 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Music Genre Perception across Language-Bound Cultures
Oct 13, 2020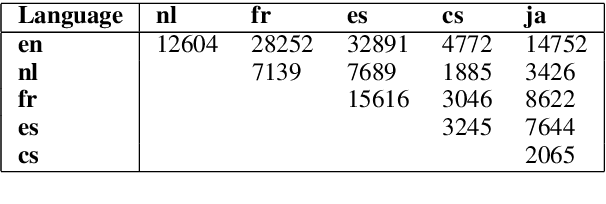
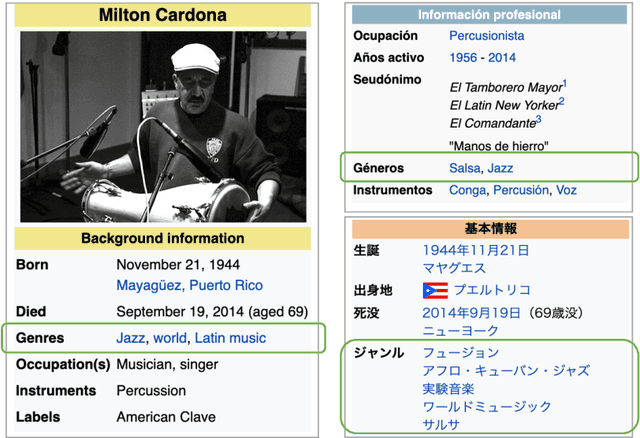
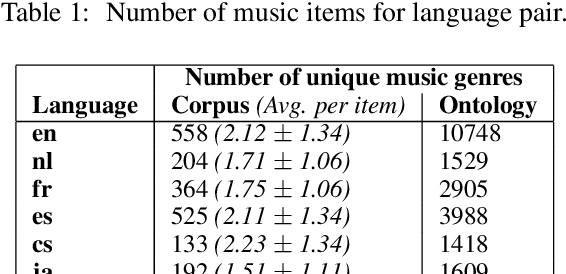
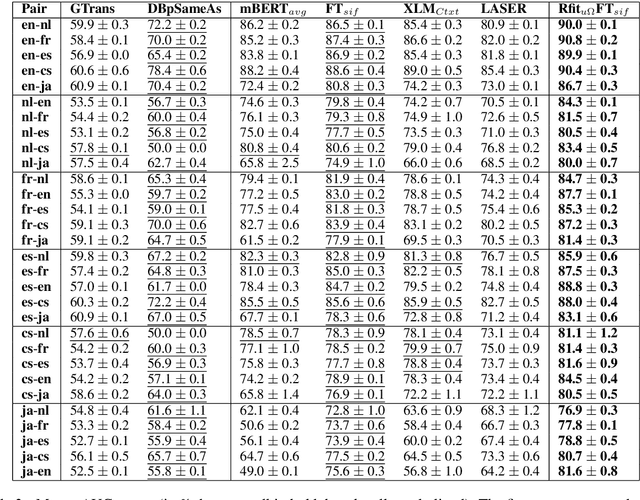
The music genre perception expressed through human annotations of artists or albums varies significantly across language-bound cultures. These variations cannot be modeled as mere translations since we also need to account for cultural differences in the music genre perception. In this work, we study the feasibility of obtaining relevant cross-lingual, culture-specific music genre annotations based only on language-specific semantic representations, namely distributed concept embeddings and ontologies. Our study, focused on six languages, shows that unsupervised cross-lingual music genre annotation is feasible with high accuracy, especially when combining both types of representations. This approach of studying music genres is the most extensive to date and has many implications in musicology and music information retrieval. Besides, we introduce a new, domain-dependent cross-lingual corpus to benchmark state of the art multilingual pre-trained embedding models.
Carousel Personalization in Music Streaming Apps with Contextual Bandits
Sep 30, 2020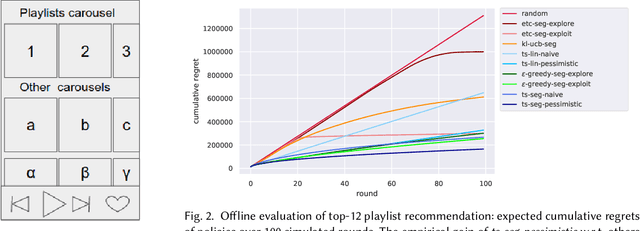
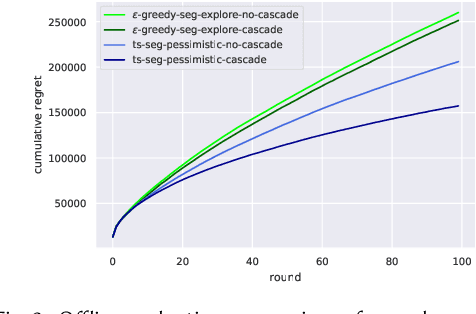
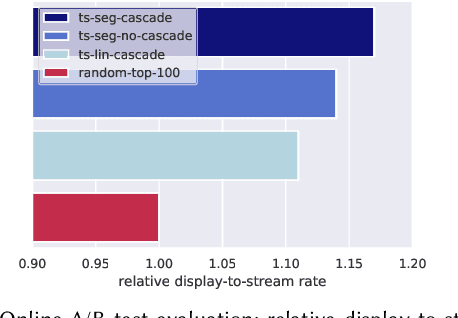
Media services providers, such as music streaming platforms, frequently leverage swipeable carousels to recommend personalized content to their users. However, selecting the most relevant items (albums, artists, playlists...) to display in these carousels is a challenging task, as items are numerous and as users have different preferences. In this paper, we model carousel personalization as a contextual multi-armed bandit problem with multiple plays, cascade-based updates and delayed batch feedback. We empirically show the effectiveness of our framework at capturing characteristics of real-world carousels by addressing a large-scale playlist recommendation task on a global music streaming mobile app. Along with this paper, we publicly release industrial data from our experiments, as well as an open-source environment to simulate comparable carousel personalization learning problems.
Multilingual Music Genre Embeddings for Effective Cross-Lingual Music Item Annotation
Sep 16, 2020



Annotating music items with music genres is crucial for music recommendation and information retrieval, yet challenging given that music genres are subjective concepts. Recently, in order to explicitly consider this subjectivity, the annotation of music items was modeled as a translation task: predict for a music item its music genres within a target vocabulary or taxonomy (tag system) from a set of music genre tags originating from other tag systems. However, without a parallel corpus, previous solutions could not handle tag systems in other languages, being limited to the English-language only. Here, by learning multilingual music genre embeddings, we enable cross-lingual music genre translation without relying on a parallel corpus. First, we apply compositionality functions on pre-trained word embeddings to represent multi-word tags.Second, we adapt the tag representations to the music domain by leveraging multilingual music genres graphs with a modified retrofitting algorithm. Experiments show that our method: 1) is effective in translating music genres across tag systems in multiple languages (English, French and Spanish); 2) outperforms the previous baseline in an English-language multi-source translation task. We publicly release the new multilingual data and code.
FastGAE: Fast, Scalable and Effective Graph Autoencoders with Stochastic Subgraph Decoding
Feb 20, 2020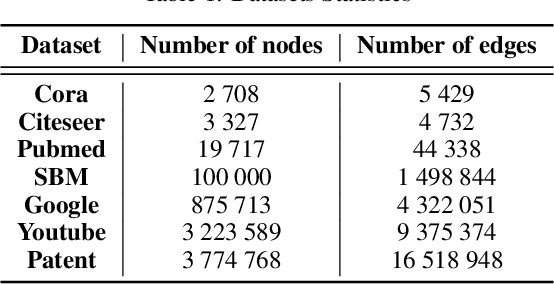
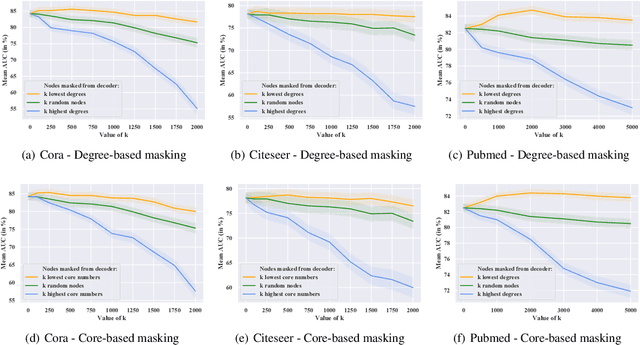
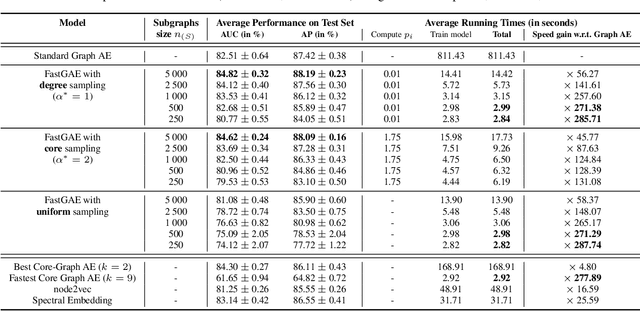
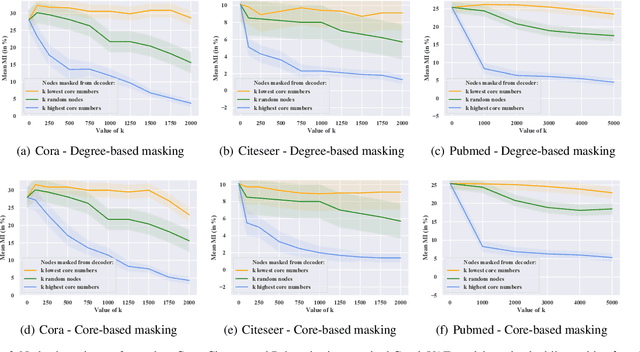
Graph autoencoders (AE) and variational autoencoders (VAE) are powerful node embedding methods, but suffer from scalability issues. In this paper, we introduce FastGAE, a general framework to scale graph AE and VAE to large graphs with millions of nodes and edges. Our strategy, based on node sampling and subgraph decoding, significantly speeds up the training of graph AE and VAE while preserving or even improving performances. We demonstrate the effectiveness of FastGAE on numerous real-world graphs, outperforming the few existing approaches to scale graph AE and VAE by a wide margin.
Simple and Effective Graph Autoencoders with One-Hop Linear Models
Jan 21, 2020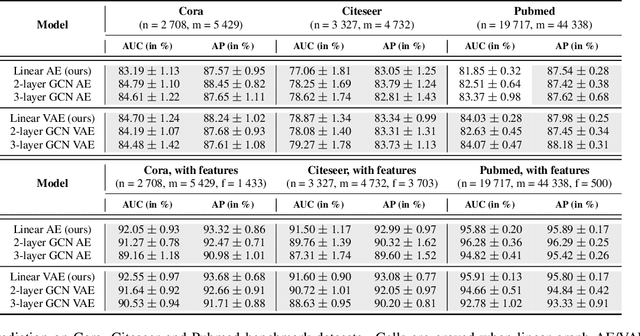
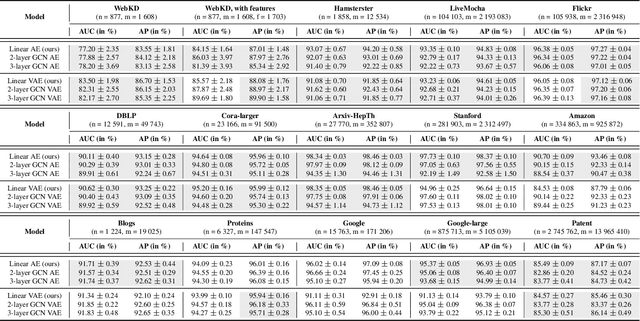
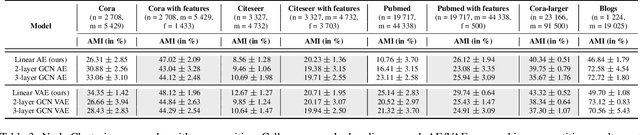
Graph autoencoders (AE) and variational autoencoders (VAE) recently emerged as powerful node embedding methods, with promising performances on challenging tasks such as link prediction and node clustering. Graph AE, VAE and most of their extensions rely on graph convolutional networks (GCN) encoders to learn vector space representations of nodes. In this paper, we propose to replace the GCN encoder by a significantly simpler linear model w.r.t. the direct neighborhood (one-hop) adjacency matrix of the graph. For the two aforementioned tasks, we show that this approach consistently reaches competitive performances w.r.t. GCN-based models for numerous real-world graphs, including all benchmark datasets commonly used to evaluate graph AE and VAE. We question the relevance of repeatedly using these datasets to compare complex graph AE and VAE. We also emphasize the effectiveness of the proposed encoding scheme, that appears as a simpler and faster alternative to GCN encoders for many real-world applications.
Keep It Simple: Graph Autoencoders Without Graph Convolutional Networks
Oct 02, 2019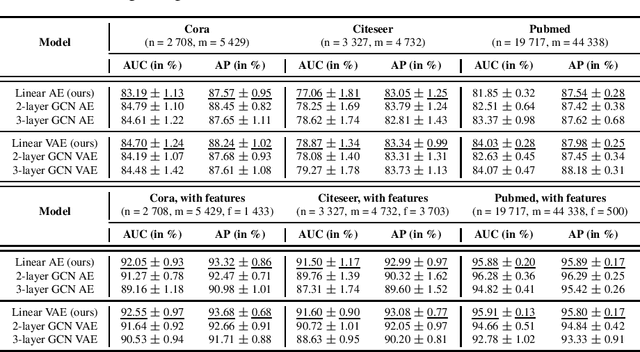
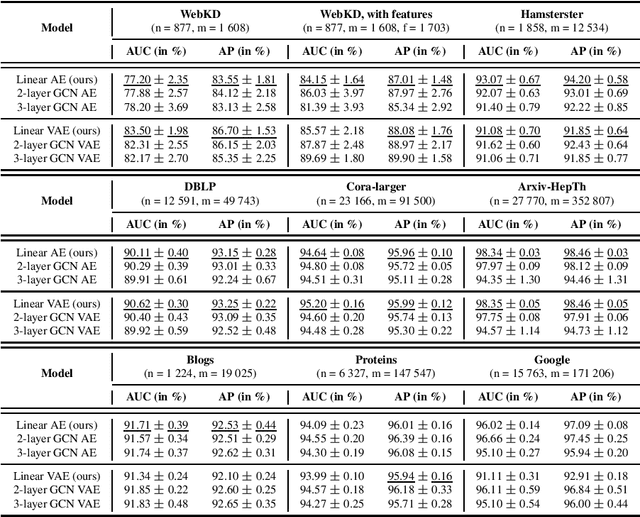
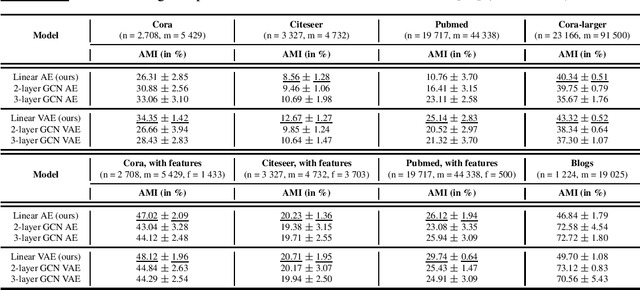
Graph autoencoders (AE) and variational autoencoders (VAE) recently emerged as powerful node embedding methods, with promising performances on challenging tasks such as link prediction and node clustering. Graph AE, VAE and most of their extensions rely on graph convolutional networks (GCN) to learn vector space representations of nodes. In this paper, we propose to replace the GCN encoder by a simple linear model w.r.t. the adjacency matrix of the graph. For the two aforementioned tasks, we empirically show that this approach consistently reaches competitive performances w.r.t. GCN-based models for numerous real-world graphs, including the widely used Cora, Citeseer and Pubmed citation networks that became the de facto benchmark datasets for evaluating graph AE and VAE. This result questions the relevance of repeatedly using these three datasets to compare complex graph AE and VAE models. It also emphasizes the effectiveness of simple node encoding schemes for many real-world applications.
Gravity-Inspired Graph Autoencoders for Directed Link Prediction
May 24, 2019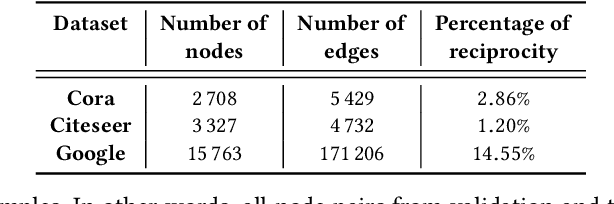
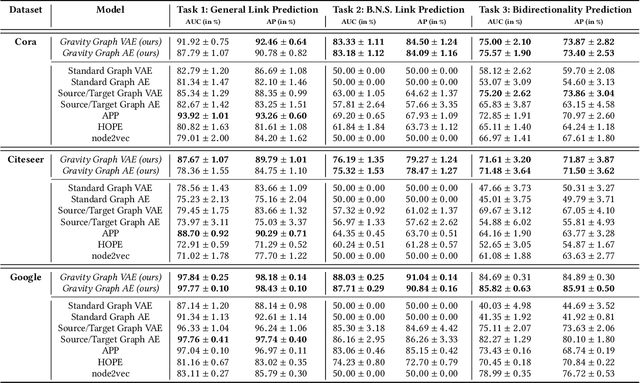

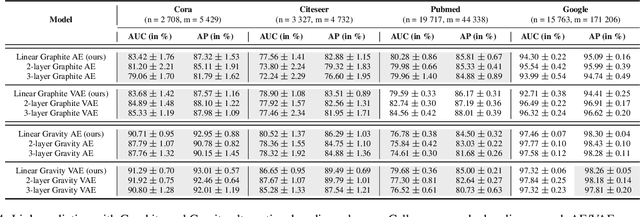
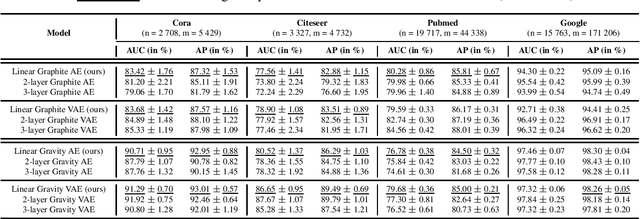
Graph autoencoders (AE) and variational autoencoders (VAE) recently emerged as powerful node embedding methods. In particular, graph AE and VAE were successfully leveraged to tackle the challenging link prediction problem, aiming at figuring out whether some pairs of nodes from a graph are connected by unobserved edges. However, these models focus on undirected graphs and therefore ignore the potential direction of the link, which is limiting for numerous real-life applications. In this paper, we extend the graph AE and VAE frameworks to address link prediction in directed graphs. We present a new gravity-inspired decoder scheme that can effectively reconstruct directed graphs from a node embedding. We empirically evaluate our method on three different directed link prediction tasks, for which standard graph AE and VAE perform poorly. We achieve competitive results on three real-world graphs, outperforming several popular baselines.
A Degeneracy Framework for Scalable Graph Autoencoders
Feb 23, 2019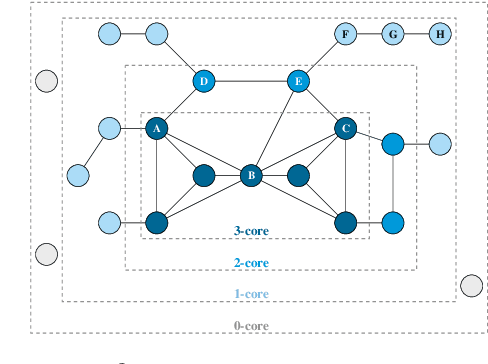
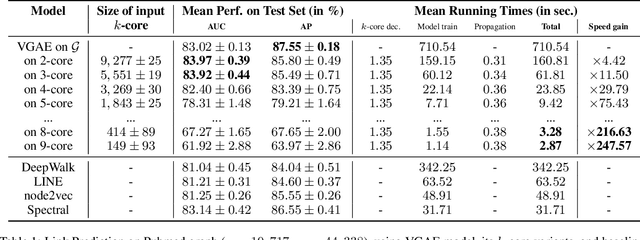
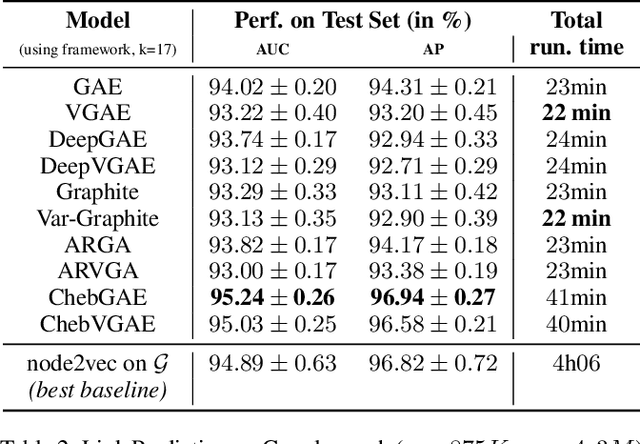
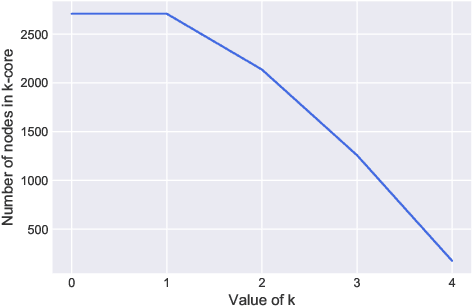
In this paper, we present a general framework to scale graph autoencoders (AE) and graph variational autoencoders (VAE). This framework leverages graph degeneracy concepts to train models only from a dense subset of nodes instead of using the entire graph. Together with a simple yet effective propagation mechanism, our approach significantly improves scalability and training speed while preserving performance. We evaluate and discuss our method on several variants of existing graph AE and VAE, providing the first application of these models to large graphs with up to millions of nodes and edges. We achieve empirically competitive results w.r.t. several popular scalable node embedding methods, which emphasizes the relevance of pursuing further research towards more scalable graph AE and VAE.