 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRet: Efficient and High-Fidelity Omni Modality Retrieval
Mar 02, 2026Multimodal retrieval is the task of aggregating information from queries across heterogeneous modalities to retrieve desired targets. State-of-the-art multimodal retrieval models can understand complex queries, yet they are typically limited to two modalities: text and vision. This limitation impedes the development of universal retrieval systems capable of comprehending queries that combine more than two modalities. To advance toward this goal, we present OmniRet, the first retrieval model capable of handling complex, composed queries spanning three key modalities: text, vision, and audio. Our OmniRet model addresses two critical challenges for universal retrieval: computational efficiency and representation fidelity. First, feeding massive token sequences from modality-specific encoders to Large Language Models (LLMs) is computationally inefficient. We therefore introduce an attention-based resampling mechanism to generate compact, fixed-size representations from these sequences. Second, compressing rich omni-modal data into a single embedding vector inevitably causes information loss and discards fine-grained details. We propose Attention Sliced Wasserstein Pooling to preserve these fine-grained details, leading to improved omni-modal representations. OmniRet is trained on an aggregation of approximately 6 million query-target pairs spanning 30 datasets. We benchmark our model on 13 retrieval tasks and a MMEBv2 subset. Our model demonstrates significant improvements on composed query, audio and video retrieval tasks, while achieving on-par performance with state-of-the-art models on others. Furthermore, we curate a new Audio-Centric Multimodal Benchmark (ACM). This new benchmark introduces two critical, previously missing tasks-composed audio retrieval and audio-visual retrieval to more comprehensively evaluate a model's omni-modal embedding capacity.
Unbiased Sliced Wasserstein Kernels for High-Quality Audio Captioning
Feb 08, 2025



Teacher-forcing training for audio captioning usually leads to exposure bias due to training and inference mismatch. Prior works propose the contrastive method to deal with caption degeneration. However, the contrastive method ignores the temporal information when measuring similarity across acoustic and linguistic modalities, leading to inferior performance. In this work, we develop the temporal-similarity score by introducing the unbiased sliced Wasserstein RBF (USW-RBF) kernel equipped with rotary positional embedding to account for temporal information across modalities. In contrast to the conventional sliced Wasserstein RBF kernel, we can form an unbiased estimation of USW-RBF kernel via Monte Carlo estimation. Therefore, it is well-suited to stochastic gradient optimization algorithms, and its approximation error decreases at a parametric rate of $\mathcal{O}(L^{-1/2})$ with $L$ Monte Carlo samples. Additionally, we introduce an audio captioning framework based on the unbiased sliced Wasserstein kernel, incorporating stochastic decoding methods to mitigate caption degeneration during the generation process. We conduct extensive quantitative and qualitative experiments on two datasets, AudioCaps and Clotho, to illustrate the capability of generating high-quality audio captions. Experimental results show that our framework is able to increase caption length, lexical diversity, and text-to-audio self-retrieval accuracy.
Revisiting Deep Audio-Text Retrieval Through the Lens of Transportation
May 16, 2024



The Learning-to-match (LTM) framework proves to be an effective inverse optimal transport approach for learning the underlying ground metric between two sources of data, facilitating subsequent matching. However, the conventional LTM framework faces scalability challenges, necessitating the use of the entire dataset each time the parameters of the ground metric are updated. In adapting LTM to the deep learning context, we introduce the mini-batch Learning-to-match (m-LTM) framework for audio-text retrieval problems. This framework leverages mini-batch subsampling and Mahalanobis-enhanced family of ground metrics. Moreover, to cope with misaligned training data in practice, we propose a variant using partial optimal transport to mitigate the harm of misaligned data pairs in training data. We conduct extensive experiments on audio-text matching problems using three datasets: AudioCaps, Clotho, and ESC-50. Results demonstrate that our proposed method is capable of learning rich and expressive joint embedding space, which achieves SOTA performance. Beyond this, the proposed m-LTM framework is able to close the modality gap across audio and text embedding, which surpasses both triplet and contrastive loss in the zero-shot sound event detection task on the ESC-50 dataset. Notably, our strategy of employing partial optimal transport with m-LTM demonstrates greater noise tolerance than contrastive loss, especially under varying noise ratios in training data on the AudioCaps dataset. Our code is available at https://github.com/v-manhlt3/m-LTM-Audio-Text-Retrieval
Federated Few-shot Learning for Cough Classification with Edge Devices
Sep 03, 2023Automatically classifying cough sounds is one of the most critical tasks for the diagnosis and treatment of respiratory diseases. However, collecting a huge amount of labeled cough dataset is challenging mainly due to high laborious expenses, data scarcity, and privacy concerns. In this work, our aim is to develop a framework that can effectively perform cough classification even in situations when enormous cough data is not available, while also addressing privacy concerns. Specifically, we formulate a new problem to tackle these challenges and adopt few-shot learning and federated learning to design a novel framework, termed F2LCough, for solving the newly formulated problem. We illustrate the superiority of our method compared with other approaches on COVID-19 Thermal Face & Cough dataset, in which F2LCough achieves an average F1-Score of 86%. Our results show the feasibility of few-shot learning combined with federated learning to build a classification model of cough sounds. This new methodology is able to classify cough sounds in data-scarce situations and maintain privacy properties. The outcomes of this work can be a fundamental framework for building support systems for the detection and diagnosis of cough-related diseases.
A High-Quality and Large-Scale Dataset for English-Vietnamese Speech Translation
Aug 08, 2022


In this paper, we introduce a high-quality and large-scale benchmark dataset for English-Vietnamese speech translation with 508 audio hours, consisting of 331K triplets of (sentence-lengthed audio, English source transcript sentence, Vietnamese target subtitle sentence). We also conduct empirical experiments using strong baselines and find that the traditional "Cascaded" approach still outperforms the modern "End-to-End" approach. To the best of our knowledge, this is the first large-scale English-Vietnamese speech translation study. We hope both our publicly available dataset and study can serve as a starting point for future research and applications on English-Vietnamese speech translation. Our dataset is available at https://github.com/VinAIResearch/PhoST
FlowVocoder: A small Footprint Neural Vocoder based Normalizing flow for Speech Synthesis
Sep 27, 2021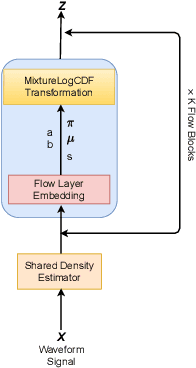

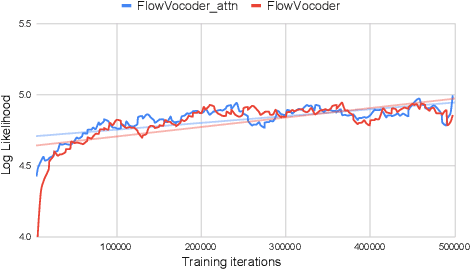
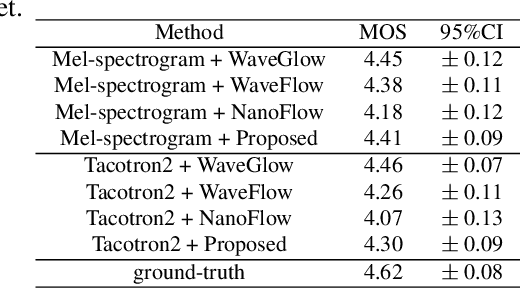
Recently, non-autoregressive neural vocoders have provided remarkable performance in generating high-fidelity speech and have been able to produce synthetic speech in real-time. However, non-autoregressive neural vocoders such as WaveGlow are far behind autoregressive neural vocoders like WaveFlow in terms of modeling audio signals due to their limitation in expressiveness. In addition, though NanoFlow is a state-of-the-art autoregressive neural vocoder that has immensely small parameters, its performance is marginally lower than WaveFlow. Therefore, in this paper, we propose a new type of autoregressive neural vocoder called FlowVocoder, which has a small memory footprint and is able to generate high-fidelity audio in real-time. Our proposed model improves the expressiveness of flow blocks by operating a mixture of Cumulative Distribution Function(CDF) for bipartite transformation. Hence, the proposed model is capable of modeling waveform signals as well as WaveFlow, while its memory footprint is much smaller thanWaveFlow. As shown in experiments, FlowVocoder achieves competitive results with baseline methods in terms of both subjective and objective evaluation, also, it is more suitable for real-time text-to-speech applications.
Many-to-Many Voice Conversion based Feature Disentanglement using Variational Autoencoder
Jul 11, 2021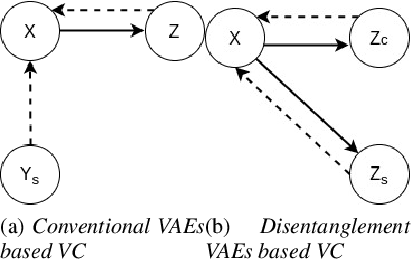
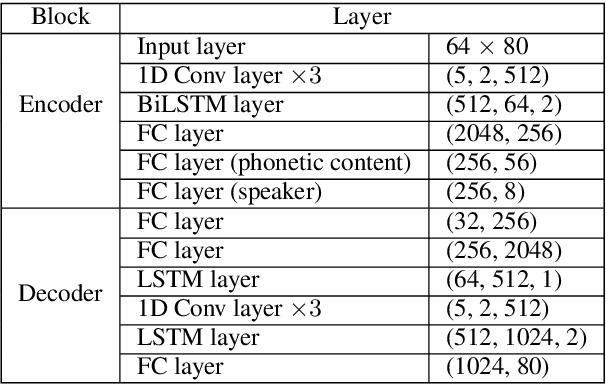
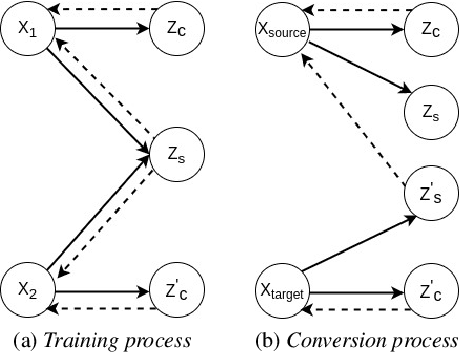
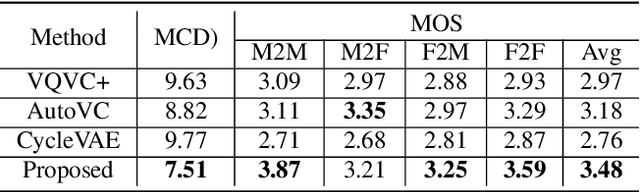
Voice conversion is a challenging task which transforms the voice characteristics of a source speaker to a target speaker without changing linguistic content. Recently, there have been many works on many-to-many Voice Conversion (VC) based on Variational Autoencoder (VAEs) achieving good results, however, these methods lack the ability to disentangle speaker identity and linguistic content to achieve good performance on unseen speaker scenarios. In this paper, we propose a new method based on feature disentanglement to tackle many to many voice conversion. The method has the capability to disentangle speaker identity and linguistic content from utterances, it can convert from many source speakers to many target speakers with a single autoencoder network. Moreover, it naturally deals with the unseen target speaker scenarios. We perform both objective and subjective evaluations to show the competitive performance of our proposed method compared with other state-of-the-art models in terms of naturalness and target speaker similarity.