 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Beyond the past": Leveraging Audio and Human Memory for Sequential Music Recommendation
Jul 23, 2025On music streaming services, listening sessions are often composed of a balance of familiar and new tracks. Recently, sequential recommender systems have adopted cognitive-informed approaches, such as Adaptive Control of Thought-Rational (ACT-R), to successfully improve the prediction of the most relevant tracks for the next user session. However, one limitation of using a model inspired by human memory (or the past), is that it struggles to recommend new tracks that users have not previously listened to. To bridge this gap, here we propose a model that leverages audio information to predict in advance the ACT-R-like activation of new tracks and incorporates them into the recommendation scoring process. We demonstrate the empirical effectiveness of the proposed model using proprietary data, which we publicly release along with the model's source code to foster future research in this field.
Biases in LLM-Generated Musical Taste Profiles for Recommendation
Jul 22, 2025One particularly promising use case of Large Language Models (LLMs) for recommendation is the automatic generation of Natural Language (NL) user taste profiles from consumption data. These profiles offer interpretable and editable alternatives to opaque collaborative filtering representations, enabling greater transparency and user control. However, it remains unclear whether users consider these profiles to be an accurate representation of their taste, which is crucial for trust and usability. Moreover, because LLMs inherit societal and data-driven biases, profile quality may systematically vary across user and item characteristics. In this paper, we study this issue in the context of music streaming, where personalization is challenged by a large and culturally diverse catalog. We conduct a user study in which participants rate NL profiles generated from their own listening histories. We analyze whether identification with the profiles is biased by user attributes (e.g., mainstreamness, taste diversity) and item features (e.g., genre, country of origin). We also compare these patterns to those observed when using the profiles in a downstream recommendation task. Our findings highlight both the potential and limitations of scrutable, LLM-based profiling in personalized systems.
Modeling Musical Genre Trajectories through Pathlet Learning
May 06, 2025The increasing availability of user data on music streaming platforms opens up new possibilities for analyzing music consumption. However, understanding the evolution of user preferences remains a complex challenge, particularly as their musical tastes change over time. This paper uses the dictionary learning paradigm to model user trajectories across different musical genres. We define a new framework that captures recurring patterns in genre trajectories, called pathlets, enabling the creation of comprehensible trajectory embeddings. We show that pathlet learning reveals relevant listening patterns that can be analyzed both qualitatively and quantitatively. This work improves our understanding of users' interactions with music and opens up avenues of research into user behavior and fostering diversity in recommender systems. A dataset of 2000 user histories tagged by genre over 17 months, supplied by Deezer (a leading music streaming company), is also released with the code.
Uncertainty in Repeated Implicit Feedback as a Measure of Reliability
May 05, 2025Recommender systems rely heavily on user feedback to learn effective user and item representations. Despite their widespread adoption, limited attention has been given to the uncertainty inherent in the feedback used to train these systems. Both implicit and explicit feedback are prone to noise due to the variability in human interactions, with implicit feedback being particularly challenging. In collaborative filtering, the reliability of interaction signals is critical, as these signals determine user and item similarities. Thus, deriving accurate confidence measures from implicit feedback is essential for ensuring the reliability of these signals. A common assumption in academia and industry is that repeated interactions indicate stronger user interest, increasing confidence in preference estimates. However, in domains such as music streaming, repeated consumption can shift user preferences over time due to factors like satiation and exposure. While literature on repeated consumption acknowledges these dynamics, they are often overlooked when deriving confidence scores for implicit feedback. This paper addresses this gap by focusing on music streaming, where repeated interactions are frequent and quantifiable. We analyze how repetition patterns intersect with key factors influencing user interest and develop methods to quantify the associated uncertainty. These uncertainty measures are then integrated as consistency metrics in a recommendation task. Our empirical results show that incorporating uncertainty into user preference models yields more accurate and relevant recommendations. Key contributions include a comprehensive analysis of uncertainty in repeated consumption patterns, the release of a novel dataset, and a Bayesian model for implicit listening feedback.
Do Recommender Systems Promote Local Music? A Reproducibility Study Using Music Streaming Data
Aug 29, 2024This paper examines the influence of recommender systems on local music representation, discussing prior findings from an empirical study on the LFM-2b public dataset. This prior study argued that different recommender systems exhibit algorithmic biases shifting music consumption either towards or against local content. However, LFM-2b users do not reflect the diverse audience of music streaming services. To assess the robustness of this study's conclusions, we conduct a comparative analysis using proprietary listening data from a global music streaming service, which we publicly release alongside this paper. We observe significant differences in local music consumption patterns between our dataset and LFM-2b, suggesting that caution should be exercised when drawing conclusions on local music based solely on LFM-2b. Moreover, we show that the algorithmic biases exhibited in the original work vary in our dataset, and that several unexplored model parameters can significantly influence these biases and affect the study's conclusion on both datasets. Finally, we discuss the complexity of accurately labeling local music, emphasizing the risk of misleading conclusions due to unreliable, biased, or incomplete labels. To encourage further research and ensure reproducibility, we have publicly shared our dataset and code.
From Real to Cloned Singer Identification
Jul 11, 2024
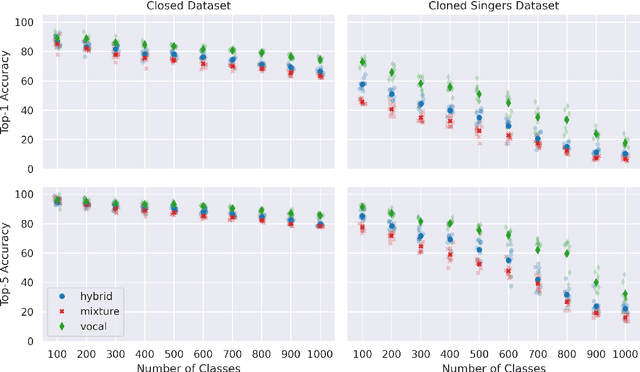

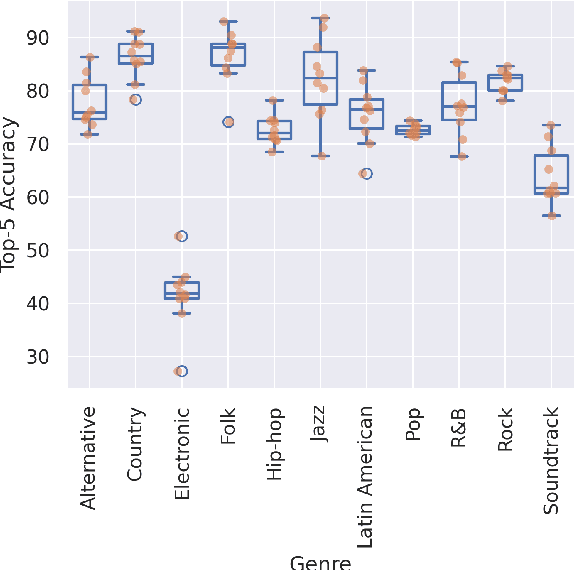
Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
Modeling Activity-Driven Music Listening with PACE
May 02, 2024While the topic of listening context is widely studied in the literature of music recommender systems, the integration of regular user behavior is often omitted. In this paper, we propose PACE (PAttern-based user Consumption Embedding), a framework for building user embeddings that takes advantage of periodic listening behaviors. PACE leverages users' multichannel time-series consumption patterns to build understandable user vectors. We believe the embeddings learned with PACE unveil much about the repetitive nature of user listening dynamics. By applying this framework on long-term user histories, we evaluate the embeddings through a predictive task of activities performed while listening to music. The validation task's interest is two-fold, while it shows the relevance of our approach, it also offers an insightful way of understanding users' musical consumption habits.
Explainability in Music Recommender Systems
Jan 25, 2022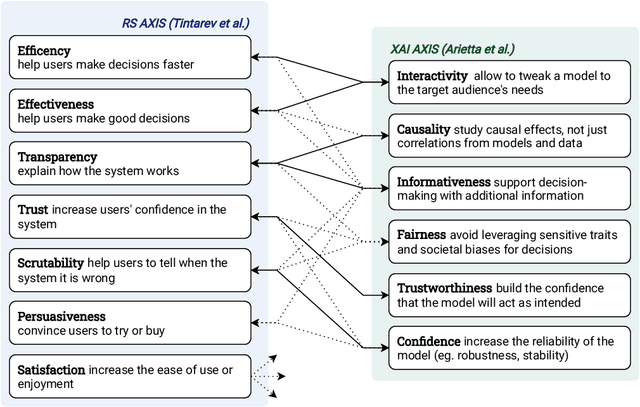
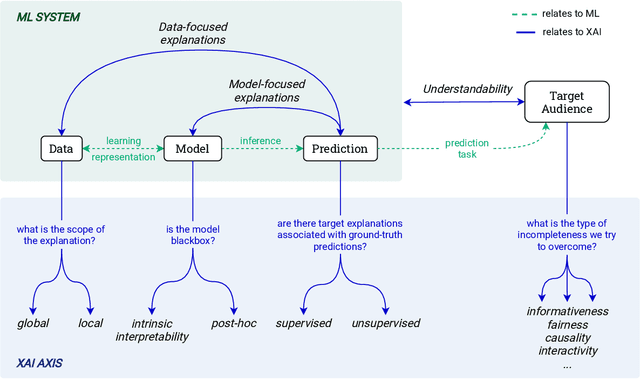
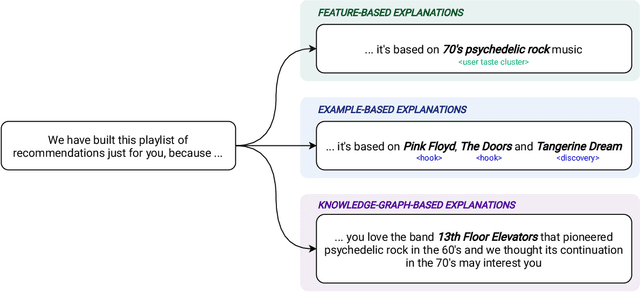
The most common way to listen to recorded music nowadays is via streaming platforms which provide access to tens of millions of tracks. To assist users in effectively browsing these large catalogs, the integration of Music Recommender Systems (MRSs) has become essential. Current real-world MRSs are often quite complex and optimized for recommendation accuracy. They combine several building blocks based on collaborative filtering and content-based recommendation. This complexity can hinder the ability to explain recommendations to end users, which is particularly important for recommendations perceived as unexpected or inappropriate. While pure recommendation performance often correlates with user satisfaction, explainability has a positive impact on other factors such as trust and forgiveness, which are ultimately essential to maintain user loyalty. In this article, we discuss how explainability can be addressed in the context of MRSs. We provide perspectives on how explainability could improve music recommendation algorithms and enhance user experience. First, we review common dimensions and goals of recommenders' explainability and in general of eXplainable Artificial Intelligence (XAI), and elaborate on the extent to which these apply -- or need to be adapted -- to the specific characteristics of music consumption and recommendation. Then, we show how explainability components can be integrated within a MRS and in what form explanations can be provided. Since the evaluation of explanation quality is decoupled from pure accuracy-based evaluation criteria, we also discuss requirements and strategies for evaluating explanations of music recommendations. Finally, we describe the current challenges for introducing explainability within a large-scale industrial music recommender system and provide research perspectives.
Follow the guides: disentangling human and algorithmic curation in online music consumption
Sep 08, 2021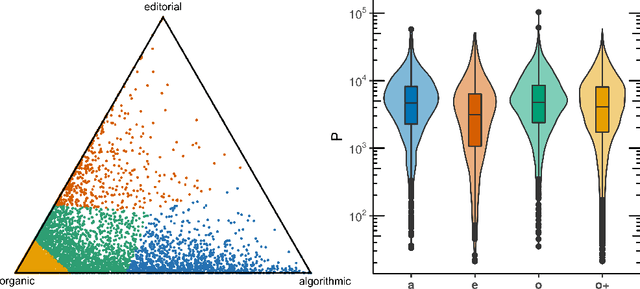

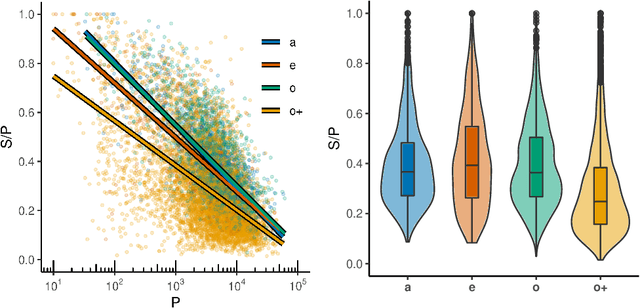
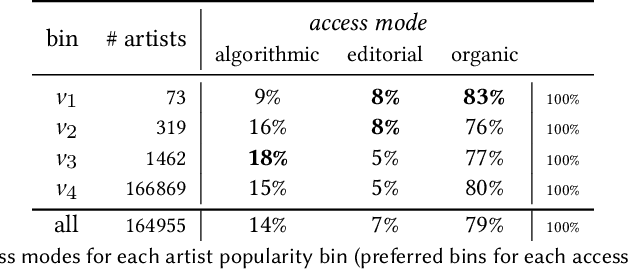
The role of recommendation systems in the diversity of content consumption on platforms is a much-debated issue. The quantitative state of the art often overlooks the existence of individual attitudes toward guidance, and eventually of different categories of users in this regard. Focusing on the case of music streaming, we analyze the complete listening history of about 9k users over one year and demonstrate that there is no blanket answer to the intertwinement of recommendation use and consumption diversity: it depends on users. First we compute for each user the relative importance of different access modes within their listening history, introducing a trichotomy distinguishing so-called `organic' use from algorithmic and editorial guidance. We thereby identify four categories of users. We then focus on two scales related to content diversity, both in terms of dispersion -- how much users consume the same content repeatedly -- and popularity -- how popular is the content they consume. We show that the two types of recommendation offered by music platforms -- algorithmic and editorial -- may drive the consumption of more or less diverse content in opposite directions, depending also strongly on the type of users. Finally, we compare users' streaming histories with the music programming of a selection of popular French radio stations during the same period. While radio programs are usually more tilted toward repetition than users' listening histories, they often program more songs from less popular artists. On the whole, our results highlight the nontrivial effects of platform-mediated recommendation on consumption, and lead us to speak of `filter niches' rather than `filter bubbles'. They hint at further ramifications for the study and design of recommendation systems.
Hierarchical Latent Relation Modeling for Collaborative Metric Learning
Jul 26, 2021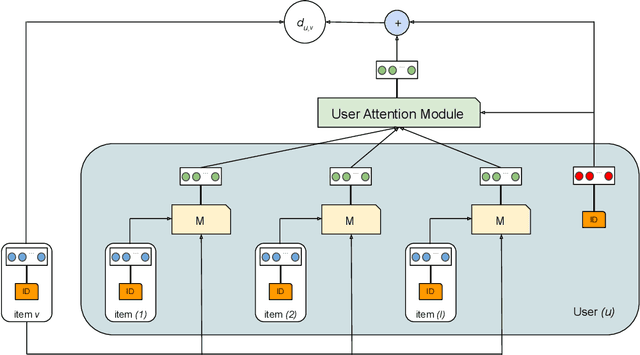
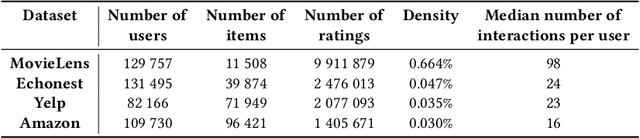
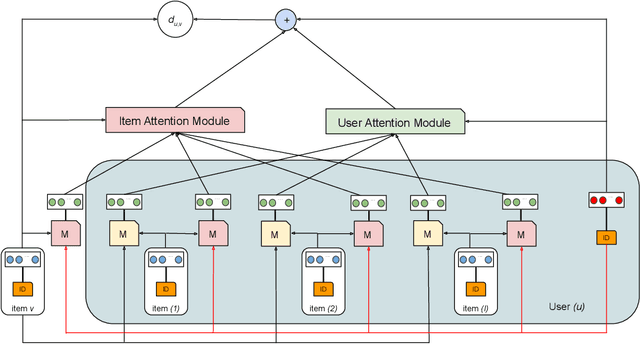
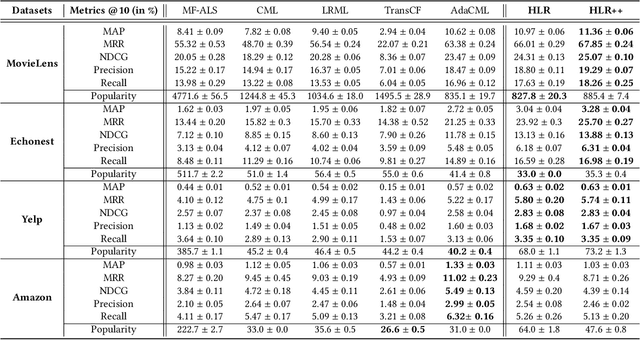
Collaborative Metric Learning (CML) recently emerged as a powerful paradigm for recommendation based on implicit feedback collaborative filtering. However, standard CML methods learn fixed user and item representations, which fails to capture the complex interests of users. Existing extensions of CML also either ignore the heterogeneity of user-item relations, i.e. that a user can simultaneously like very different items, or the latent item-item relations, i.e. that a user's preference for an item depends, not only on its intrinsic characteristics, but also on items they previously interacted with. In this paper, we present a hierarchical CML model that jointly captures latent user-item and item-item relations from implicit data. Our approach is inspired by translation mechanisms from knowledge graph embedding and leverages memory-based attention networks. We empirically show the relevance of this joint relational modeling, by outperforming existing CML models on recommendation tasks on several real-world datasets. Our experiments also emphasize the limits of current CML relational models on very sparse datasets.