 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFamiliarizing with Music: Discovery Patterns for Different Music Discovery Needs
May 06, 2025Humans have the tendency to discover and explore. This natural tendency is reflected in data from streaming platforms as the amount of previously unknown content accessed by users. Additionally, in domains such as that of music streaming there is evidence that recommending novel content improves users' experience with the platform. Therefore, understanding users' discovery patterns, such as the amount to which and the way users access previously unknown content, is a topic of relevance for both the scientific community and the streaming industry, particularly the music one. Previous works studied how music consumption differs for users of different traits and looked at diversity, novelty, and consistency over time of users' music preferences. However, very little is known about how users discover and explore previously unknown music, and how this behavior differs for users of varying discovery needs. In this paper we bridge this gap by analyzing data from a survey answered by users of the major music streaming platform Deezer in combination with their streaming data. We first address questions regarding whether users who declare a higher interest in unfamiliar music listen to more diverse music, have more stable music preferences over time, and explore more music within a same time window, compared to those who declare a lower interest. We then investigate which type of music tracks users choose to listen to when they explore unfamiliar music, identifying clear patterns of popularity and genre representativeness that vary for users of different discovery needs. Our findings open up possibilities to infer users' interest in unfamiliar music from streaming data as well as possibilities to develop recommender systems that guide users in exploring music in a more natural way.
AI-Generated Music Detection and its Challenges
Jan 17, 2025


In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. In particular, the ability to create credible minute-long synthetic music in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and artificial reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a AI-music detector, a tool that will help in the regulation of synthetic media. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that getting a good test score is not the end of the story. We expose and discuss several facets that could be problematic with such a deployed detector: robustness to audio manipulation, generalisation to unseen models. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of artificial content checkers.
Harnessing High-Level Song Descriptors towards Natural Language-Based Music Recommendation
Nov 08, 2024



Recommender systems relying on Language Models (LMs) have gained popularity in assisting users to navigate large catalogs. LMs often exploit item high-level descriptors, i.e. categories or consumption contexts, from training data or user preferences. This has been proven effective in domains like movies or products. However, in the music domain, understanding how effectively LMs utilize song descriptors for natural language-based music recommendation is relatively limited. In this paper, we assess LMs effectiveness in recommending songs based on user natural language descriptions and items with descriptors like genres, moods, and listening contexts. We formulate the recommendation task as a dense retrieval problem and assess LMs as they become increasingly familiar with data pertinent to the task and domain. Our findings reveal improved performance as LMs are fine-tuned for general language similarity, information retrieval, and mapping longer descriptions to shorter, high-level descriptors in music.
Detecting music deepfakes is easy but actually hard
May 07, 2024

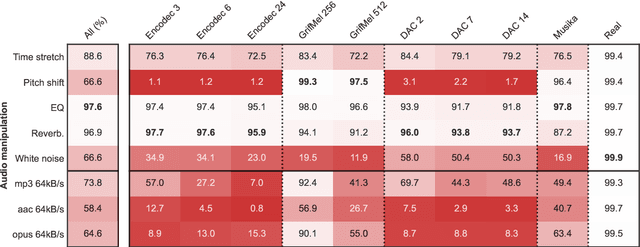

In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. The ability to create credible minute-long music deepfakes in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and fake reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a music deepfake detector, a tool that will help in the regulation of music forgery. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that a good test score is not the end of the story. We step back from the straightforward ML framework and expose many facets that could be problematic with such a deployed detector: calibration, robustness to audio manipulation, generalisation to unseen models, interpretability and possibility for recourse. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of fake content checkers.
Of Spiky SVDs and Music Recommendation
Jun 30, 2023The truncated singular value decomposition is a widely used methodology in music recommendation for direct similar-item retrieval or embedding musical items for downstream tasks. This paper investigates a curious effect that we show naturally occurring on many recommendation datasets: spiking formations in the embedding space. We first propose a metric to quantify this spiking organization's strength, then mathematically prove its origin tied to underlying communities of items of varying internal popularity. With this new-found theoretical understanding, we finally open the topic with an industrial use case of estimating how music embeddings' top-k similar items will change over time under the addition of data.
Learning Unsupervised Hierarchies of Audio Concepts
Jul 21, 2022

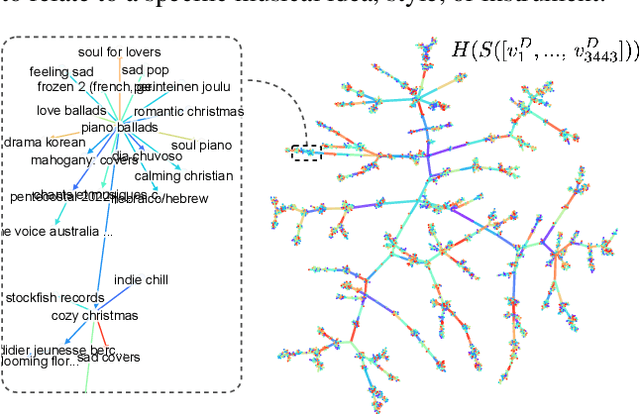

Music signals are difficult to interpret from their low-level features, perhaps even more than images: e.g. highlighting part of a spectrogram or an image is often insufficient to convey high-level ideas that are genuinely relevant to humans. In computer vision, concept learning was therein proposed to adjust explanations to the right abstraction level (e.g. detect clinical concepts from radiographs). These methods have yet to be used for MIR. In this paper, we adapt concept learning to the realm of music, with its particularities. For instance, music concepts are typically non-independent and of mixed nature (e.g. genre, instruments, mood), unlike previous work that assumed disentangled concepts. We propose a method to learn numerous music concepts from audio and then automatically hierarchise them to expose their mutual relationships. We conduct experiments on datasets of playlists from a music streaming service, serving as a few annotated examples for diverse concepts. Evaluations show that the mined hierarchies are aligned with both ground-truth hierarchies of concepts -- when available -- and with proxy sources of concept similarity in the general case.
Explainability in Music Recommender Systems
Jan 25, 2022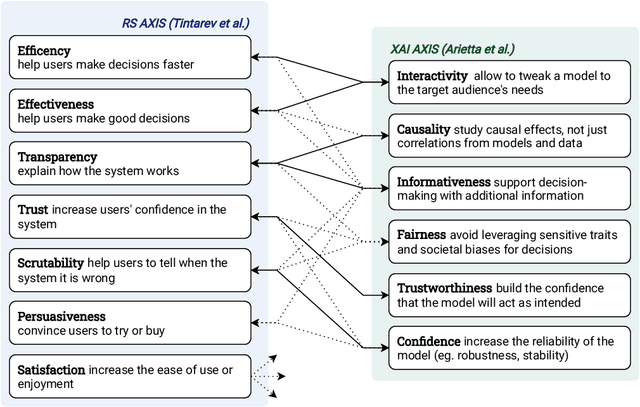
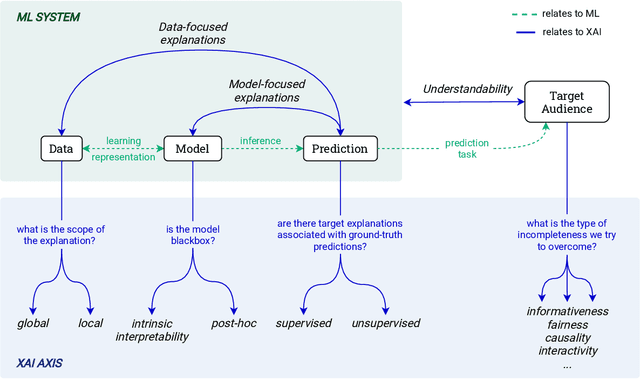
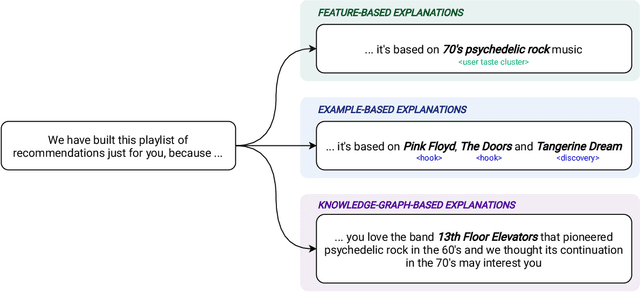
The most common way to listen to recorded music nowadays is via streaming platforms which provide access to tens of millions of tracks. To assist users in effectively browsing these large catalogs, the integration of Music Recommender Systems (MRSs) has become essential. Current real-world MRSs are often quite complex and optimized for recommendation accuracy. They combine several building blocks based on collaborative filtering and content-based recommendation. This complexity can hinder the ability to explain recommendations to end users, which is particularly important for recommendations perceived as unexpected or inappropriate. While pure recommendation performance often correlates with user satisfaction, explainability has a positive impact on other factors such as trust and forgiveness, which are ultimately essential to maintain user loyalty. In this article, we discuss how explainability can be addressed in the context of MRSs. We provide perspectives on how explainability could improve music recommendation algorithms and enhance user experience. First, we review common dimensions and goals of recommenders' explainability and in general of eXplainable Artificial Intelligence (XAI), and elaborate on the extent to which these apply -- or need to be adapted -- to the specific characteristics of music consumption and recommendation. Then, we show how explainability components can be integrated within a MRS and in what form explanations can be provided. Since the evaluation of explanation quality is decoupled from pure accuracy-based evaluation criteria, we also discuss requirements and strategies for evaluating explanations of music recommendations. Finally, we describe the current challenges for introducing explainability within a large-scale industrial music recommender system and provide research perspectives.
Towards Rigorous Interpretations: a Formalisation of Feature Attribution
Apr 26, 2021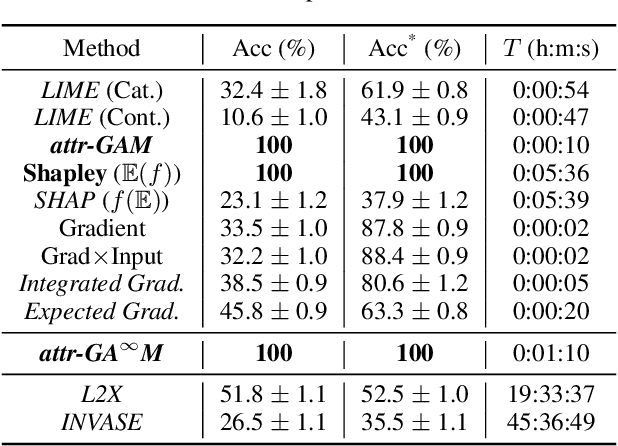


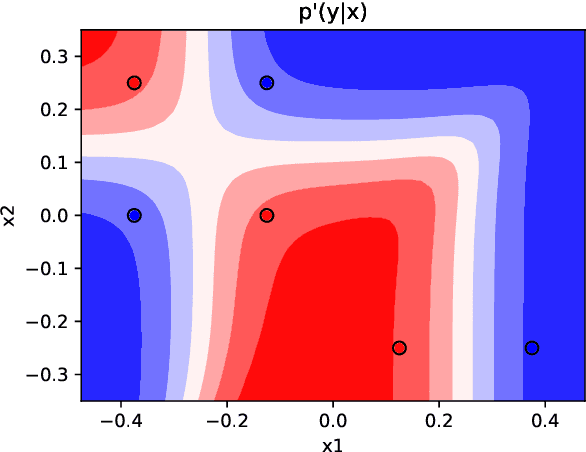
Feature attribution is often loosely presented as the process of selecting a subset of relevant features as a rationale of a prediction. This lack of clarity stems from the fact that we usually do not have access to any notion of ground-truth attribution and from a more general debate on what good interpretations are. In this paper we propose to formalise feature selection/attribution based on the concept of relaxed functional dependence. In particular, we extend our notions to the instance-wise setting and derive necessary properties for candidate selection solutions, while leaving room for task-dependence. By computing ground-truth attributions on synthetic datasets, we evaluate many state-of-the-art attribution methods and show that, even when optimised, some fail to verify the proposed properties and provide wrong solutions.
Making Neural Networks Interpretable with Attribution: Application to Implicit Signals Prediction
Aug 26, 2020



Explaining recommendations enables users to understand whether recommended items are relevant to their needs and has been shown to increase their trust in the system. More generally, if designing explainable machine learning models is key to check the sanity and robustness of a decision process and improve their efficiency, it however remains a challenge for complex architectures, especially deep neural networks that are often deemed "black-box". In this paper, we propose a novel formulation of interpretable deep neural networks for the attribution task. Differently to popular post-hoc methods, our approach is interpretable by design. Using masked weights, hidden features can be deeply attributed, split into several input-restricted sub-networks and trained as a boosted mixture of experts. Experimental results on synthetic data and real-world recommendation tasks demonstrate that our method enables to build models achieving close predictive performances to their non-interpretable counterparts, while providing informative attribution interpretations.
MesoNet: a Compact Facial Video Forgery Detection Network
Sep 04, 2018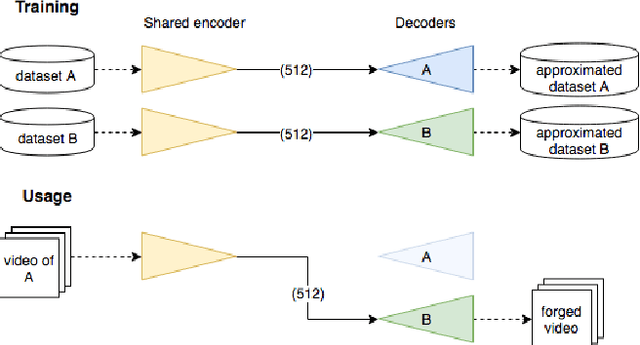



This paper presents a method to automatically and efficiently detect face tampering in videos, and particularly focuses on two recent techniques used to generate hyper-realistic forged videos: Deepfake and Face2Face. Traditional image forensics techniques are usually not well suited to videos due to the compression that strongly degrades the data. Thus, this paper follows a deep learning approach and presents two networks, both with a low number of layers to focus on the mesoscopic properties of images. We evaluate those fast networks on both an existing dataset and a dataset we have constituted from online videos. The tests demonstrate a very successful detection rate with more than 98% for Deepfake and 95% for Face2Face.