 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTONE: Self-supervised Tonality Estimator
Jul 10, 2024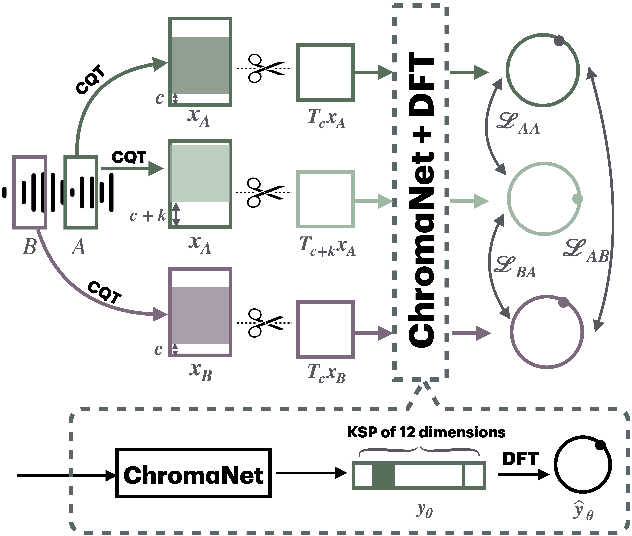
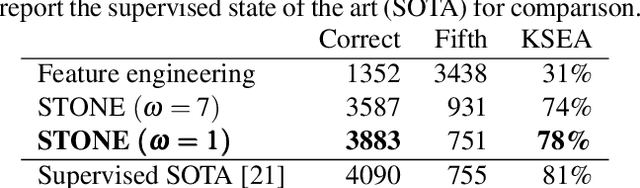

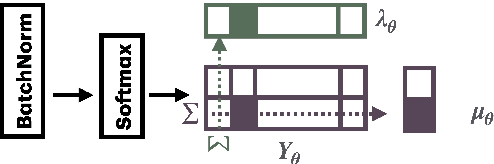
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a key signature profile (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
STraDa: A Singer Traits Dataset
Jun 06, 2024There is a limited amount of large-scale public datasets that contain downloadable music audio files and rich lead singer metadata. To provide such a dataset to benefit research in singing voices, we created Singer Traits Dataset (STraDa) with two subsets: automatic-strada and annotated-strada. The automatic-strada contains twenty-five thousand tracks across numerous genres and languages of more than five thousand unique lead singers, which includes cross-validated lead singer metadata as well as other track metadata. The annotated-strada consists of two hundred tracks that are balanced in terms of 2 genders, 5 languages, and 4 age groups. To show its use for model training and bias analysis thanks to its metadata's richness and downloadable audio files, we benchmarked singer sex classification (SSC) and conducted bias analysis.