 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative models for two-ground-truth partitions in networks
Feb 06, 2023A myriad of approaches have been proposed to characterise the mesoscale structure of networks - most often as a partition based on patterns variously called communities, blocks, or clusters. Clearly, distinct methods designed to detect different types of patterns may provide a variety of answers to the network's mesoscale structure. Yet, even multiple runs of a given method can sometimes yield diverse and conflicting results, yielding entire landscapes of partitions which potentially include multiple (locally optimal) mesoscale explanations of the network. Such ambiguity motivates a closer look at the ability of these methods to find multiple qualitatively different 'ground truth' partitions in a network. Here, we propose a generative model which allows for two distinct partitions to be built into the mesoscale structure of a single benchmark network. We demonstrate a use case of the benchmark model by exploring the power of stochastic block models (SBMs) to detect coexisting bi-community and core-periphery structures of different strengths. We find that the ability to detect the two partitions individually varies considerably by SBM variant and that coexistence of both partitions is recovered only in a very limited number of cases. Our findings suggest that in most instances only one - in some way dominating - structure can be detected, even in the presence of other partitions in the generated network. They underline the need for considering entire landscapes of partitions when different competing explanations exist and motivate future research to advance partition coexistence detection methods. Our model also contributes to the field of benchmark networks more generally by enabling further exploration of the ability of new and existing methods to detect ambiguity in mesoscale structure of networks.
Follow the guides: disentangling human and algorithmic curation in online music consumption
Sep 08, 2021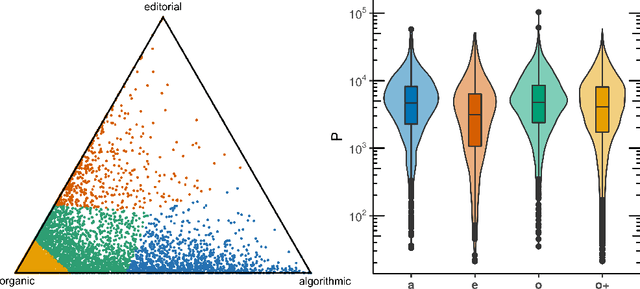

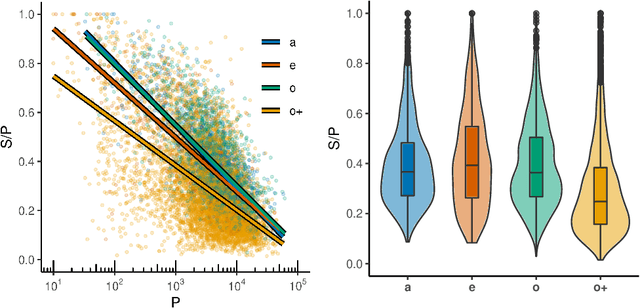
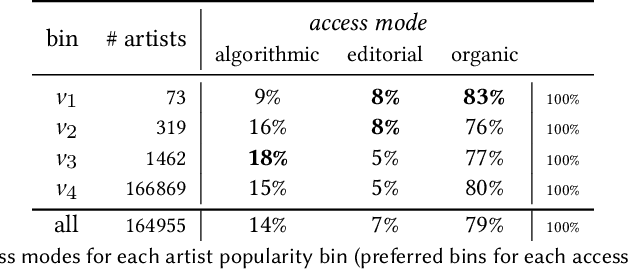
The role of recommendation systems in the diversity of content consumption on platforms is a much-debated issue. The quantitative state of the art often overlooks the existence of individual attitudes toward guidance, and eventually of different categories of users in this regard. Focusing on the case of music streaming, we analyze the complete listening history of about 9k users over one year and demonstrate that there is no blanket answer to the intertwinement of recommendation use and consumption diversity: it depends on users. First we compute for each user the relative importance of different access modes within their listening history, introducing a trichotomy distinguishing so-called `organic' use from algorithmic and editorial guidance. We thereby identify four categories of users. We then focus on two scales related to content diversity, both in terms of dispersion -- how much users consume the same content repeatedly -- and popularity -- how popular is the content they consume. We show that the two types of recommendation offered by music platforms -- algorithmic and editorial -- may drive the consumption of more or less diverse content in opposite directions, depending also strongly on the type of users. Finally, we compare users' streaming histories with the music programming of a selection of popular French radio stations during the same period. While radio programs are usually more tilted toward repetition than users' listening histories, they often program more songs from less popular artists. On the whole, our results highlight the nontrivial effects of platform-mediated recommendation on consumption, and lead us to speak of `filter niches' rather than `filter bubbles'. They hint at further ramifications for the study and design of recommendation systems.
Tracing Affordance and Item Adoption on Music Streaming Platforms
Sep 08, 2021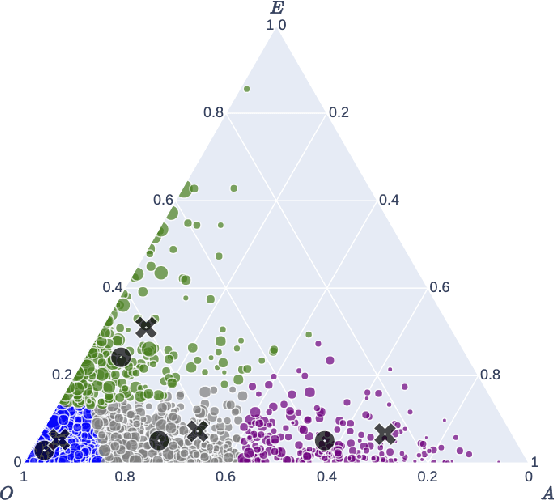
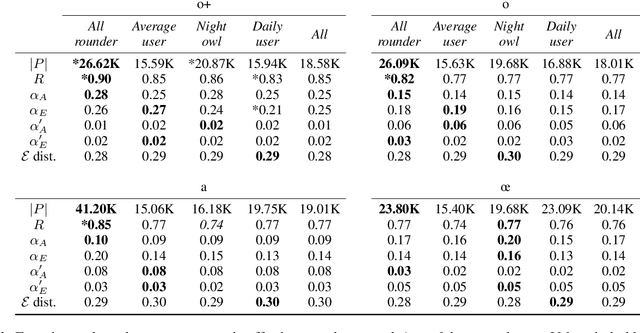
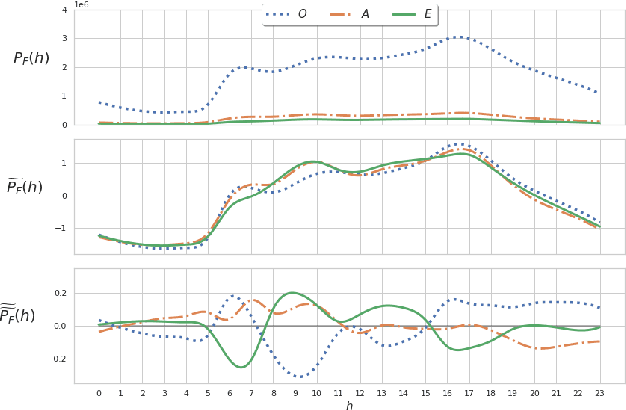
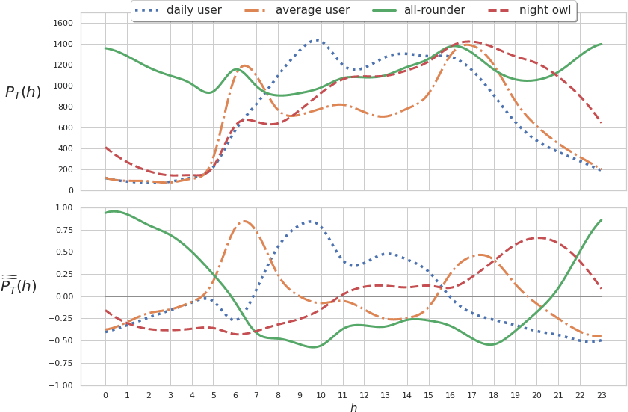
Popular music streaming platforms offer users a diverse network of content exploration through a triad of affordances: organic, algorithmic and editorial access modes. Whilst offering great potential for discovery, such platform developments also pose the modern user with daily adoption decisions on two fronts: platform affordance adoption and the adoption of recommendations therein. Following a carefully constrained set of Deezer users over a 2-year observation period, our work explores factors driving user behaviour in the broad sense, by differentiating users on the basis of their temporal daily usage, adoption of the main platform affordances, and the ways in which they react to them, especially in terms of recommendation adoption. Diverging from a perspective common in studies on the effects of recommendation, we assume and confirm that users exhibit very diverse behaviours in using and adopting the platform affordances. The resulting complex and quite heterogeneous picture demonstrates that there is no blanket answer for adoption practices of both recommendation features and recommendations.
Semantic Hypergraphs
Aug 28, 2019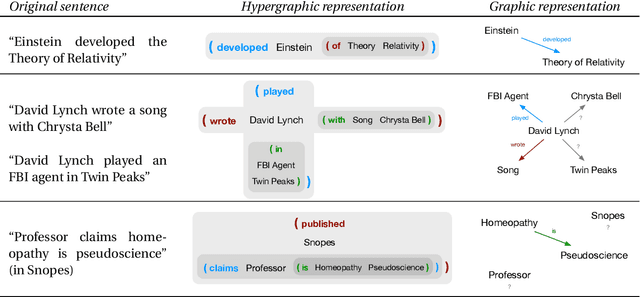
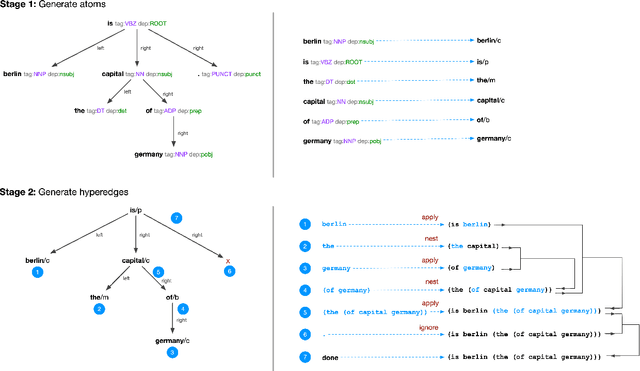

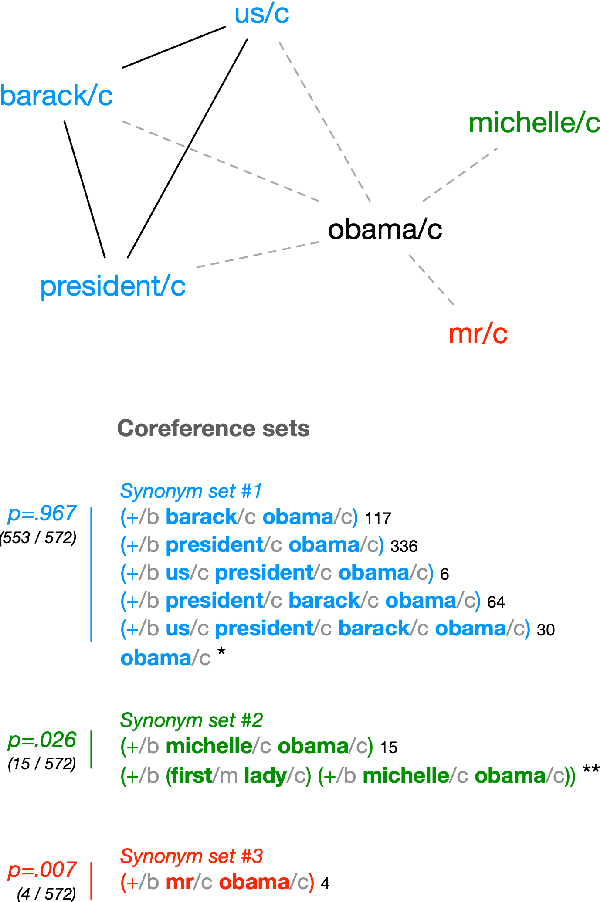
Existing computational methods for the analysis of corpora of text in natural language are still far from approaching a human level of understanding. We attempt to advance the state of the art by introducing a model and algorithmic framework to transform text into recursively structured data. We apply this to the analysis of news titles extracted from a social news aggregation website. We show that a recursive ordered hypergraph is a sufficiently generic structure to represent significant number of fundamental natural language constructs, with advantages over conventional approaches such as semantic graphs. We present a pipeline of transformations from the output of conventional NLP algorithms to such hypergraphs, which we denote as semantic hypergraphs. The features of these transformations include the creation of new concepts from existing ones, the organisation of statements into regular structures of predicates followed by an arbitrary number of entities and the ability to represent statements about other statements. We demonstrate knowledge inference from the hypergraph, identifying claims and expressions of conflicts, along with their participating actors and topics. We show how this enables the actor-centric summarization of conflicts, comparison of topics of claims between actors and networks of conflicts between actors in the context of a given topic. On the whole, we propose a hypergraphic knowledge representation model that can be used to provide effective overviews of a large corpus of text in natural language.
Algorithmic Distortion of Informational Landscapes
Jul 19, 2019The possible impact of algorithmic recommendation on the autonomy and free choice of Internet users is being increasingly discussed, especially in terms of the rendering of information and the structuring of interactions. This paper aims at reviewing and framing this issue along a double dichotomy. The first one addresses the discrepancy between users' intentions and actions (1) under some algorithmic influence and (2) without it. The second one distinguishes algorithmic biases on (1) prior information rearrangement and (2) posterior information arrangement. In all cases, we focus on and differentiate situations where algorithms empirically appear to expand the cognitive and social horizon of users, from those where they seem to limit that horizon. We additionally suggest that these biases may not be properly appraised without taking into account the underlying social processes which algorithms are building upon.
Automatic Discovery of Families of Network Generative Processes
Jun 26, 2019

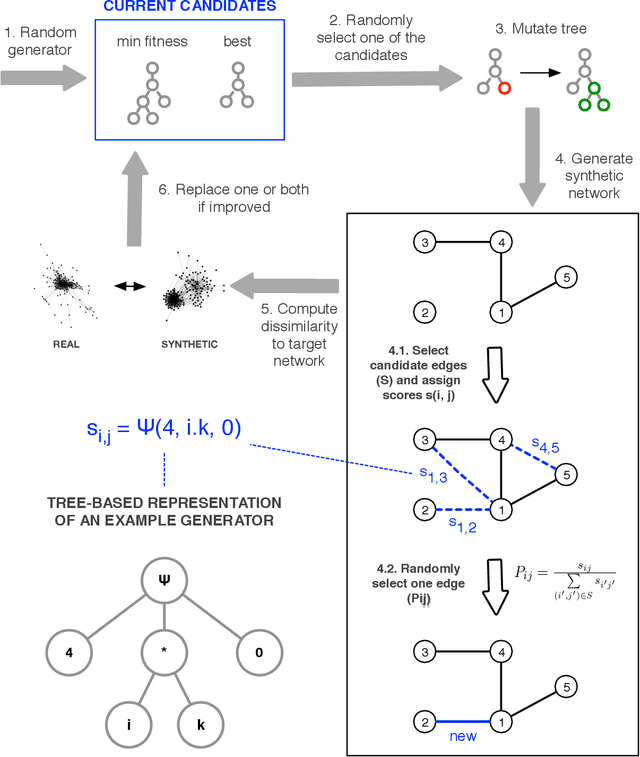
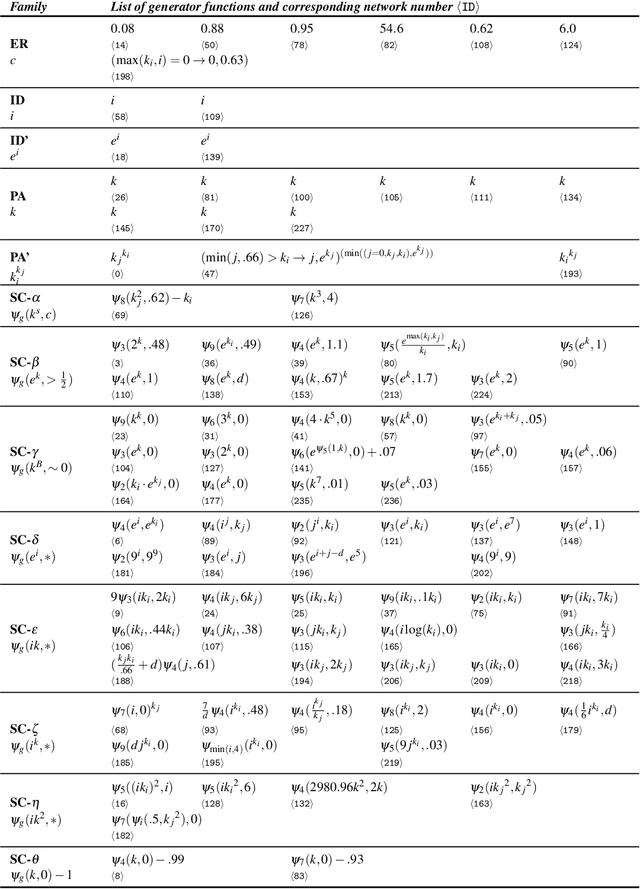
Designing plausible network models typically requires scholars to form a priori intuitions on the key drivers of network formation. Oftentimes, these intuitions are supported by the statistical estimation of a selection of network evolution processes which will form the basis of the model to be developed. Machine learning techniques have lately been introduced to assist the automatic discovery of generative models. These approaches may more broadly be described as "symbolic regression", where fundamental network dynamic functions, rather than just parameters, are evolved through genetic programming. This chapter first aims at reviewing the principles, efforts and the emerging literature in this direction, which is very much aligned with the idea of creating artificial scientists. Our contribution then aims more specifically at building upon an approach recently developed by us [Menezes \& Roth, 2014] in order to demonstrate the existence of families of networks that may be described by similar generative processes. In other words, symbolic regression may be used to group networks according to their inferred genotype (in terms of generative processes) rather than their observed phenotype (in terms of statistical/topological features). Our empirical case is based on an original data set of 238 anonymized ego-centered networks of Facebook friends, further yielding insights on the formation of sociability networks.
Symbolic regression of generative network models
Sep 08, 2014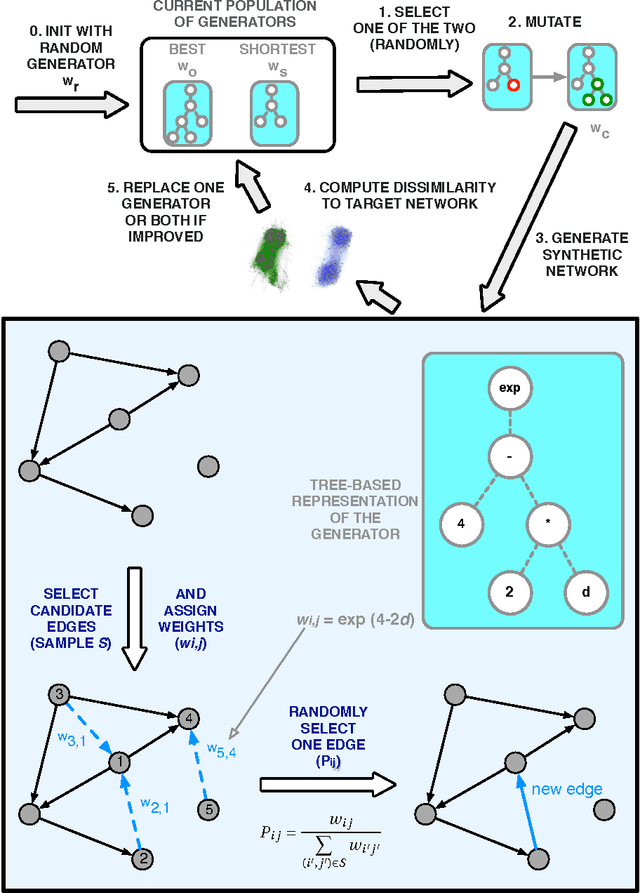
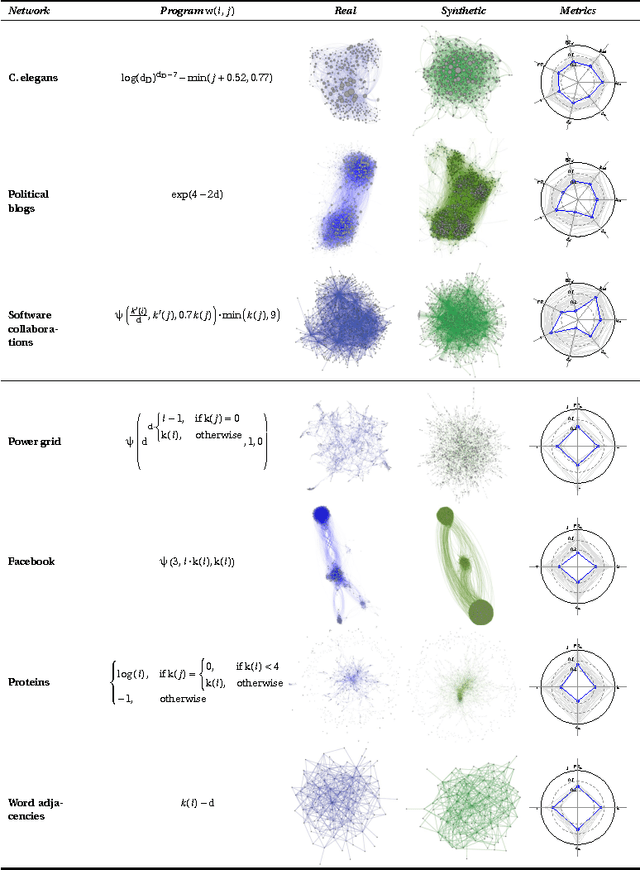
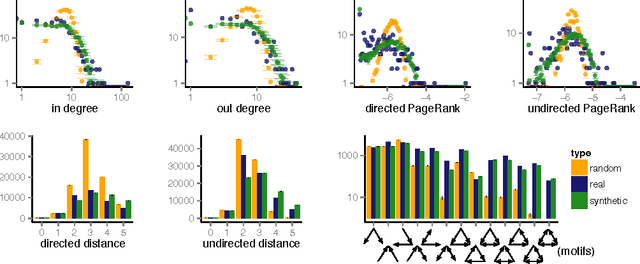
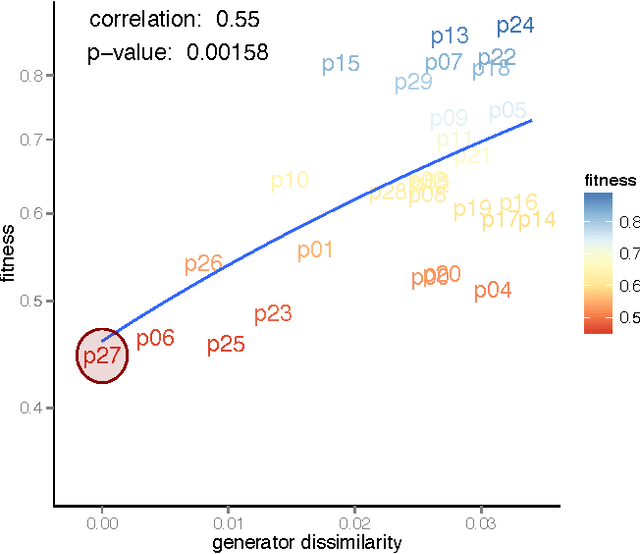
Networks are a powerful abstraction with applicability to a variety of scientific fields. Models explaining their morphology and growth processes permit a wide range of phenomena to be more systematically analysed and understood. At the same time, creating such models is often challenging and requires insights that may be counter-intuitive. Yet there currently exists no general method to arrive at better models. We have developed an approach to automatically detect realistic decentralised network growth models from empirical data, employing a machine learning technique inspired by natural selection and defining a unified formalism to describe such models as computer programs. As the proposed method is completely general and does not assume any pre-existing models, it can be applied "out of the box" to any given network. To validate our approach empirically, we systematically rediscover pre-defined growth laws underlying several canonical network generation models and credible laws for diverse real-world networks. We were able to find programs that are simple enough to lead to an actual understanding of the mechanisms proposed, namely for a simple brain and a social network.
Lattices for Dynamic, Hierarchic & Overlapping Categorization: the Case of Epistemic Communities
Sep 04, 2005



We present a method for hierarchic categorization and taxonomy evolution description. We focus on the structure of epistemic communities (ECs), or groups of agents sharing common knowledge concerns. Introducing a formal framework based on Galois lattices, we categorize ECs in an automated and hierarchically structured way and propose criteria for selecting the most relevant epistemic communities - for instance, ECs gathering a certain proportion of agents and thus prototypical of major fields. This process produces a manageable, insightful taxonomy of the community. Then, the longitudinal study of these static pictures makes possible an historical description. In particular, we capture stylized facts such as field progress, decline, specialization, interaction (merging or splitting), and paradigm emergence. The detection of such patterns in social networks could fruitfully be applied to other contexts.