 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Beat Tracking in Musical Signals with Polyphonic Contrastive Learning
Paper and Code
Jan 05, 2022

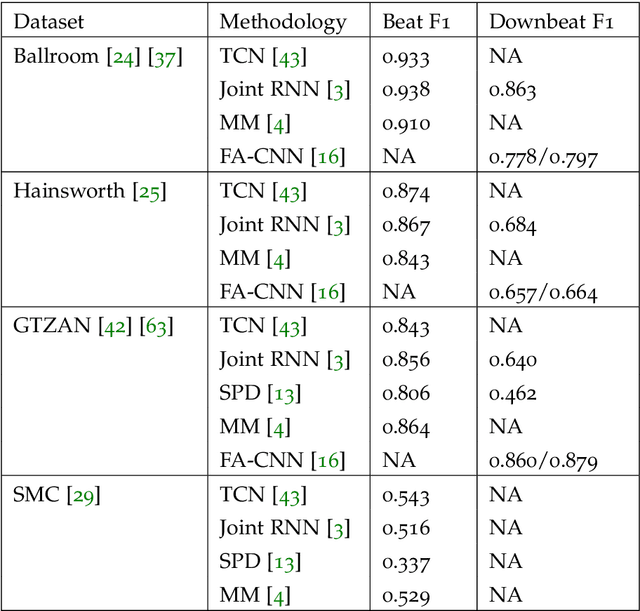
Annotating musical beats is a very long in tedious process. In order to combat this problem, we present a new self-supervised learning pretext task for beat tracking and downbeat estimation. This task makes use of Spleeter, an audio source separation model, to separate a song's drums from the rest of its signal. The first set of signals are used as positives, and by extension negatives, for contrastive learning pre-training. The drum-less signals, on the other hand, are used as anchors. When pre-training a fully-convolutional and recurrent model using this pretext task, an onset function is learned. In some cases, this function was found to be mapped to periodic elements in a song. We found that pre-trained models outperformed randomly initialized models when a beat tracking training set was extremely small (less than 10 examples). When that was not the case, pre-training led to a learning speed-up that caused the model to overfit to the training set. More generally, this work defines new perspectives in the realm of musical self-supervised learning. It is notably one of the first works to use audio source separation as a fundamental component of self-supervision.