 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Paper and Code
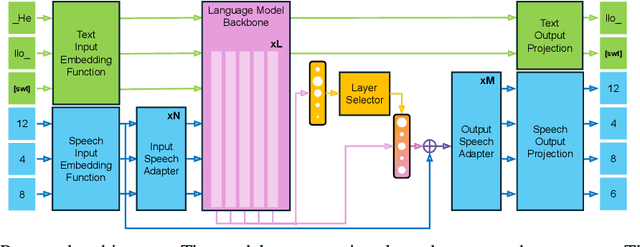
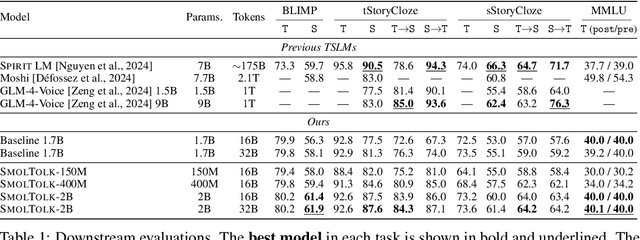
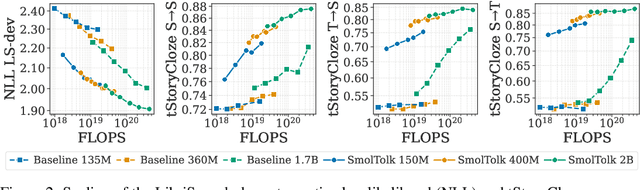
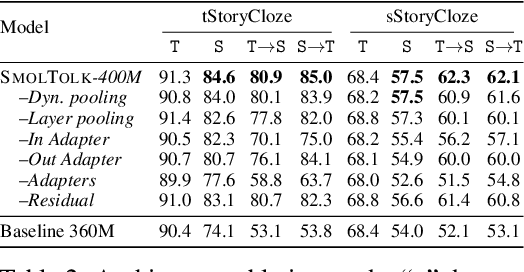
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.