 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEA-LIST at CheckThat! 2025: Evaluating LLMs as Detectors of Bias and Opinion in Text
Jul 10, 2025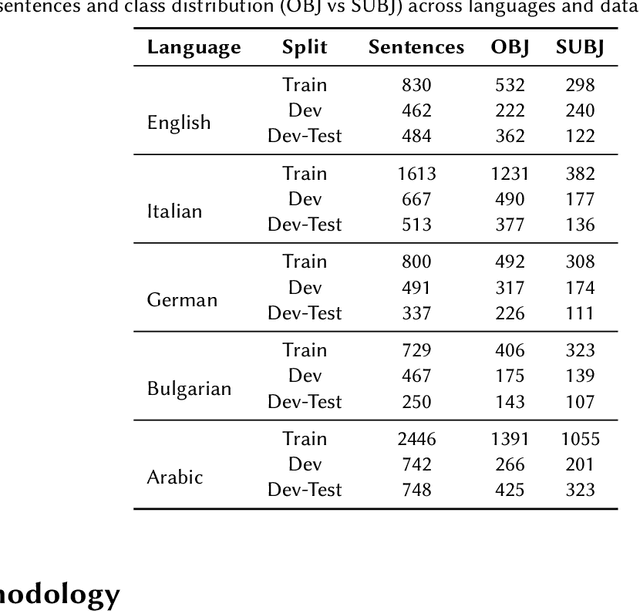



This paper presents a competitive approach to multilingual subjectivity detection using large language models (LLMs) with few-shot prompting. We participated in Task 1: Subjectivity of the CheckThat! 2025 evaluation campaign. We show that LLMs, when paired with carefully designed prompts, can match or outperform fine-tuned smaller language models (SLMs), particularly in noisy or low-quality data settings. Despite experimenting with advanced prompt engineering techniques, such as debating LLMs and various example selection strategies, we found limited benefit beyond well-crafted standard few-shot prompts. Our system achieved top rankings across multiple languages in the CheckThat! 2025 subjectivity detection task, including first place in Arabic and Polish, and top-four finishes in Italian, English, German, and multilingual tracks. Notably, our method proved especially robust on the Arabic dataset, likely due to its resilience to annotation inconsistencies. These findings highlight the effectiveness and adaptability of LLM-based few-shot learning for multilingual sentiment tasks, offering a strong alternative to traditional fine-tuning, particularly when labeled data is scarce or inconsistent.
Decompositional Reasoning for Graph Retrieval with Large Language Models
Jun 16, 2025

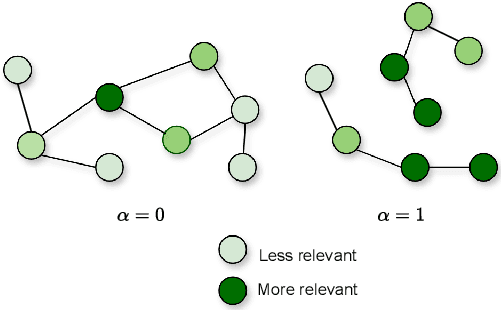

Large Language Models (LLMs) excel at many NLP tasks, but struggle with multi-hop reasoning and factual consistency, limiting their effectiveness on knowledge-intensive tasks like complex question answering (QA). Linking Knowledge Graphs (KG) and LLMs has shown promising results, but LLMs generally lack the ability to reason efficiently over graph-structured information. To tackle this problem, we propose a novel retrieval approach that integrates textual knowledge graphs into the LLM reasoning process via query decomposition. Our method decomposes complex questions into sub-questions, retrieves relevant textual subgraphs, and composes a question-specific knowledge graph to guide answer generation. For that, we use a weighted similarity function that focuses on both the complex question and the generated subquestions to extract a relevant subgraph, which allows efficient and precise retrieval for complex questions and improves the performance of LLMs on multi-hop QA tasks. This structured reasoning pipeline enhances factual grounding and interpretability while leveraging the generative strengths of LLMs. We evaluate our method on standard multi-hop QA benchmarks and show that it achieves comparable or superior performance to competitive existing methods, using smaller models and fewer LLM calls.
Analyzing Political Bias in LLMs via Target-Oriented Sentiment Classification
May 26, 2025Political biases encoded by LLMs might have detrimental effects on downstream applications. Existing bias analysis methods rely on small-size intermediate tasks (questionnaire answering or political content generation) and rely on the LLMs themselves for analysis, thus propagating bias. We propose a new approach leveraging the observation that LLM sentiment predictions vary with the target entity in the same sentence. We define an entropy-based inconsistency metric to encode this prediction variability. We insert 1319 demographically and politically diverse politician names in 450 political sentences and predict target-oriented sentiment using seven models in six widely spoken languages. We observe inconsistencies in all tested combinations and aggregate them in a statistically robust analysis at different granularity levels. We observe positive and negative bias toward left and far-right politicians and positive correlations between politicians with similar alignment. Bias intensity is higher for Western languages than for others. Larger models exhibit stronger and more consistent biases and reduce discrepancies between similar languages. We partially mitigate LLM unreliability in target-oriented sentiment classification (TSC) by replacing politician names with fictional but plausible counterparts.
The Lucie-7B LLM and the Lucie Training Dataset: Open resources for multilingual language generation
Mar 15, 2025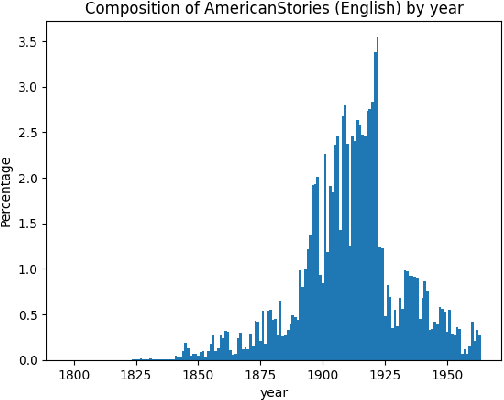

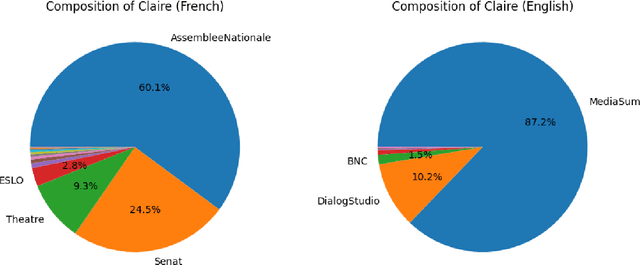
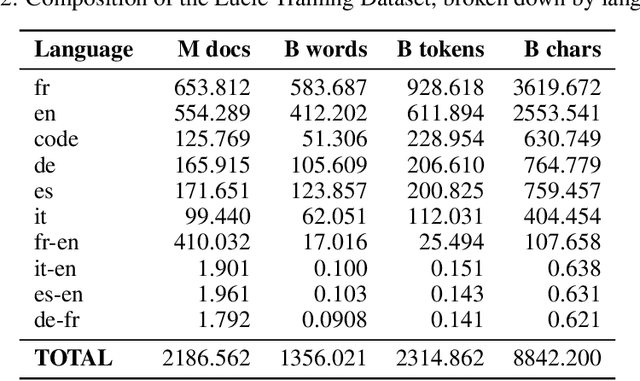
We present both the Lucie Training Dataset and the Lucie-7B foundation model. The Lucie Training Dataset is a multilingual collection of textual corpora centered around French and designed to offset anglo-centric biases found in many datasets for large language model pretraining. Its French data is pulled not only from traditional web sources, but also from French cultural heritage documents, filling an important gap in modern datasets. Beyond French, which makes up the largest share of the data, we added documents to support several other European languages, including English, Spanish, German, and Italian. Apart from its value as a resource for French language and culture, an important feature of this dataset is that it prioritizes data rights by minimizing copyrighted material. In addition, building on the philosophy of past open projects, it is redistributed in the form used for training and its processing is described on Hugging Face and GitHub. The Lucie-7B foundation model is trained on equal amounts of data in French and English -- roughly 33% each -- in an effort to better represent cultural aspects of French-speaking communities. We also describe two instruction fine-tuned models, Lucie-7B-Instruct-v1.1 and Lucie-7B-Instruct-human-data, which we release as demonstrations of Lucie-7B in use. These models achieve promising results compared to state-of-the-art models, demonstrating that an open approach prioritizing data rights can still deliver strong performance. We see these models as an initial step toward developing more performant, aligned models in the near future. Model weights for Lucie-7B and the Lucie instruct models, along with intermediate checkpoints for the former, are published on Hugging Face, while model training and data preparation code is available on GitHub. This makes Lucie-7B one of the first OSI compliant language models according to the new OSI definition.
Combining Objective and Subjective Perspectives for Political News Understanding
Aug 20, 2024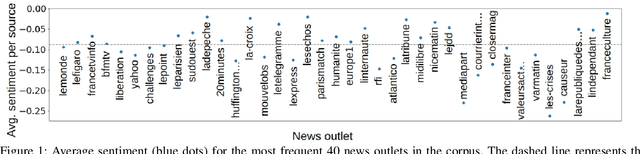
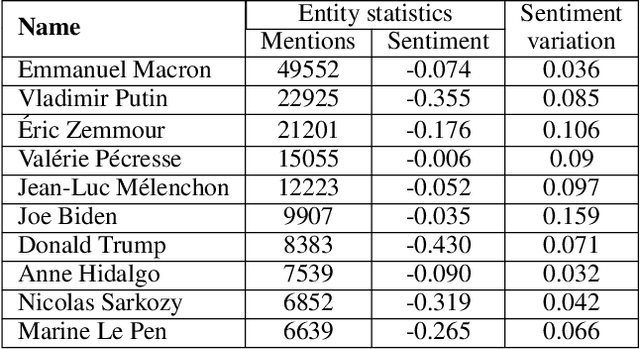
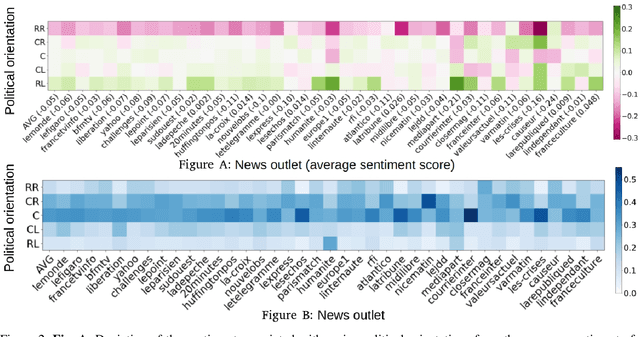

Researchers and practitioners interested in computational politics rely on automatic content analysis tools to make sense of the large amount of political texts available on the Web. Such tools should provide objective and subjective aspects at different granularity levels to make the analyses useful in practice. Existing methods produce interesting insights for objective aspects, but are limited for subjective ones, are often limited to national contexts, and have limited explainability. We introduce a text analysis framework which integrates both perspectives and provides a fine-grained processing of subjective aspects. Information retrieval techniques and knowledge bases complement powerful natural language processing components to allow a flexible aggregation of results at different granularity levels. Importantly, the proposed bottom-up approach facilitates the explainability of the obtained results. We illustrate its functioning with insights on news outlets, political orientations, topics, individual entities, and demographic segments. The approach is instantiated on a large corpus of French news, but is designed to work seamlessly for other languages and countries.