 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Real to Cloned Singer Identification
Jul 11, 2024
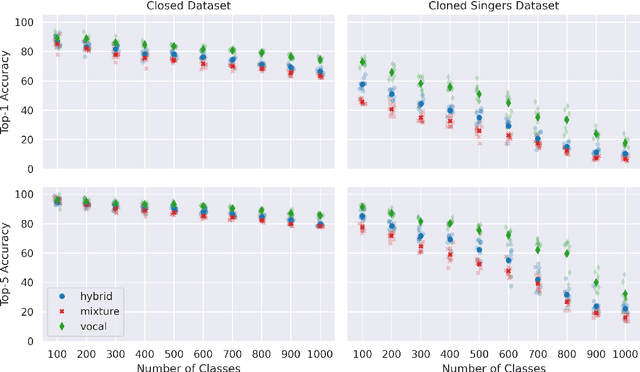

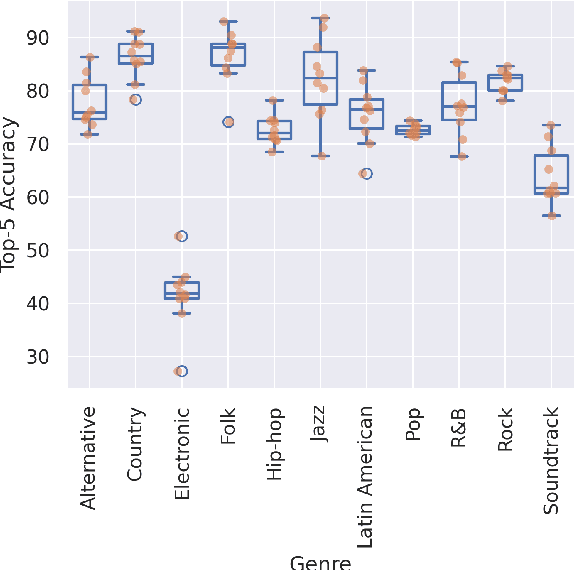
Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
An Experimental Comparison Of Multi-view Self-supervised Methods For Music Tagging
Apr 14, 2024


Self-supervised learning has emerged as a powerful way to pre-train generalizable machine learning models on large amounts of unlabeled data. It is particularly compelling in the music domain, where obtaining labeled data is time-consuming, error-prone, and ambiguous. During the self-supervised process, models are trained on pretext tasks, with the primary objective of acquiring robust and informative features that can later be fine-tuned for specific downstream tasks. The choice of the pretext task is critical as it guides the model to shape the feature space with meaningful constraints for information encoding. In the context of music, most works have relied on contrastive learning or masking techniques. In this study, we expand the scope of pretext tasks applied to music by investigating and comparing the performance of new self-supervised methods for music tagging. We open-source a simple ResNet model trained on a diverse catalog of millions of tracks. Our results demonstrate that, although most of these pre-training methods result in similar downstream results, contrastive learning consistently results in better downstream performance compared to other self-supervised pre-training methods. This holds true in a limited-data downstream context.
Music Augmentation and Denoising For Peak-Based Audio Fingerprinting
Oct 29, 2023



Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions.
Self-Supervised Beat Tracking in Musical Signals with Polyphonic Contrastive Learning
Jan 05, 2022

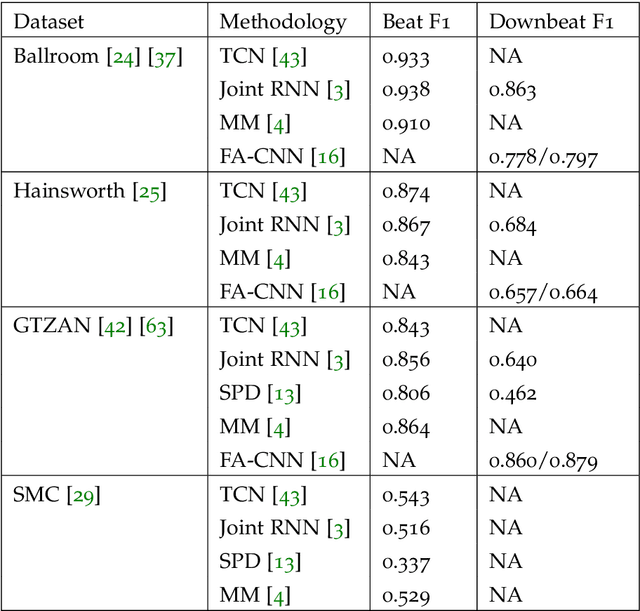
Annotating musical beats is a very long in tedious process. In order to combat this problem, we present a new self-supervised learning pretext task for beat tracking and downbeat estimation. This task makes use of Spleeter, an audio source separation model, to separate a song's drums from the rest of its signal. The first set of signals are used as positives, and by extension negatives, for contrastive learning pre-training. The drum-less signals, on the other hand, are used as anchors. When pre-training a fully-convolutional and recurrent model using this pretext task, an onset function is learned. In some cases, this function was found to be mapped to periodic elements in a song. We found that pre-trained models outperformed randomly initialized models when a beat tracking training set was extremely small (less than 10 examples). When that was not the case, pre-training led to a learning speed-up that caused the model to overfit to the training set. More generally, this work defines new perspectives in the realm of musical self-supervised learning. It is notably one of the first works to use audio source separation as a fundamental component of self-supervision.