 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphLit: Learning Text-Enriched Dynamic Character Network Representations for Literary Study
May 28, 2026Methods to represent literary texts as graphs or sequences of graphs mainly focus on representing character interactions, and often overlook another crucial aspect: the textual context in which characters interact. We introduce Dynamic Heterogeneous Character Networks (DHCNs), which organize long novels into temporally localized heterogeneous graphs that align characters with their textual contexts. We extract around 20,000 DHCNs from Project Gutenberg, and propose GraphLit, a self-supervised learning framework that learns rich literary representations through a masked graph autoencoder objective. Across a wide-range of 12 character-related tasks, GraphLit improves over text-only and graph-only baselines, particularly on tasks requiring contextual understanding. Finally, we demonstrate the applicability of DHCNs and GraphLit for literary analysis by studying the link between narrative non-linearity and dynamic social features.
S-VoCAL: A Dataset and Evaluation Framework for Inferring Speaking Voice Character Attributes in Literature
Mar 01, 2026With recent advances in Text-to-Speech (TTS) systems, synthetic audiobook narration has seen increased interest, reaching unprecedented levels of naturalness. However, larger gaps remain in synthetic narration systems' ability to impersonate fictional characters, and convey complex emotions or prosody. A promising direction to enhance character identification is the assignment of plausible voices to each fictional characters in a book. This step typically requires complex inference of attributes in book-length contexts, such as a character's age, gender, origin or physical health, which in turns requires dedicated benchmark datasets to evaluate extraction systems' performances. We present S-VoCAL (Speaking Voice Character Attributes in Literature), the first dataset and evaluation framework dedicated to evaluate the inference of voice-related fictional character attributes. S-VoCAL entails 8 attributes grounded in sociophonetic studies, and 952 character-book pairs derived from Project Gutenberg. Its evaluation framework addresses the particularities of each attribute, and includes a novel similarity metric based on recent Large Language Models embeddings. We demonstrate the applicability of S-VoCAL by applying a simple Retrieval-Augmented Generation (RAG) pipeline to the task of inferring character attributes. Our results suggest that the RAG pipeline reliably infers attributes such as Age or Gender, but struggles on others such as Origin or Physical Health. The dataset and evaluation code are available at https://github.com/AbigailBerthe/S-VoCAL .
Beyond Musical Descriptors: Extracting Preference-Bearing Intent in Music Queries
Feb 11, 2026Although annotated music descriptor datasets for user queries are increasingly common, few consider the user's intent behind these descriptors, which is essential for effectively meeting their needs. We introduce MusicRecoIntent, a manually annotated corpus of 2,291 Reddit music requests, labeling musical descriptors across seven categories with positive, negative, or referential preference-bearing roles. We then investigate how reliably large language models (LLMs) can extract these music descriptors, finding that they do capture explicit descriptors but struggle with context-dependent ones. This work can further serve as a benchmark for fine-grained modeling of user intent and for gaining insights into improving LLM-based music understanding systems.
Scalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings
Jan 16, 2026Music Cover Retrieval, also known as Version Identification, aims to recognize distinct renditions of the same underlying musical work, a task central to catalog management, copyright enforcement, and music retrieval. State-of-the-art approaches have largely focused on harmonic and melodic features, employing increasingly complex audio pipelines designed to be invariant to musical attributes that often vary widely across covers. While effective, these methods demand substantial training time and computational resources. By contrast, lyrics constitute a strong invariant across covers, though their use has been limited by the difficulty of extracting them accurately and efficiently from polyphonic audio. Early methods relied on simple frameworks that limited downstream performance, while more recent systems deliver stronger results but require large models integrated within complex multimodal architectures. We introduce LIVI (Lyrics-Informed Version Identification), an approach that seeks to balance retrieval accuracy with computational efficiency. First, LIVI leverages supervision from state-of-the-art transcription and text embedding models during training to achieve retrieval accuracy on par with--or superior to--harmonic-based systems. Second, LIVI remains lightweight and efficient by removing the transcription step at inference, challenging the dominance of complexity-heavy pipelines.
LibriQuote: A Speech Dataset of Fictional Character Utterances for Expressive Zero-Shot Speech Synthesis
Sep 04, 2025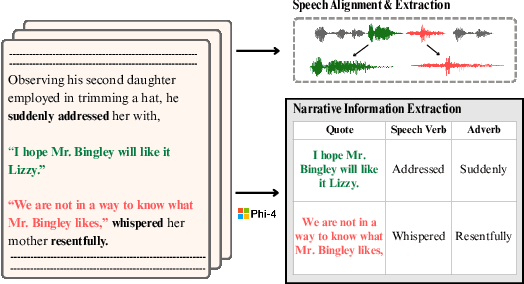
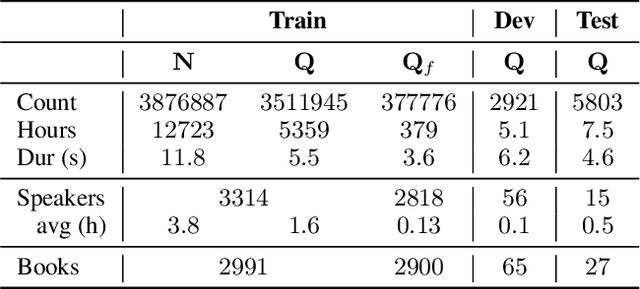
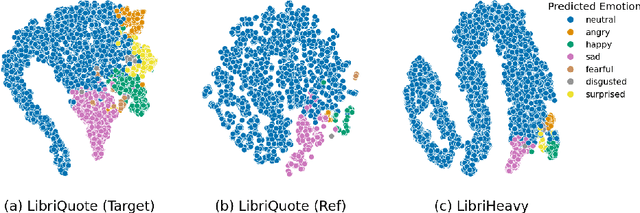
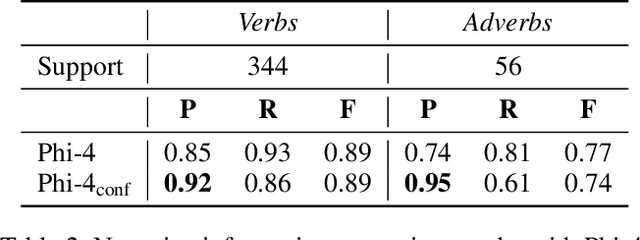
Text-to-speech (TTS) systems have recently achieved more expressive and natural speech synthesis by scaling to large speech datasets. However, the proportion of expressive speech in such large-scale corpora is often unclear. Besides, existing expressive speech corpora are typically smaller in scale and primarily used for benchmarking TTS systems. In this paper, we introduce the LibriQuote dataset, an English corpus derived from read audiobooks, designed for both fine-tuning and benchmarking expressive zero-shot TTS system. The training dataset includes 12.7K hours of read, non-expressive speech and 5.3K hours of mostly expressive speech drawn from character quotations. Each utterance in the expressive subset is supplemented with the context in which it was written, along with pseudo-labels of speech verbs and adverbs used to describe the quotation (\textit{e.g. ``he whispered softly''}). Additionally, we provide a challenging 7.5 hour test set intended for benchmarking TTS systems: given a neutral reference speech as input, we evaluate system's ability to synthesize an expressive utterance while preserving reference timbre. We validate qualitatively the test set by showing that it covers a wide range of emotions compared to non-expressive speech, along with various accents. Extensive subjective and objective evaluations show that fine-tuning a baseline TTS system on LibriQuote significantly improves its synthesized speech intelligibility, and that recent systems fail to synthesize speech as expressive and natural as the ground-truth utterances. The dataset and evaluation code are freely available. Audio samples can be found at https://libriquote.github.io/.
Biases in LLM-Generated Musical Taste Profiles for Recommendation
Jul 22, 2025One particularly promising use case of Large Language Models (LLMs) for recommendation is the automatic generation of Natural Language (NL) user taste profiles from consumption data. These profiles offer interpretable and editable alternatives to opaque collaborative filtering representations, enabling greater transparency and user control. However, it remains unclear whether users consider these profiles to be an accurate representation of their taste, which is crucial for trust and usability. Moreover, because LLMs inherit societal and data-driven biases, profile quality may systematically vary across user and item characteristics. In this paper, we study this issue in the context of music streaming, where personalization is challenged by a large and culturally diverse catalog. We conduct a user study in which participants rate NL profiles generated from their own listening histories. We analyze whether identification with the profiles is biased by user attributes (e.g., mainstreamness, taste diversity) and item features (e.g., genre, country of origin). We also compare these patterns to those observed when using the profiles in a downstream recommendation task. Our findings highlight both the potential and limitations of scrutable, LLM-based profiling in personalized systems.
Harnessing High-Level Song Descriptors towards Natural Language-Based Music Recommendation
Nov 08, 2024



Recommender systems relying on Language Models (LMs) have gained popularity in assisting users to navigate large catalogs. LMs often exploit item high-level descriptors, i.e. categories or consumption contexts, from training data or user preferences. This has been proven effective in domains like movies or products. However, in the music domain, understanding how effectively LMs utilize song descriptors for natural language-based music recommendation is relatively limited. In this paper, we assess LMs effectiveness in recommending songs based on user natural language descriptions and items with descriptors like genres, moods, and listening contexts. We formulate the recommendation task as a dense retrieval problem and assess LMs as they become increasingly familiar with data pertinent to the task and domain. Our findings reveal improved performance as LMs are fine-tuned for general language similarity, information retrieval, and mapping longer descriptions to shorter, high-level descriptors in music.
Detecting Synthetic Lyrics with Few-Shot Inference
Jun 21, 2024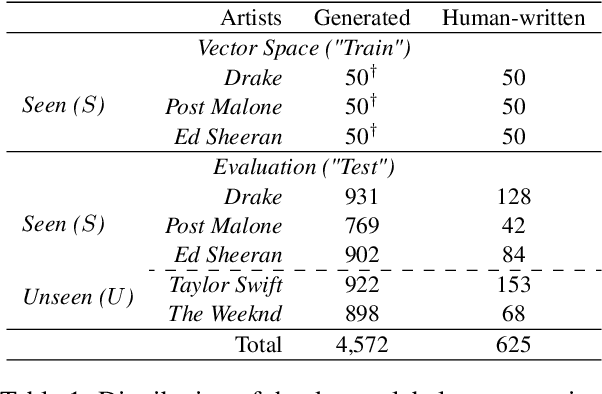

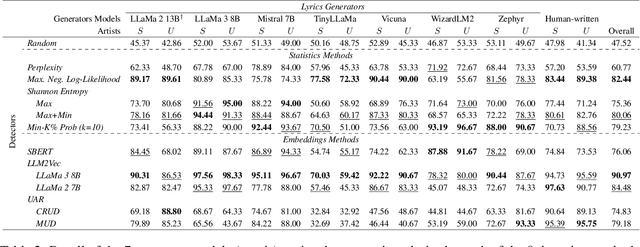
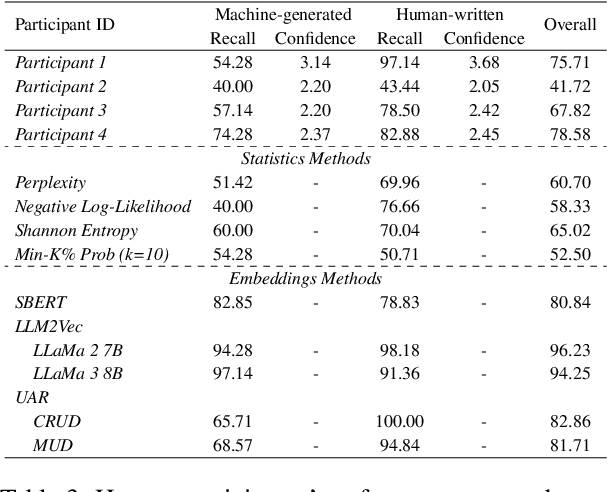
In recent years, generated content in music has gained significant popularity, with large language models being effectively utilized to produce human-like lyrics in various styles, themes, and linguistic structures. This technological advancement supports artists in their creative processes but also raises issues of authorship infringement, consumer satisfaction and content spamming. To address these challenges, methods for detecting generated lyrics are necessary. However, existing works have not yet focused on this specific modality or on creative text in general regarding machine-generated content detection methods and datasets. In response, we have curated the first dataset of high-quality synthetic lyrics and conducted a comprehensive quantitative evaluation of various few-shot content detection approaches, testing their generalization capabilities and complementing this with a human evaluation. Our best few-shot detector, based on LLM2Vec, surpasses stylistic and statistical methods, which are shown competitive in other domains at distinguishing human-written from machine-generated content. It also shows good generalization capabilities to new artists and models, and effectively detects post-generation paraphrasing. This study emphasizes the need for further research on creative content detection, particularly in terms of generalization and scalability with larger song catalogs. All datasets, pre-processing scripts, and code are available publicly on GitHub and Hugging Face under the Apache 2.0 license.
Improving Quotation Attribution with Fictional Character Embeddings
Jun 17, 2024



Humans naturally attribute utterances of direct speech to their speaker in literary works. When attributing quotes, we process contextual information but also access mental representations of characters that we build and revise throughout the narrative. Recent methods to automatically attribute such utterances have explored simulating human logic with deterministic rules or learning new implicit rules with neural networks when processing contextual information. However, these systems inherently lack \textit{character} representations, which often leads to errors on more challenging examples of attribution: anaphoric and implicit quotes. In this work, we propose to augment a popular quotation attribution system, BookNLP, with character embeddings that encode global information of characters. To build these embeddings, we create DramaCV, a corpus of English drama plays from the 15th to 20th century focused on Character Verification (CV), a task similar to Authorship Verification (AV), that aims at analyzing fictional characters. We train a model similar to the recently proposed AV model, Universal Authorship Representation (UAR), on this dataset, showing that it outperforms concurrent methods of characters embeddings on the CV task and generalizes better to literary novels. Then, through an extensive evaluation on 22 novels, we show that combining BookNLP's contextual information with our proposed global character embeddings improves the identification of speakers for anaphoric and implicit quotes, reaching state-of-the-art performance. Code and data will be made publicly available.
A Realistic Evaluation of LLMs for Quotation Attribution in Literary Texts: A Case Study of LLaMa3
Jun 17, 2024Large Language Models (LLMs) zero-shot and few-shot performance are subject to memorization and data contamination, complicating the assessment of their validity. In literary tasks, the performance of LLMs is often correlated to the degree of book memorization. In this work, we carry out a realistic evaluation of LLMs for quotation attribution in novels, taking the instruction fined-tuned version of Llama3 as an example. We design a task-specific memorization measure and use it to show that Llama3's ability to perform quotation attribution is positively correlated to the novel degree of memorization. However, Llama3 still performs impressively well on books it has not memorized nor seen. Data and code will be made publicly available.