 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowVocoder: A small Footprint Neural Vocoder based Normalizing flow for Speech Synthesis
Sep 27, 2021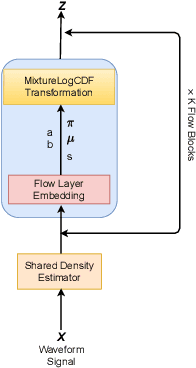

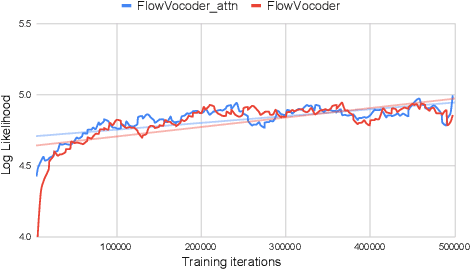
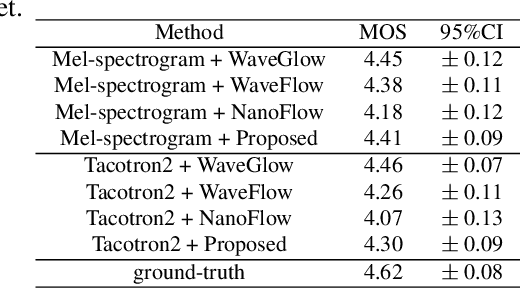
Recently, non-autoregressive neural vocoders have provided remarkable performance in generating high-fidelity speech and have been able to produce synthetic speech in real-time. However, non-autoregressive neural vocoders such as WaveGlow are far behind autoregressive neural vocoders like WaveFlow in terms of modeling audio signals due to their limitation in expressiveness. In addition, though NanoFlow is a state-of-the-art autoregressive neural vocoder that has immensely small parameters, its performance is marginally lower than WaveFlow. Therefore, in this paper, we propose a new type of autoregressive neural vocoder called FlowVocoder, which has a small memory footprint and is able to generate high-fidelity audio in real-time. Our proposed model improves the expressiveness of flow blocks by operating a mixture of Cumulative Distribution Function(CDF) for bipartite transformation. Hence, the proposed model is capable of modeling waveform signals as well as WaveFlow, while its memory footprint is much smaller thanWaveFlow. As shown in experiments, FlowVocoder achieves competitive results with baseline methods in terms of both subjective and objective evaluation, also, it is more suitable for real-time text-to-speech applications.
Many-to-Many Voice Conversion based Feature Disentanglement using Variational Autoencoder
Jul 11, 2021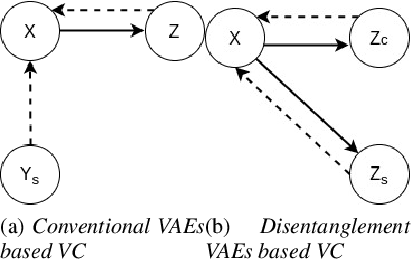
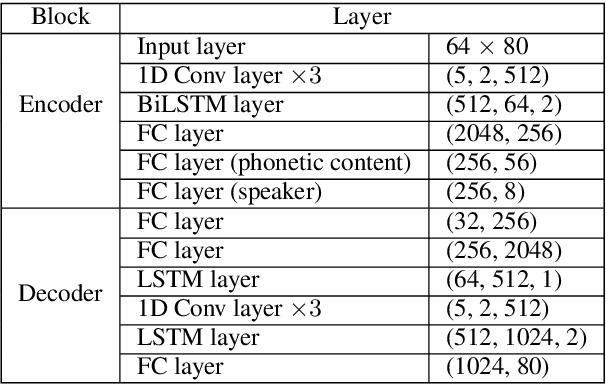
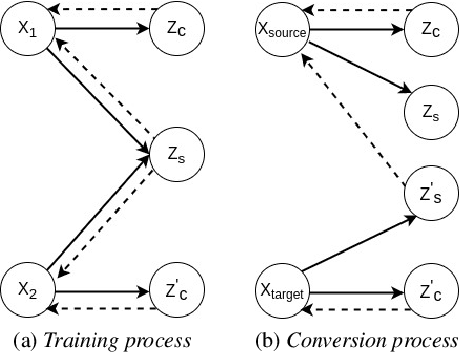
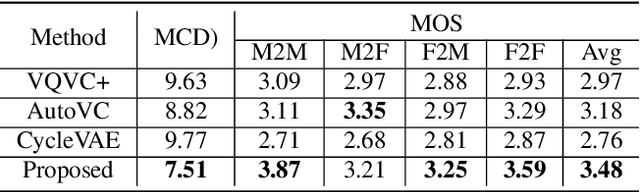
Voice conversion is a challenging task which transforms the voice characteristics of a source speaker to a target speaker without changing linguistic content. Recently, there have been many works on many-to-many Voice Conversion (VC) based on Variational Autoencoder (VAEs) achieving good results, however, these methods lack the ability to disentangle speaker identity and linguistic content to achieve good performance on unseen speaker scenarios. In this paper, we propose a new method based on feature disentanglement to tackle many to many voice conversion. The method has the capability to disentangle speaker identity and linguistic content from utterances, it can convert from many source speakers to many target speakers with a single autoencoder network. Moreover, it naturally deals with the unseen target speaker scenarios. We perform both objective and subjective evaluations to show the competitive performance of our proposed method compared with other state-of-the-art models in terms of naturalness and target speaker similarity.
Gravity-Inspired Graph Autoencoders for Directed Link Prediction
May 24, 2019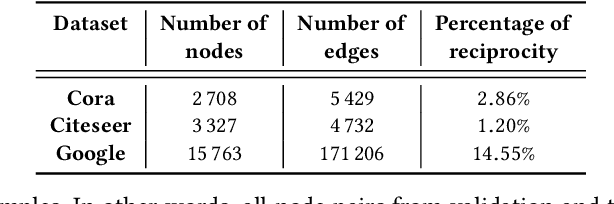
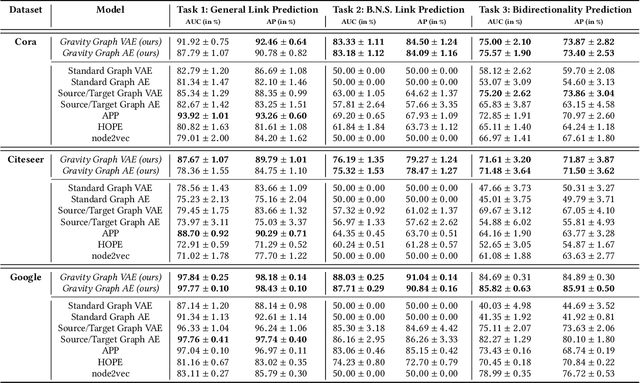

Graph autoencoders (AE) and variational autoencoders (VAE) recently emerged as powerful node embedding methods. In particular, graph AE and VAE were successfully leveraged to tackle the challenging link prediction problem, aiming at figuring out whether some pairs of nodes from a graph are connected by unobserved edges. However, these models focus on undirected graphs and therefore ignore the potential direction of the link, which is limiting for numerous real-life applications. In this paper, we extend the graph AE and VAE frameworks to address link prediction in directed graphs. We present a new gravity-inspired decoder scheme that can effectively reconstruct directed graphs from a node embedding. We empirically evaluate our method on three different directed link prediction tasks, for which standard graph AE and VAE perform poorly. We achieve competitive results on three real-world graphs, outperforming several popular baselines.
A Degeneracy Framework for Scalable Graph Autoencoders
Feb 23, 2019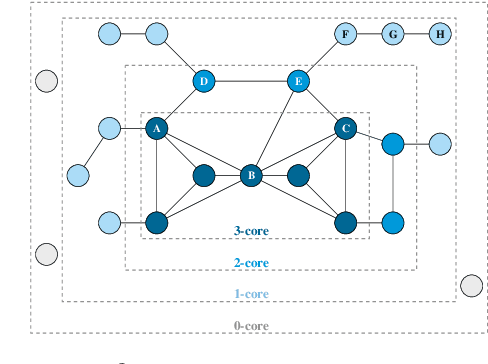
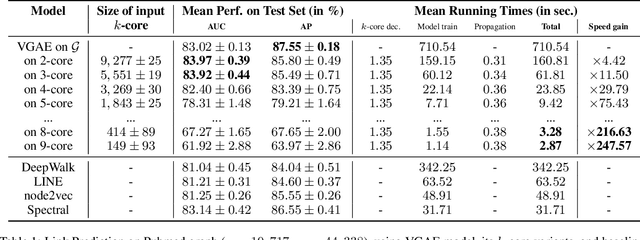
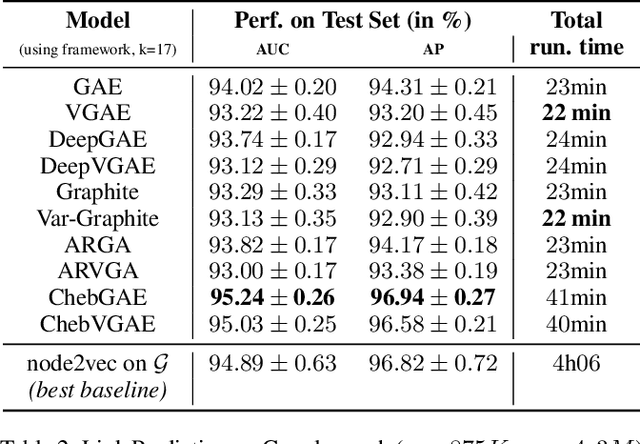
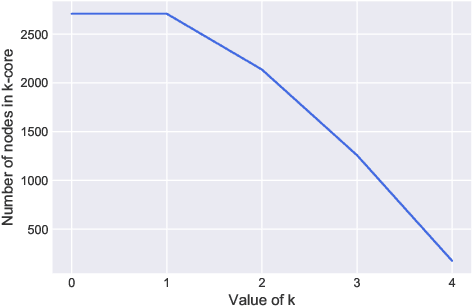
In this paper, we present a general framework to scale graph autoencoders (AE) and graph variational autoencoders (VAE). This framework leverages graph degeneracy concepts to train models only from a dense subset of nodes instead of using the entire graph. Together with a simple yet effective propagation mechanism, our approach significantly improves scalability and training speed while preserving performance. We evaluate and discuss our method on several variants of existing graph AE and VAE, providing the first application of these models to large graphs with up to millions of nodes and edges. We achieve empirically competitive results w.r.t. several popular scalable node embedding methods, which emphasizes the relevance of pursuing further research towards more scalable graph AE and VAE.