 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Objective and Subjective Perspectives for Political News Understanding
Aug 20, 2024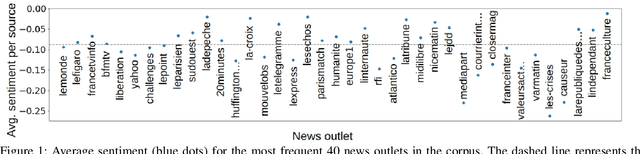
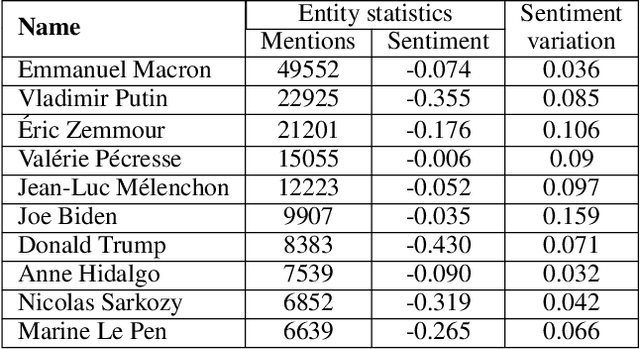
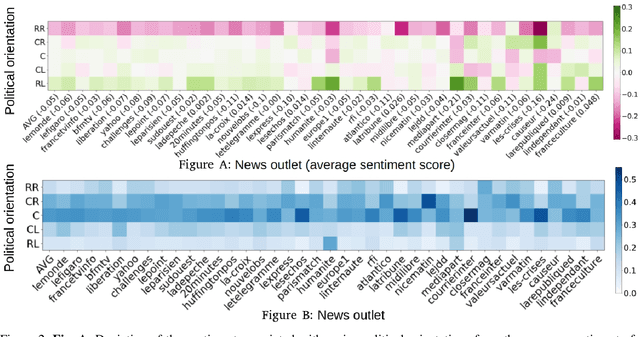

Researchers and practitioners interested in computational politics rely on automatic content analysis tools to make sense of the large amount of political texts available on the Web. Such tools should provide objective and subjective aspects at different granularity levels to make the analyses useful in practice. Existing methods produce interesting insights for objective aspects, but are limited for subjective ones, are often limited to national contexts, and have limited explainability. We introduce a text analysis framework which integrates both perspectives and provides a fine-grained processing of subjective aspects. Information retrieval techniques and knowledge bases complement powerful natural language processing components to allow a flexible aggregation of results at different granularity levels. Importantly, the proposed bottom-up approach facilitates the explainability of the obtained results. We illustrate its functioning with insights on news outlets, political orientations, topics, individual entities, and demographic segments. The approach is instantiated on a large corpus of French news, but is designed to work seamlessly for other languages and countries.
TIAM -- A Metric for Evaluating Alignment in Text-to-Image Generation
Jul 11, 2023The progress in the generation of synthetic images has made it crucial to assess their quality. While several metrics have been proposed to assess the rendering of images, it is crucial for Text-to-Image (T2I) models, which generate images based on a prompt, to consider additional aspects such as to which extent the generated image matches the important content of the prompt. Moreover, although the generated images usually result from a random starting point, the influence of this one is generally not considered. In this article, we propose a new metric based on prompt templates to study the alignment between the content specified in the prompt and the corresponding generated images. It allows us to better characterize the alignment in terms of the type of the specified objects, their number, and their color. We conducted a study on several recent T2I models about various aspects. An additional interesting result we obtained with our approach is that image quality can vary drastically depending on the latent noise used as a seed for the images. We also quantify the influence of the number of concepts in the prompt, their order as well as their (color) attributes. Finally, our method allows us to identify some latent seeds that produce better images than others, opening novel directions of research on this understudied topic.