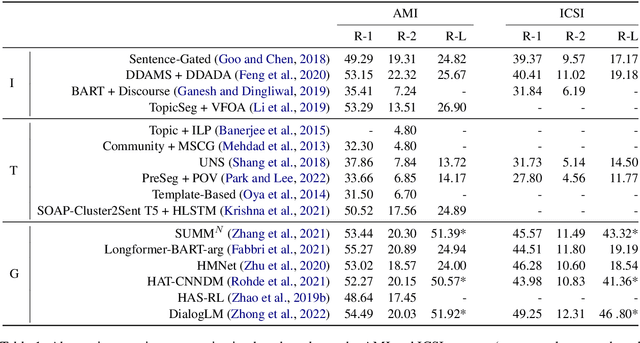
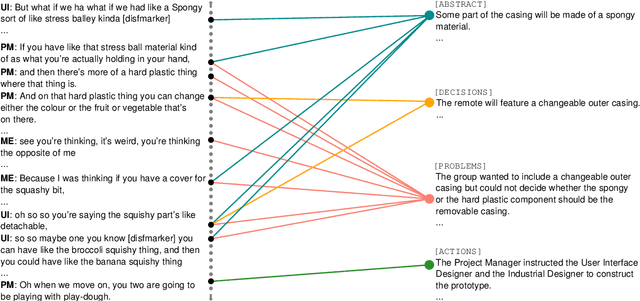
Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. While the majority of research has focused on written documents, we have observed an increasing interest in the summarization of dialogues and multi-party conversation over the past few years. A system that could reliably transform the audio or transcript of a human conversation into an abridged version that homes in on the most important points of the discussion would be valuable in a wide variety of real-world contexts, from business meetings to medical consultations to customer service calls. This paper focuses on abstractive summarization for multi-party meetings, providing a survey of the challenges, datasets and systems relevant to this task and a discussion of promising directions for future study.
Political Communities on Twitter: Case Study of the 2022 French Presidential Election
Apr 15, 2022
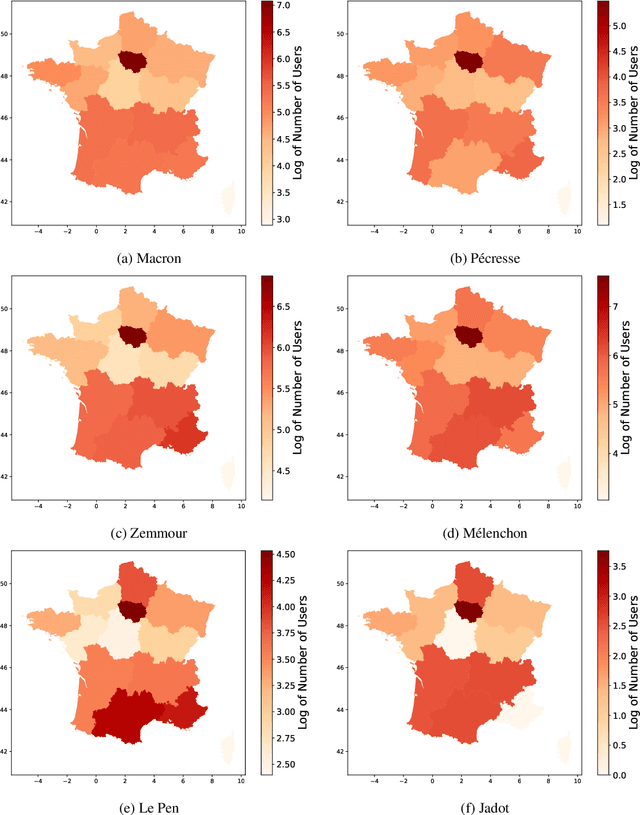
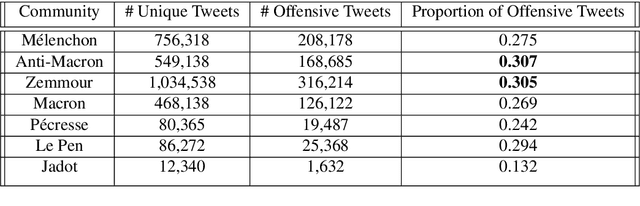
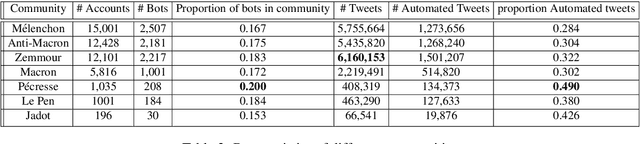
With the significant increase in users on social media platforms, a new means of political campaigning has appeared. Twitter and Facebook are now notable campaigning tools during elections. Indeed, the candidates and their parties now take to the internet to interact and spread their ideas. In this paper, we aim to identify political communities formed on Twitter during the 2022 French presidential election and analyze each respective community. We create a large-scale Twitter dataset containing 1.2 million users and 62.6 million tweets that mention keywords relevant to the election. We perform community detection on a retweet graph of users and propose an in-depth analysis of the stance of each community. Finally, we attempt to detect offensive tweets and automatic bots, comparing across communities in order to gain insight into each candidate's supporter demographics and online campaign strategy.
BERTweetFR : Domain Adaptation of Pre-Trained Language Models for French Tweets
Sep 21, 2021

We introduce BERTweetFR, the first large-scale pre-trained language model for French tweets. Our model is initialized using the general-domain French language model CamemBERT which follows the base architecture of RoBERTa. Experiments show that BERTweetFR outperforms all previous general-domain French language models on two downstream Twitter NLP tasks of offensiveness identification and named entity recognition. The dataset used in the offensiveness detection task is first created and annotated by our team, filling in the gap of such analytic datasets in French. We make our model publicly available in the transformers library with the aim of promoting future research in analytic tasks for French tweets.