 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2G2G: a Scalable Local-to-Global Network Embedding with Graph Autoencoders
Feb 02, 2024



For analysing real-world networks, graph representation learning is a popular tool. These methods, such as a graph autoencoder (GAE), typically rely on low-dimensional representations, also called embeddings, which are obtained through minimising a loss function; these embeddings are used with a decoder for downstream tasks such as node classification and edge prediction. While GAEs tend to be fairly accurate, they suffer from scalability issues. For improved speed, a Local2Global approach, which combines graph patch embeddings based on eigenvector synchronisation, was shown to be fast and achieve good accuracy. Here we propose L2G2G, a Local2Global method which improves GAE accuracy without sacrificing scalability. This improvement is achieved by dynamically synchronising the latent node representations, while training the GAEs. It also benefits from the decoder computing an only local patch loss. Hence, aligning the local embeddings in each epoch utilises more information from the graph than a single post-training alignment does, while maintaining scalability. We illustrate on synthetic benchmarks, as well as real-world examples, that L2G2G achieves higher accuracy than the standard Local2Global approach and scales efficiently on the larger data sets. We find that for large and dense networks, it even outperforms the slow, but assumed more accurate, GAEs.
SaGess: Sampling Graph Denoising Diffusion Model for Scalable Graph Generation
Jun 29, 2023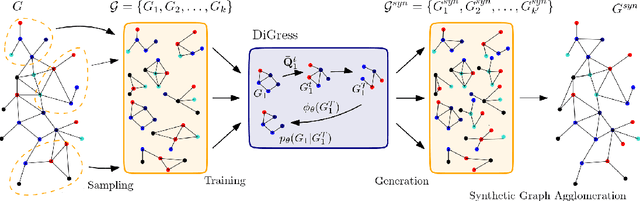
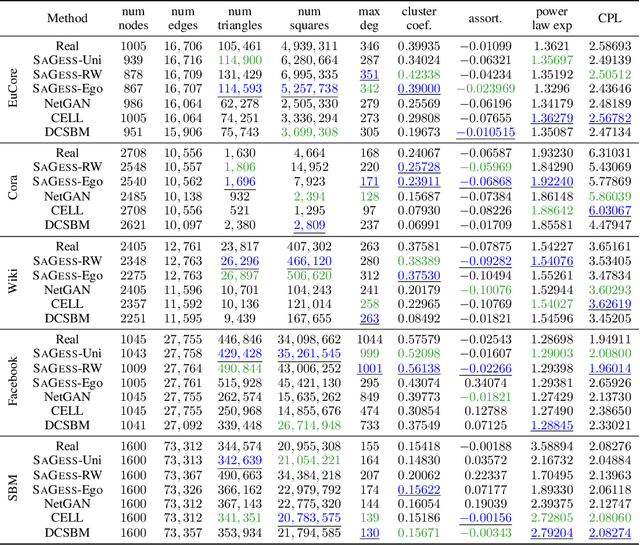
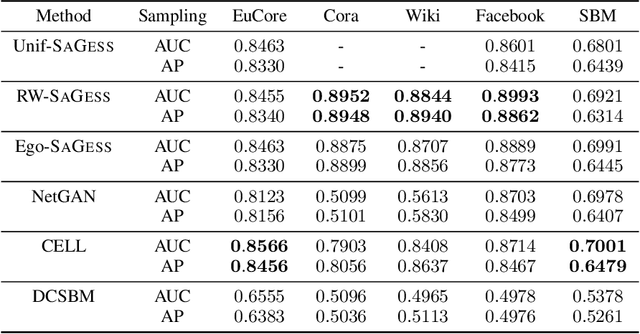
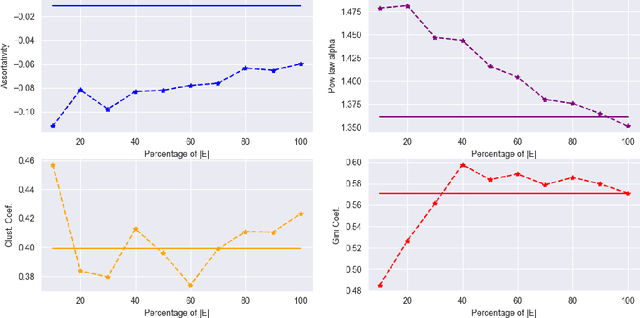
Over recent years, denoising diffusion generative models have come to be considered as state-of-the-art methods for synthetic data generation, especially in the case of generating images. These approaches have also proved successful in other applications such as tabular and graph data generation. However, due to computational complexity, to this date, the application of these techniques to graph data has been restricted to small graphs, such as those used in molecular modeling. In this paper, we propose SaGess, a discrete denoising diffusion approach, which is able to generate large real-world networks by augmenting a diffusion model (DiGress) with a generalized divide-and-conquer framework. The algorithm is capable of generating larger graphs by sampling a covering of subgraphs of the initial graph in order to train DiGress. SaGess then constructs a synthetic graph using the subgraphs that have been generated by DiGress. We evaluate the quality of the synthetic data sets against several competitor methods by comparing graph statistics between the original and synthetic samples, as well as evaluating the utility of the synthetic data set produced by using it to train a task-driven model, namely link prediction. In our experiments, SaGess, outperforms most of the one-shot state-of-the-art graph generating methods by a significant factor, both on the graph metrics and on the link prediction task.
Hcore-Init: Neural Network Initialization based on Graph Degeneracy
Apr 16, 2020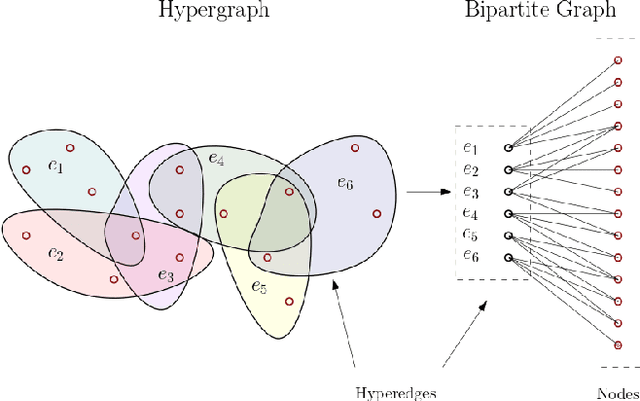

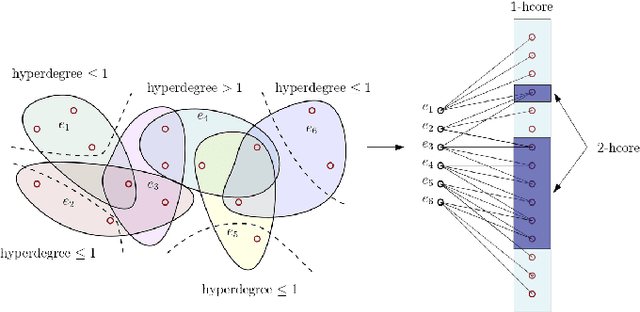
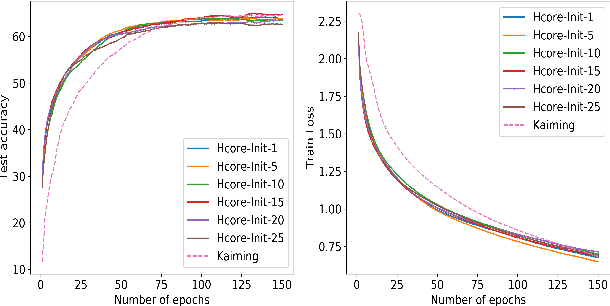
Neural networks are the pinnacle of Artificial Intelligence, as in recent years we witnessed many novel architectures, learning and optimization techniques for deep learning. Capitalizing on the fact that neural networks inherently constitute multipartite graphs among neuron layers, we aim to analyze directly their structure to extract meaningful information that can improve the learning process. To our knowledge graph mining techniques for enhancing learning in neural networks have not been thoroughly investigated. In this paper we propose an adapted version of the k-core structure for the complete weighted multipartite graph extracted from a deep learning architecture. As a multipartite graph is a combination of bipartite graphs, that are in turn the incidence graphs of hypergraphs, we design k-hypercore decomposition, the hypergraph analogue of k-core degeneracy. We applied k-hypercore to several neural network architectures, more specifically to convolutional neural networks and multilayer perceptrons for image recognition tasks after a very short pretraining. Then we used the information provided by the hypercore numbers of the neurons to re-initialize the weights of the neural network, thus biasing the gradient optimization scheme. Extensive experiments proved that k-hypercore outperforms the state-of-the-art initialization methods.
Gravity-Inspired Graph Autoencoders for Directed Link Prediction
May 24, 2019
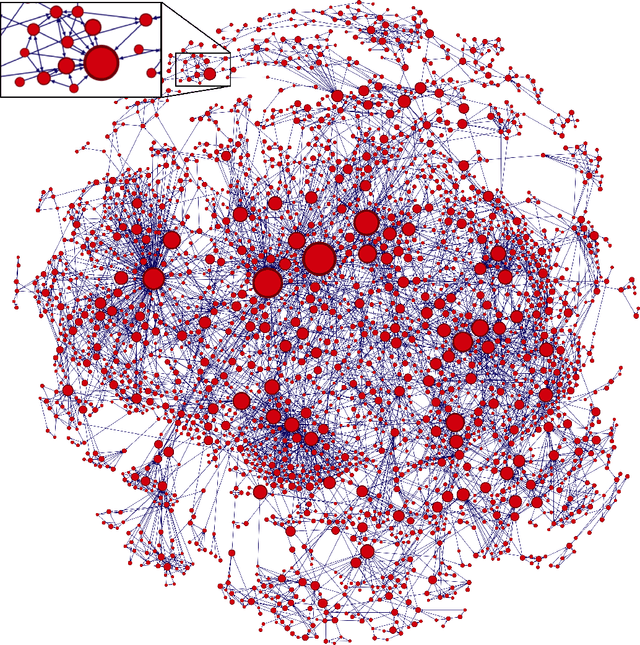
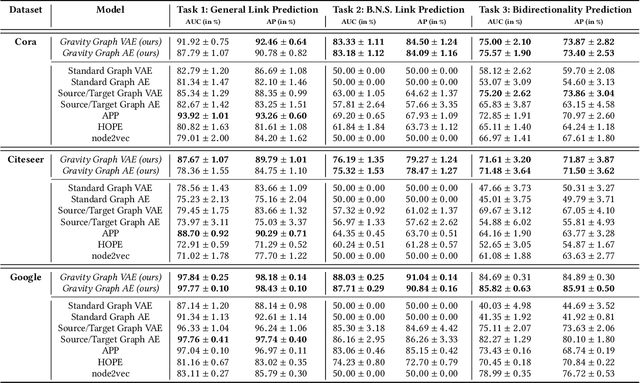

Graph autoencoders (AE) and variational autoencoders (VAE) recently emerged as powerful node embedding methods. In particular, graph AE and VAE were successfully leveraged to tackle the challenging link prediction problem, aiming at figuring out whether some pairs of nodes from a graph are connected by unobserved edges. However, these models focus on undirected graphs and therefore ignore the potential direction of the link, which is limiting for numerous real-life applications. In this paper, we extend the graph AE and VAE frameworks to address link prediction in directed graphs. We present a new gravity-inspired decoder scheme that can effectively reconstruct directed graphs from a node embedding. We empirically evaluate our method on three different directed link prediction tasks, for which standard graph AE and VAE perform poorly. We achieve competitive results on three real-world graphs, outperforming several popular baselines.
Rep the Set: Neural Networks for Learning Set Representations
Apr 03, 2019



In several domains, data objects can be decomposed into sets of simpler objects. It is then natural to represent each object as the set of its components or parts. Many conventional machine learning algorithms are unable to process this kind of representations, since sets may vary in cardinality and elements lack a meaningful ordering. In this paper, we present a new neural network architecture, called RepSet, that can handle examples that are represented as sets of vectors. The proposed model computes the correspondences between an input set and some hidden sets by solving a series of network flow problems. This representation is then fed to a standard neural network architecture to produce the output. The architecture allows end-to-end gradient-based learning. We demonstrate RepSet on classification tasks, including text categorization, and graph classification, and we show that the proposed neural network achieves performance better or comparable to state-of-the-art algorithms.
GraKeL: A Graph Kernel Library in Python
Jun 06, 2018The problem of accurately measuring the similarity between graphs is at the core of many applications in a variety of disciplines. Graph kernels have recently emerged as a promising approach to this problem. There are now many kernels, each focusing on different structural aspects of graphs. Here, we present GraKeL, a library that unifies several graph kernels into a common framework. The library is written in Python and is build on top of scikit-learn. It is simple to use and can be naturally combined with scikit-learn's modules to build a complete machine learning pipeline for tasks such as graph classification and clustering. The code is BSD licensed and is available at: https://github.com/ysig/GraKeL.