 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Musical Descriptors: Extracting Preference-Bearing Intent in Music Queries
Feb 11, 2026Although annotated music descriptor datasets for user queries are increasingly common, few consider the user's intent behind these descriptors, which is essential for effectively meeting their needs. We introduce MusicRecoIntent, a manually annotated corpus of 2,291 Reddit music requests, labeling musical descriptors across seven categories with positive, negative, or referential preference-bearing roles. We then investigate how reliably large language models (LLMs) can extract these music descriptors, finding that they do capture explicit descriptors but struggle with context-dependent ones. This work can further serve as a benchmark for fine-grained modeling of user intent and for gaining insights into improving LLM-based music understanding systems.
Uncertainty in Repeated Implicit Feedback as a Measure of Reliability
May 05, 2025Recommender systems rely heavily on user feedback to learn effective user and item representations. Despite their widespread adoption, limited attention has been given to the uncertainty inherent in the feedback used to train these systems. Both implicit and explicit feedback are prone to noise due to the variability in human interactions, with implicit feedback being particularly challenging. In collaborative filtering, the reliability of interaction signals is critical, as these signals determine user and item similarities. Thus, deriving accurate confidence measures from implicit feedback is essential for ensuring the reliability of these signals. A common assumption in academia and industry is that repeated interactions indicate stronger user interest, increasing confidence in preference estimates. However, in domains such as music streaming, repeated consumption can shift user preferences over time due to factors like satiation and exposure. While literature on repeated consumption acknowledges these dynamics, they are often overlooked when deriving confidence scores for implicit feedback. This paper addresses this gap by focusing on music streaming, where repeated interactions are frequent and quantifiable. We analyze how repetition patterns intersect with key factors influencing user interest and develop methods to quantify the associated uncertainty. These uncertainty measures are then integrated as consistency metrics in a recommendation task. Our empirical results show that incorporating uncertainty into user preference models yields more accurate and relevant recommendations. Key contributions include a comprehensive analysis of uncertainty in repeated consumption patterns, the release of a novel dataset, and a Bayesian model for implicit listening feedback.
AI-Generated Music Detection and its Challenges
Jan 17, 2025


In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. In particular, the ability to create credible minute-long synthetic music in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and artificial reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a AI-music detector, a tool that will help in the regulation of synthetic media. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that getting a good test score is not the end of the story. We expose and discuss several facets that could be problematic with such a deployed detector: robustness to audio manipulation, generalisation to unseen models. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of artificial content checkers.
Harnessing High-Level Song Descriptors towards Natural Language-Based Music Recommendation
Nov 08, 2024



Recommender systems relying on Language Models (LMs) have gained popularity in assisting users to navigate large catalogs. LMs often exploit item high-level descriptors, i.e. categories or consumption contexts, from training data or user preferences. This has been proven effective in domains like movies or products. However, in the music domain, understanding how effectively LMs utilize song descriptors for natural language-based music recommendation is relatively limited. In this paper, we assess LMs effectiveness in recommending songs based on user natural language descriptions and items with descriptors like genres, moods, and listening contexts. We formulate the recommendation task as a dense retrieval problem and assess LMs as they become increasingly familiar with data pertinent to the task and domain. Our findings reveal improved performance as LMs are fine-tuned for general language similarity, information retrieval, and mapping longer descriptions to shorter, high-level descriptors in music.
Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation
Aug 29, 2024Music streaming services often leverage sequential recommender systems to predict the best music to showcase to users based on past sequences of listening sessions. Nonetheless, most sequential recommendation methods ignore or insufficiently account for repetitive behaviors. This is a crucial limitation for music recommendation, as repeatedly listening to the same song over time is a common phenomenon that can even change the way users perceive this song. In this paper, we introduce PISA (Psychology-Informed Session embedding using ACT-R), a session-level sequential recommender system that overcomes this limitation. PISA employs a Transformer architecture learning embedding representations of listening sessions and users using attention mechanisms inspired by Anderson's ACT-R (Adaptive Control of Thought-Rational), a cognitive architecture modeling human information access and memory dynamics. This approach enables us to capture dynamic and repetitive patterns from user behaviors, allowing us to effectively predict the songs they will listen to in subsequent sessions, whether they are repeated or new ones. We demonstrate the empirical relevance of PISA using both publicly available listening data from Last.fm and proprietary data from Deezer, a global music streaming service, confirming the critical importance of repetition modeling for sequential listening session recommendation. Along with this paper, we publicly release our proprietary dataset to foster future research in this field, as well as the source code of PISA to facilitate its future use.
From Real to Cloned Singer Identification
Jul 11, 2024
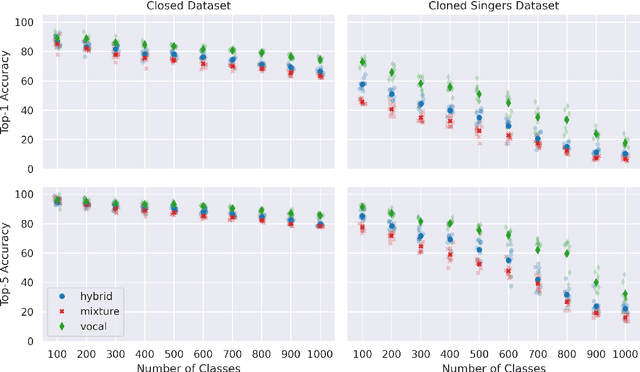

Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
STONE: Self-supervised Tonality Estimator
Jul 10, 2024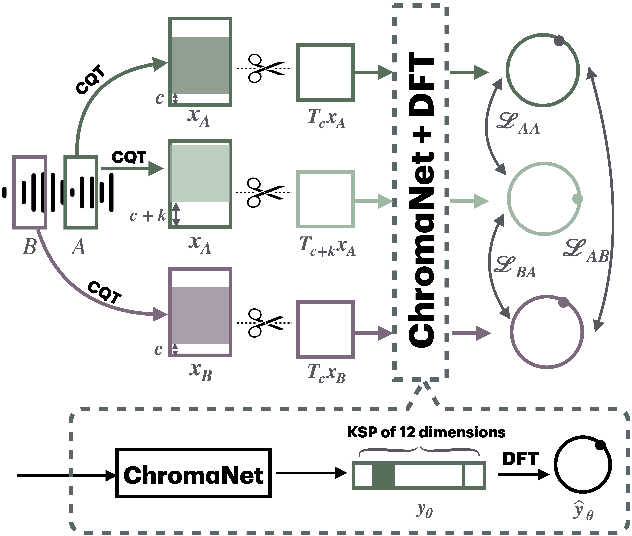
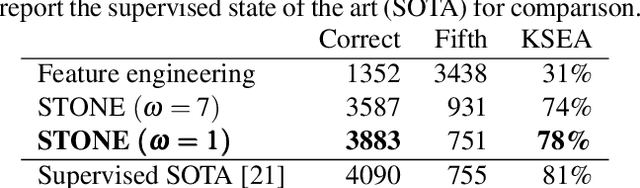

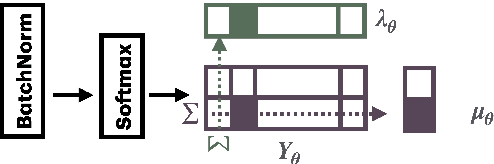
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a key signature profile (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
A Realistic Evaluation of LLMs for Quotation Attribution in Literary Texts: A Case Study of LLaMa3
Jun 17, 2024Large Language Models (LLMs) zero-shot and few-shot performance are subject to memorization and data contamination, complicating the assessment of their validity. In literary tasks, the performance of LLMs is often correlated to the degree of book memorization. In this work, we carry out a realistic evaluation of LLMs for quotation attribution in novels, taking the instruction fined-tuned version of Llama3 as an example. We design a task-specific memorization measure and use it to show that Llama3's ability to perform quotation attribution is positively correlated to the novel degree of memorization. However, Llama3 still performs impressively well on books it has not memorized nor seen. Data and code will be made publicly available.
Improving Quotation Attribution with Fictional Character Embeddings
Jun 17, 2024



Humans naturally attribute utterances of direct speech to their speaker in literary works. When attributing quotes, we process contextual information but also access mental representations of characters that we build and revise throughout the narrative. Recent methods to automatically attribute such utterances have explored simulating human logic with deterministic rules or learning new implicit rules with neural networks when processing contextual information. However, these systems inherently lack \textit{character} representations, which often leads to errors on more challenging examples of attribution: anaphoric and implicit quotes. In this work, we propose to augment a popular quotation attribution system, BookNLP, with character embeddings that encode global information of characters. To build these embeddings, we create DramaCV, a corpus of English drama plays from the 15th to 20th century focused on Character Verification (CV), a task similar to Authorship Verification (AV), that aims at analyzing fictional characters. We train a model similar to the recently proposed AV model, Universal Authorship Representation (UAR), on this dataset, showing that it outperforms concurrent methods of characters embeddings on the CV task and generalizes better to literary novels. Then, through an extensive evaluation on 22 novels, we show that combining BookNLP's contextual information with our proposed global character embeddings improves the identification of speakers for anaphoric and implicit quotes, reaching state-of-the-art performance. Code and data will be made publicly available.
STraDa: A Singer Traits Dataset
Jun 06, 2024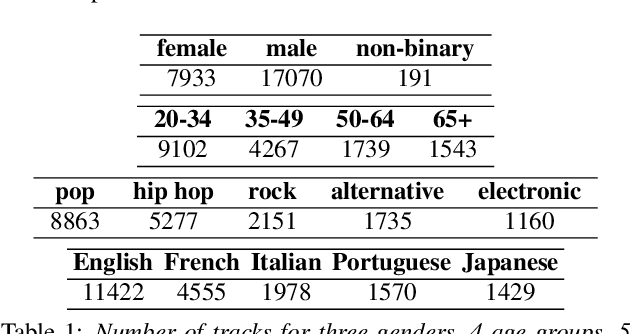



There is a limited amount of large-scale public datasets that contain downloadable music audio files and rich lead singer metadata. To provide such a dataset to benefit research in singing voices, we created Singer Traits Dataset (STraDa) with two subsets: automatic-strada and annotated-strada. The automatic-strada contains twenty-five thousand tracks across numerous genres and languages of more than five thousand unique lead singers, which includes cross-validated lead singer metadata as well as other track metadata. The annotated-strada consists of two hundred tracks that are balanced in terms of 2 genders, 5 languages, and 4 age groups. To show its use for model training and bias analysis thanks to its metadata's richness and downloadable audio files, we benchmarked singer sex classification (SSC) and conducted bias analysis.