 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty in Repeated Implicit Feedback as a Measure of Reliability
May 05, 2025Recommender systems rely heavily on user feedback to learn effective user and item representations. Despite their widespread adoption, limited attention has been given to the uncertainty inherent in the feedback used to train these systems. Both implicit and explicit feedback are prone to noise due to the variability in human interactions, with implicit feedback being particularly challenging. In collaborative filtering, the reliability of interaction signals is critical, as these signals determine user and item similarities. Thus, deriving accurate confidence measures from implicit feedback is essential for ensuring the reliability of these signals. A common assumption in academia and industry is that repeated interactions indicate stronger user interest, increasing confidence in preference estimates. However, in domains such as music streaming, repeated consumption can shift user preferences over time due to factors like satiation and exposure. While literature on repeated consumption acknowledges these dynamics, they are often overlooked when deriving confidence scores for implicit feedback. This paper addresses this gap by focusing on music streaming, where repeated interactions are frequent and quantifiable. We analyze how repetition patterns intersect with key factors influencing user interest and develop methods to quantify the associated uncertainty. These uncertainty measures are then integrated as consistency metrics in a recommendation task. Our empirical results show that incorporating uncertainty into user preference models yields more accurate and relevant recommendations. Key contributions include a comprehensive analysis of uncertainty in repeated consumption patterns, the release of a novel dataset, and a Bayesian model for implicit listening feedback.
Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation
Aug 29, 2024Music streaming services often leverage sequential recommender systems to predict the best music to showcase to users based on past sequences of listening sessions. Nonetheless, most sequential recommendation methods ignore or insufficiently account for repetitive behaviors. This is a crucial limitation for music recommendation, as repeatedly listening to the same song over time is a common phenomenon that can even change the way users perceive this song. In this paper, we introduce PISA (Psychology-Informed Session embedding using ACT-R), a session-level sequential recommender system that overcomes this limitation. PISA employs a Transformer architecture learning embedding representations of listening sessions and users using attention mechanisms inspired by Anderson's ACT-R (Adaptive Control of Thought-Rational), a cognitive architecture modeling human information access and memory dynamics. This approach enables us to capture dynamic and repetitive patterns from user behaviors, allowing us to effectively predict the songs they will listen to in subsequent sessions, whether they are repeated or new ones. We demonstrate the empirical relevance of PISA using both publicly available listening data from Last.fm and proprietary data from Deezer, a global music streaming service, confirming the critical importance of repetition modeling for sequential listening session recommendation. Along with this paper, we publicly release our proprietary dataset to foster future research in this field, as well as the source code of PISA to facilitate its future use.
STraDa: A Singer Traits Dataset
Jun 06, 2024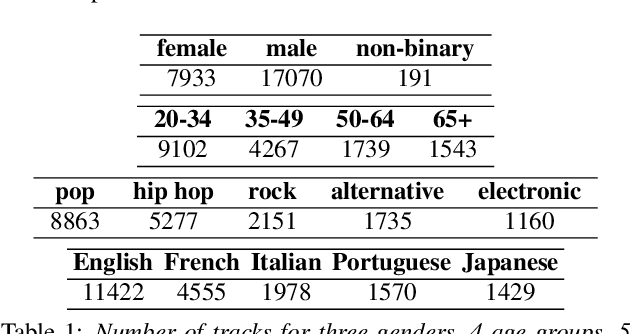



There is a limited amount of large-scale public datasets that contain downloadable music audio files and rich lead singer metadata. To provide such a dataset to benefit research in singing voices, we created Singer Traits Dataset (STraDa) with two subsets: automatic-strada and annotated-strada. The automatic-strada contains twenty-five thousand tracks across numerous genres and languages of more than five thousand unique lead singers, which includes cross-validated lead singer metadata as well as other track metadata. The annotated-strada consists of two hundred tracks that are balanced in terms of 2 genders, 5 languages, and 4 age groups. To show its use for model training and bias analysis thanks to its metadata's richness and downloadable audio files, we benchmarked singer sex classification (SSC) and conducted bias analysis.
Ex2Vec: Characterizing Users and Items from the Mere Exposure Effect
Nov 17, 2023The traditional recommendation framework seeks to connect user and content, by finding the best match possible based on users past interaction. However, a good content recommendation is not necessarily similar to what the user has chosen in the past. As humans, users naturally evolve, learn, forget, get bored, they change their perspective of the world and in consequence, of the recommendable content. One well known mechanism that affects user interest is the Mere Exposure Effect: when repeatedly exposed to stimuli, users' interest tends to rise with the initial exposures, reaching a peak, and gradually decreasing thereafter, resulting in an inverted-U shape. Since previous research has shown that the magnitude of the effect depends on a number of interesting factors such as stimulus complexity and familiarity, leveraging this effect is a way to not only improve repeated recommendation but to gain a more in-depth understanding of both users and stimuli. In this work we present (Mere) Exposure2Vec (Ex2Vec) our model that leverages the Mere Exposure Effect in repeat consumption to derive user and item characterization and track user interest evolution. We validate our model through predicting future music consumption based on repetition and discuss its implications for recommendation scenarios where repetition is common.
Automatic Annotation of Direct Speech in Written French Narratives
Jun 28, 2023



The automatic annotation of direct speech (AADS) in written text has been often used in computational narrative understanding. Methods based on either rules or deep neural networks have been explored, in particular for English or German languages. Yet, for French, our target language, not many works exist. Our goal is to create a unified framework to design and evaluate AADS models in French. For this, we consolidated the largest-to-date French narrative dataset annotated with DS per word; we adapted various baselines for sequence labelling or from AADS in other languages; and we designed and conducted an extensive evaluation focused on generalisation. Results show that the task still requires substantial efforts and emphasise characteristics of each baseline. Although this framework could be improved, it is a step further to encourage more research on the topic.
Attention Mixtures for Time-Aware Sequential Recommendation
Apr 17, 2023Transformers emerged as powerful methods for sequential recommendation. However, existing architectures often overlook the complex dependencies between user preferences and the temporal context. In this short paper, we introduce MOJITO, an improved Transformer sequential recommender system that addresses this limitation. MOJITO leverages Gaussian mixtures of attention-based temporal context and item embedding representations for sequential modeling. Such an approach permits to accurately predict which items should be recommended next to users depending on past actions and the temporal context. We demonstrate the relevance of our approach, by empirically outperforming existing Transformers for sequential recommendation on several real-world datasets.
Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization
Oct 28, 2022Repetition in music consumption is a common phenomenon. It is notably more frequent when compared to the consumption of other media, such as books and movies. In this paper, we show that one particularly interesting repetitive behavior arises when users are consuming new items. Users' interest tends to rise with the first repetitions and attains a peak after which interest will decrease with subsequent exposures, resulting in an inverted-U shape. This behavior, which has been extensively studied in psychology, is called the mere exposure effect. In this paper, we show how a number of factors, both content and user-based, well documented in the literature on the mere exposure effect, modulate the magnitude of the effect. Due to the vast availability of data of users discovering new songs everyday in music streaming platforms, these findings enable new ways to characterize both the music, users and their relationships. Ultimately, it opens up the possibility of developing new recommender systems paradigms based on these characterizations.
Personalized breath based biometric authentication with wearable multimodality
Oct 29, 2021
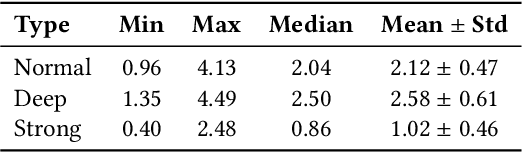

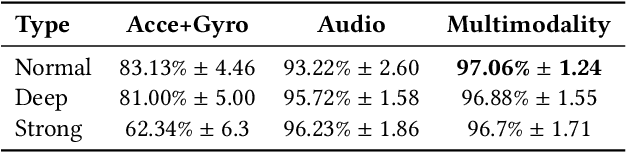
Breath with nose sound features has been shown as a potential biometric in personal identification and verification. In this paper, we show that information that comes from other modalities captured by motion sensors on the chest in addition to audio features could further improve the performance. Our work is composed of three main contributions: hardware creation, dataset publication, and proposed multimodal models. To be more specific, we design new hardware which consists of an acoustic sensor to collect audio features from the nose, as well as an accelerometer and gyroscope to collect movement on the chest as a result of an individual's breathing. Using this hardware, we publish a collected dataset from a number of sessions from different volunteers, each session includes three common gestures: normal, deep, and strong breathing. Finally, we experiment with two multimodal models based on Convolutional Long Short Term Memory (CNN-LSTM) and Temporal Convolutional Networks (TCN) architectures. The results demonstrate the suitability of our new hardware for both verification and identification tasks.
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Aug 02, 2021
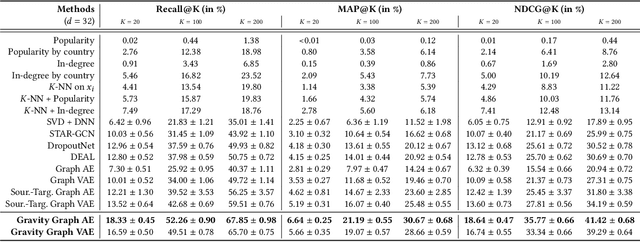
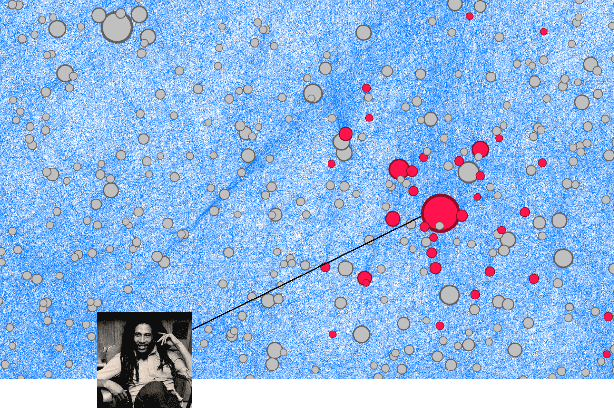
On an artist's profile page, music streaming services frequently recommend a ranked list of "similar artists" that fans also liked. However, implementing such a feature is challenging for new artists, for which usage data on the service (e.g. streams or likes) is not yet available. In this paper, we model this cold start similar artists ranking problem as a link prediction task in a directed and attributed graph, connecting artists to their top-k most similar neighbors and incorporating side musical information. Then, we leverage a graph autoencoder architecture to learn node embedding representations from this graph, and to automatically rank the top-k most similar neighbors of new artists using a gravity-inspired mechanism. We empirically show the flexibility and the effectiveness of our framework, by addressing a real-world cold start similar artists ranking problem on a global music streaming service. Along with this paper, we also publicly release our source code as well as the industrial graph data from our experiments.
Hierarchical Latent Relation Modeling for Collaborative Metric Learning
Jul 26, 2021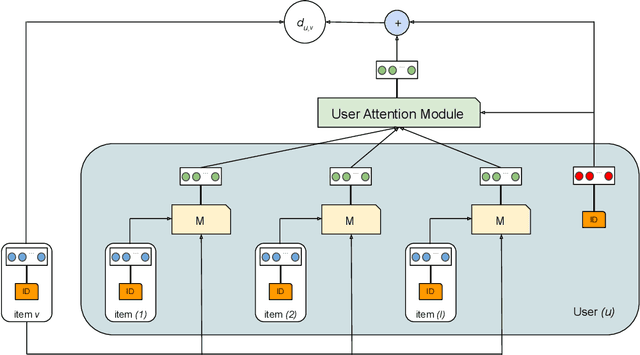
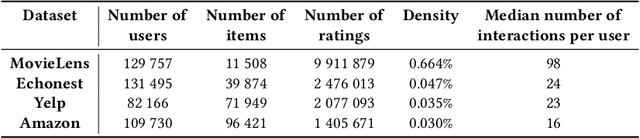
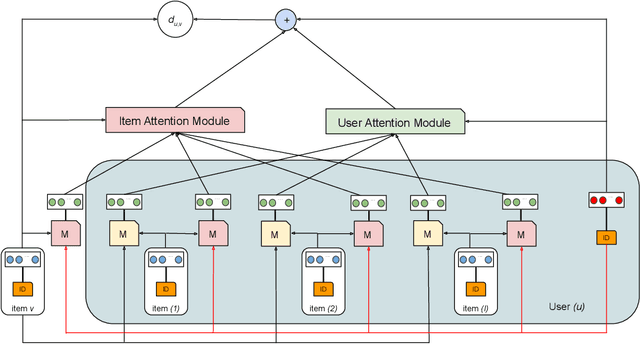
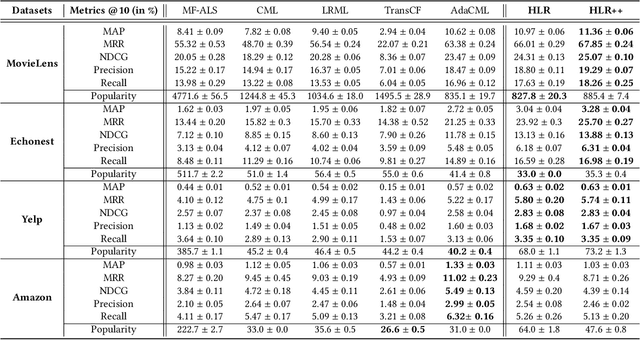
Collaborative Metric Learning (CML) recently emerged as a powerful paradigm for recommendation based on implicit feedback collaborative filtering. However, standard CML methods learn fixed user and item representations, which fails to capture the complex interests of users. Existing extensions of CML also either ignore the heterogeneity of user-item relations, i.e. that a user can simultaneously like very different items, or the latent item-item relations, i.e. that a user's preference for an item depends, not only on its intrinsic characteristics, but also on items they previously interacted with. In this paper, we present a hierarchical CML model that jointly captures latent user-item and item-item relations from implicit data. Our approach is inspired by translation mechanisms from knowledge graph embedding and leverages memory-based attention networks. We empirically show the relevance of this joint relational modeling, by outperforming existing CML models on recommendation tasks on several real-world datasets. Our experiments also emphasize the limits of current CML relational models on very sparse datasets.