 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025
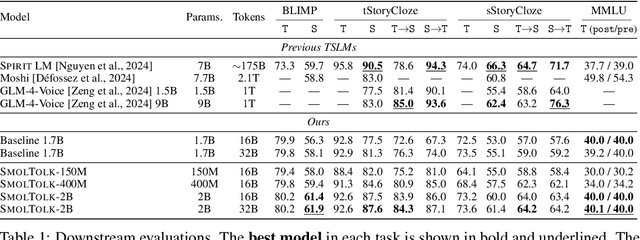
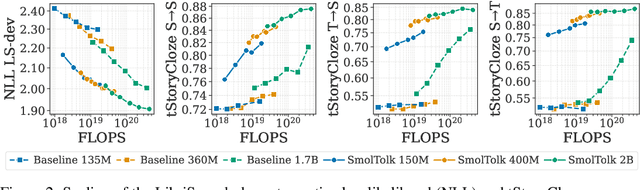
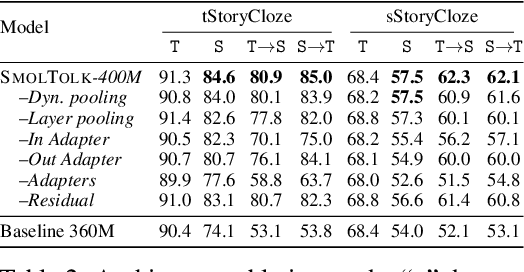
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
Detecting Synthetic Lyrics with Few-Shot Inference
Jun 21, 2024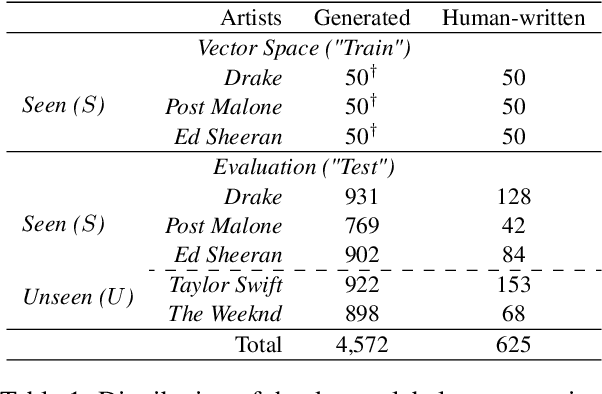

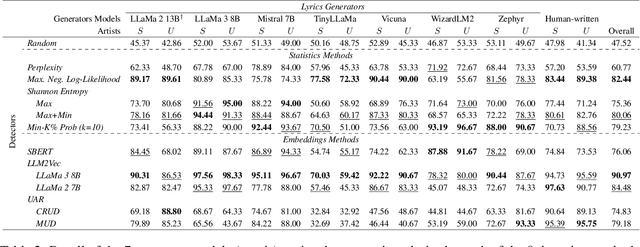
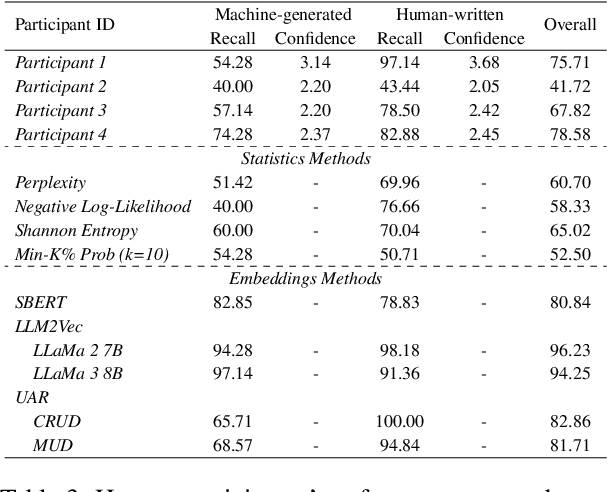
In recent years, generated content in music has gained significant popularity, with large language models being effectively utilized to produce human-like lyrics in various styles, themes, and linguistic structures. This technological advancement supports artists in their creative processes but also raises issues of authorship infringement, consumer satisfaction and content spamming. To address these challenges, methods for detecting generated lyrics are necessary. However, existing works have not yet focused on this specific modality or on creative text in general regarding machine-generated content detection methods and datasets. In response, we have curated the first dataset of high-quality synthetic lyrics and conducted a comprehensive quantitative evaluation of various few-shot content detection approaches, testing their generalization capabilities and complementing this with a human evaluation. Our best few-shot detector, based on LLM2Vec, surpasses stylistic and statistical methods, which are shown competitive in other domains at distinguishing human-written from machine-generated content. It also shows good generalization capabilities to new artists and models, and effectively detects post-generation paraphrasing. This study emphasizes the need for further research on creative content detection, particularly in terms of generalization and scalability with larger song catalogs. All datasets, pre-processing scripts, and code are available publicly on GitHub and Hugging Face under the Apache 2.0 license.
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Jun 09, 2024In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5\%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
* Accepted to INTERSPEECH 2024
How Important Is Tokenization in French Medical Masked Language Models?
Feb 22, 2024Subword tokenization has become the prevailing standard in the field of natural language processing (NLP) over recent years, primarily due to the widespread utilization of pre-trained language models. This shift began with Byte-Pair Encoding (BPE) and was later followed by the adoption of SentencePiece and WordPiece. While subword tokenization consistently outperforms character and word-level tokenization, the precise factors contributing to its success remain unclear. Key aspects such as the optimal segmentation granularity for diverse tasks and languages, the influence of data sources on tokenizers, and the role of morphological information in Indo-European languages remain insufficiently explored. This is particularly pertinent for biomedical terminology, characterized by specific rules governing morpheme combinations. Despite the agglutinative nature of biomedical terminology, existing language models do not explicitly incorporate this knowledge, leading to inconsistent tokenization strategies for common terms. In this paper, we seek to delve into the complexities of subword tokenization in French biomedical domain across a variety of NLP tasks and pinpoint areas where further enhancements can be made. We analyze classical tokenization algorithms, including BPE and SentencePiece, and introduce an original tokenization strategy that integrates morpheme-enriched word segmentation into existing tokenization methods.
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024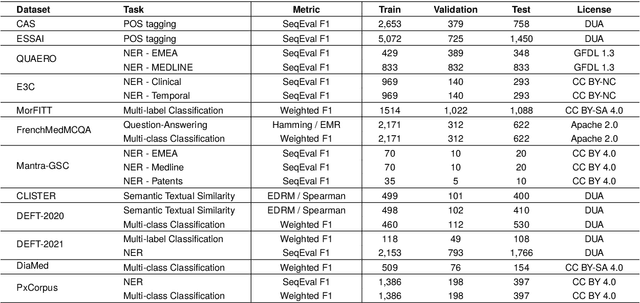
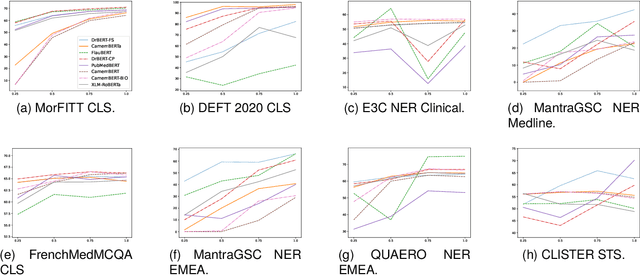
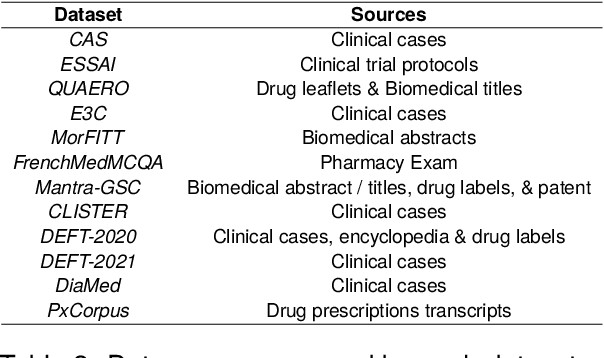
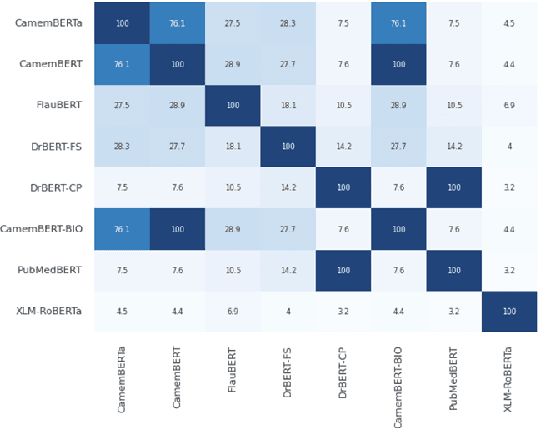
The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Feb 15, 2024



Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges. In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Jul 22, 2023We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain
Apr 09, 2023


This paper introduces FrenchMedMCQA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers. Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s). We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though FrenchMedMCQA is in French. Corpus, models and tools are available online.
DrBERT: A Robust Pre-trained Model in French for Biomedical and Clinical domains
Apr 03, 2023In recent years, pre-trained language models (PLMs) achieve the best performance on a wide range of natural language processing (NLP) tasks. While the first models were trained on general domain data, specialized ones have emerged to more effectively treat specific domains. In this paper, we propose an original study of PLMs in the medical domain on French language. We compare, for the first time, the performance of PLMs trained on both public data from the web and private data from healthcare establishments. We also evaluate different learning strategies on a set of biomedical tasks. In particular, we show that we can take advantage of already existing biomedical PLMs in a foreign language by further pre-train it on our targeted data. Finally, we release the first specialized PLMs for the biomedical field in French, called DrBERT, as well as the largest corpus of medical data under free license on which these models are trained.