 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings
Jan 16, 2026Music Cover Retrieval, also known as Version Identification, aims to recognize distinct renditions of the same underlying musical work, a task central to catalog management, copyright enforcement, and music retrieval. State-of-the-art approaches have largely focused on harmonic and melodic features, employing increasingly complex audio pipelines designed to be invariant to musical attributes that often vary widely across covers. While effective, these methods demand substantial training time and computational resources. By contrast, lyrics constitute a strong invariant across covers, though their use has been limited by the difficulty of extracting them accurately and efficiently from polyphonic audio. Early methods relied on simple frameworks that limited downstream performance, while more recent systems deliver stronger results but require large models integrated within complex multimodal architectures. We introduce LIVI (Lyrics-Informed Version Identification), an approach that seeks to balance retrieval accuracy with computational efficiency. First, LIVI leverages supervision from state-of-the-art transcription and text embedding models during training to achieve retrieval accuracy on par with--or superior to--harmonic-based systems. Second, LIVI remains lightweight and efficient by removing the transcription step at inference, challenging the dominance of complexity-heavy pipelines.
Music Augmentation and Denoising For Peak-Based Audio Fingerprinting
Oct 29, 2023



Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions.
Formal Verification of Station Keeping Maneuvers for a Planar Autonomous Hybrid System
Sep 08, 2017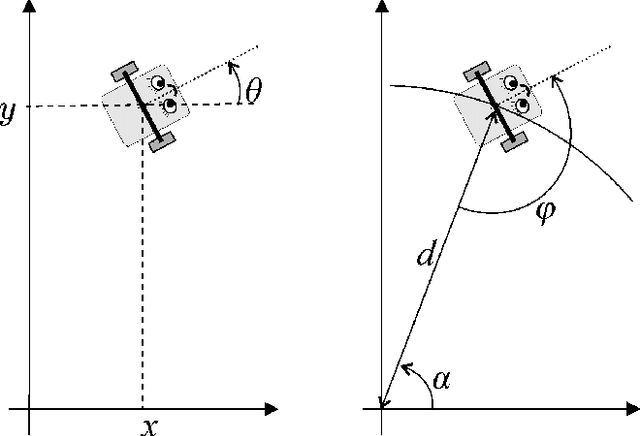
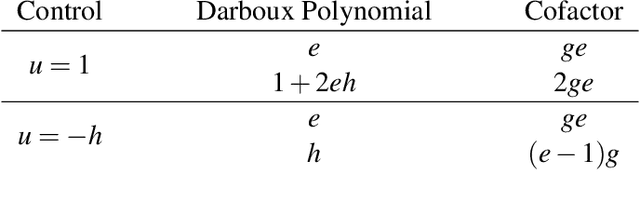
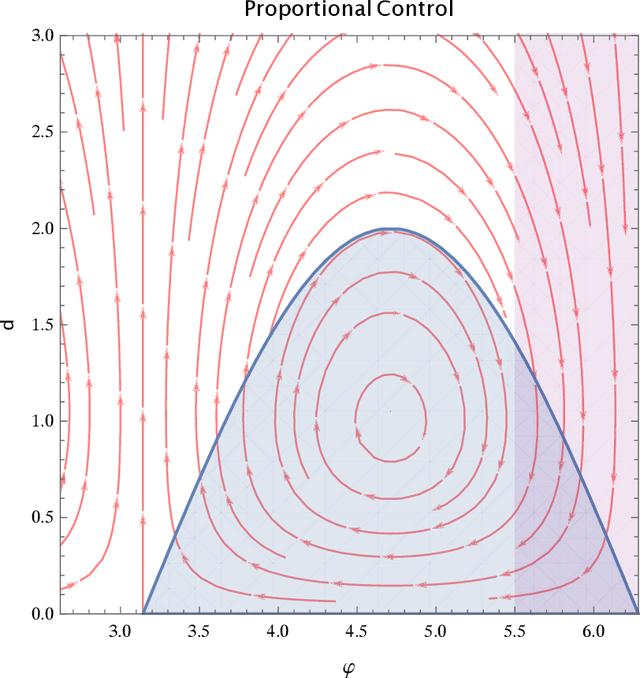
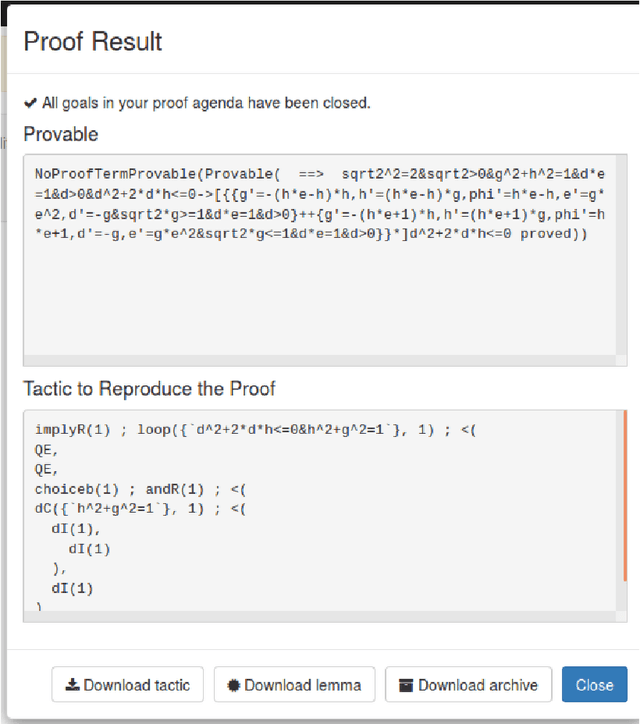
We formally verify a hybrid control law designed to perform a station keeping maneuver for a planar vehicle. Such maneuver requires that the vehicle reaches a neighborhood of its station in finite time and remains in it while waiting for further instructions. We model the dynamics as well as the control law as a hybrid program and formally verify both the reachability and safety properties involved. We highlight in particular the automated generation of invariant regions which turns out to be crucial in performing such verification. We use the theorem prover Keymaera X to discharge some of the generated proof obligations.
* In Proceedings FVAV 2017, arXiv:1709.02126