 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividualised Counterfactual Examples Using Conformal Prediction Intervals
May 28, 2025



Counterfactual explanations for black-box models aim to pr ovide insight into an algorithmic decision to its recipient. For a binary classification problem an individual counterfactual details which features might be changed for the model to infer the opposite class. High-dimensional feature spaces that are typical of machine learning classification models admit many possible counterfactual examples to a decision, and so it is important to identify additional criteria to select the most useful counterfactuals. In this paper, we explore the idea that the counterfactuals should be maximally informative when considering the knowledge of a specific individual about the underlying classifier. To quantify this information gain we explicitly model the knowledge of the individual, and assess the uncertainty of predictions which the individual makes by the width of a conformal prediction interval. Regions of feature space where the prediction interval is wide correspond to areas where the confidence in decision making is low, and an additional counterfactual example might be more informative to an individual. To explore and evaluate our individualised conformal prediction interval counterfactuals (CPICFs), first we present a synthetic data set on a hypercube which allows us to fully visualise the decision boundary, conformal intervals via three different methods, and resultant CPICFs. Second, in this synthetic data set we explore the impact of a single CPICF on the knowledge of an individual locally around the original query. Finally, in both our synthetic data set and a complex real world dataset with a combination of continuous and discrete variables, we measure the utility of these counterfactuals via data augmentation, testing the performance on a held out set.
A Kernelised Stein Discrepancy for Assessing the Fit of Inhomogeneous Random Graph Models
May 27, 2025Complex data are often represented as a graph, which in turn can often be viewed as a realisation of a random graph, such as of an inhomogeneous random graph model (IRG). For general fast goodness-of-fit tests in high dimensions, kernelised Stein discrepancy (KSD) tests are a powerful tool. Here, we develop, test, and analyse a KSD-type goodness-of-fit test for IRG models that can be carried out with a single observation of the network. The test is applicable to a network of any size and does not depend on the asymptotic distribution of the test statistic. We also provide theoretical guarantees.
Private Synthetic Graph Generation and Fused Gromov-Wasserstein Distance
Feb 17, 2025



Networks are popular for representing complex data. In particular, differentially private synthetic networks are much in demand for method and algorithm development. The network generator should be easy to implement and should come with theoretical guarantees. Here we start with complex data as input and jointly provide a network representation as well as a synthetic network generator. Using a random connection model, we devise an effective algorithmic approach for generating attributed synthetic graphs which is $\epsilon$-differentially private at the vertex level, while preserving utility under an appropriate notion of distance which we develop. We provide theoretical guarantees for the accuracy of the private synthetic graphs using the fused Gromov-Wasserstein distance, which extends the Wasserstein metric to structured data. Our method draws inspiration from the PSMM method of \citet{he2023}.
Generalization Error of the Tilted Empirical Risk
Sep 28, 2024The generalization error (risk) of a supervised statistical learning algorithm quantifies its prediction ability on previously unseen data. Inspired by exponential tilting, Li et al. (2021) proposed the tilted empirical risk as a non-linear risk metric for machine learning applications such as classification and regression problems. In this work, we examine the generalization error of the tilted empirical risk. In particular, we provide uniform and information-theoretic bounds on the tilted generalization error, defined as the difference between the population risk and the tilted empirical risk, with a convergence rate of $O(1/\sqrt{n})$ where $n$ is the number of training samples. Furthermore, we study the solution to the KL-regularized expected tilted empirical risk minimization problem and derive an upper bound on the expected tilted generalization error with a convergence rate of $O(1/n)$.
Split Conformal Prediction under Data Contamination
Jul 10, 2024Conformal prediction is a non-parametric technique for constructing prediction intervals or sets from arbitrary predictive models under the assumption that the data is exchangeable. It is popular as it comes with theoretical guarantees on the marginal coverage of the prediction sets and the split conformal prediction variant has a very low computational cost compared to model training. We study the robustness of split conformal prediction in a data contamination setting, where we assume a small fraction of the calibration scores are drawn from a different distribution than the bulk. We quantify the impact of the corrupted data on the coverage and efficiency of the constructed sets when evaluated on "clean" test points, and verify our results with numerical experiments. Moreover, we propose an adjustment in the classification setting which we call Contamination Robust Conformal Prediction, and verify the efficacy of our approach using both synthetic and real datasets.
SteinGen: Generating Fidelitous and Diverse Graph Samples
Apr 04, 2024Generating graphs that preserve characteristic structures while promoting sample diversity can be challenging, especially when the number of graph observations is small. Here, we tackle the problem of graph generation from only one observed graph. The classical approach of graph generation from parametric models relies on the estimation of parameters, which can be inconsistent or expensive to compute due to intractable normalisation constants. Generative modelling based on machine learning techniques to generate high-quality graph samples avoids parameter estimation but usually requires abundant training samples. Our proposed generating procedure, SteinGen, which is phrased in the setting of graphs as realisations of exponential random graph models, combines ideas from Stein's method and MCMC by employing Markovian dynamics which are based on a Stein operator for the target model. SteinGen uses the Glauber dynamics associated with an estimated Stein operator to generate a sample, and re-estimates the Stein operator from the sample after every sampling step. We show that on a class of exponential random graph models this novel "estimation and re-estimation" generation strategy yields high distributional similarity (high fidelity) to the original data, combined with high sample diversity.
Generalization Error of Graph Neural Networks in the Mean-field Regime
Feb 10, 2024This work provides a theoretical framework for assessing the generalization error of graph classification tasks via graph neural networks in the over-parameterized regime, where the number of parameters surpasses the quantity of data points. We explore two widely utilized types of graph neural networks: graph convolutional neural networks and message passing graph neural networks. Prior to this study, existing bounds on the generalization error in the over-parametrized regime were uninformative, limiting our understanding of over-parameterized network performance. Our novel approach involves deriving upper bounds within the mean-field regime for evaluating the generalization error of these graph neural networks. We establish upper bounds with a convergence rate of $O(1/n)$, where $n$ is the number of graph samples. These upper bounds offer a theoretical assurance of the networks' performance on unseen data in the challenging over-parameterized regime and overall contribute to our understanding of their performance.
L2G2G: a Scalable Local-to-Global Network Embedding with Graph Autoencoders
Feb 02, 2024



For analysing real-world networks, graph representation learning is a popular tool. These methods, such as a graph autoencoder (GAE), typically rely on low-dimensional representations, also called embeddings, which are obtained through minimising a loss function; these embeddings are used with a decoder for downstream tasks such as node classification and edge prediction. While GAEs tend to be fairly accurate, they suffer from scalability issues. For improved speed, a Local2Global approach, which combines graph patch embeddings based on eigenvector synchronisation, was shown to be fast and achieve good accuracy. Here we propose L2G2G, a Local2Global method which improves GAE accuracy without sacrificing scalability. This improvement is achieved by dynamically synchronising the latent node representations, while training the GAEs. It also benefits from the decoder computing an only local patch loss. Hence, aligning the local embeddings in each epoch utilises more information from the graph than a single post-training alignment does, while maintaining scalability. We illustrate on synthetic benchmarks, as well as real-world examples, that L2G2G achieves higher accuracy than the standard Local2Global approach and scales efficiently on the larger data sets. We find that for large and dense networks, it even outperforms the slow, but assumed more accurate, GAEs.
Robust Angular Synchronization via Directed Graph Neural Networks
Oct 09, 2023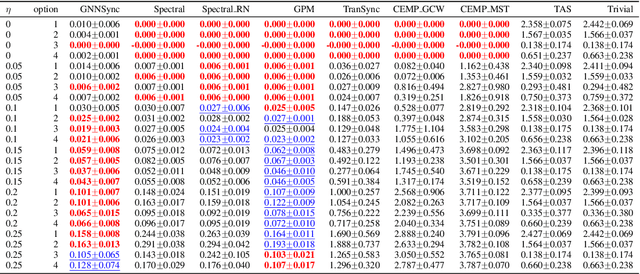

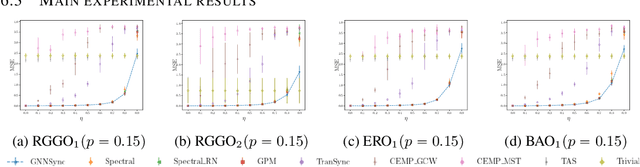
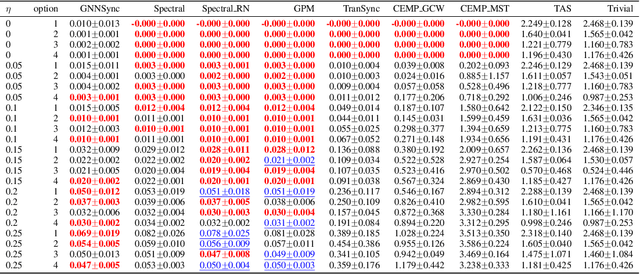
The angular synchronization problem aims to accurately estimate (up to a constant additive phase) a set of unknown angles $\theta_1, \dots, \theta_n\in[0, 2\pi)$ from $m$ noisy measurements of their offsets $\theta_i-\theta_j \;\mbox{mod} \; 2\pi.$ Applications include, for example, sensor network localization, phase retrieval, and distributed clock synchronization. An extension of the problem to the heterogeneous setting (dubbed $k$-synchronization) is to estimate $k$ groups of angles simultaneously, given noisy observations (with unknown group assignment) from each group. Existing methods for angular synchronization usually perform poorly in high-noise regimes, which are common in applications. In this paper, we leverage neural networks for the angular synchronization problem, and its heterogeneous extension, by proposing GNNSync, a theoretically-grounded end-to-end trainable framework using directed graph neural networks. In addition, new loss functions are devised to encode synchronization objectives. Experimental results on extensive data sets demonstrate that GNNSync attains competitive, and often superior, performance against a comprehensive set of baselines for the angular synchronization problem and its extension, validating the robustness of GNNSync even at high noise levels.
SaGess: Sampling Graph Denoising Diffusion Model for Scalable Graph Generation
Jun 29, 2023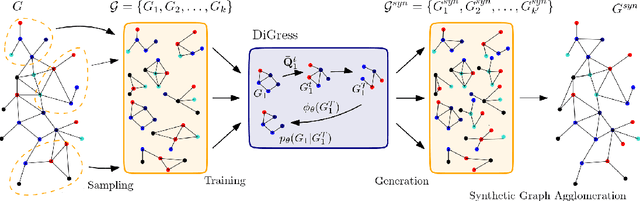
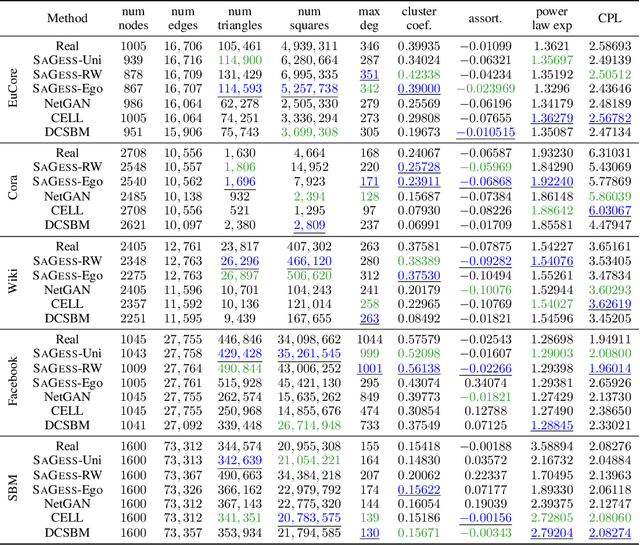
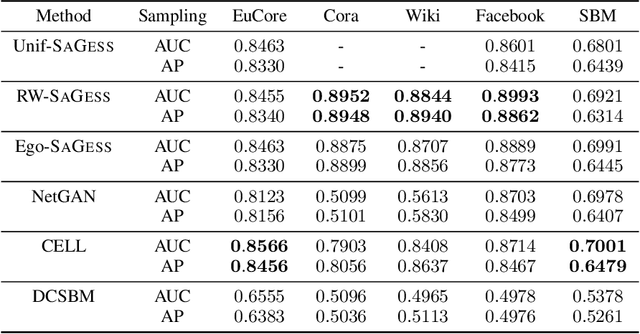
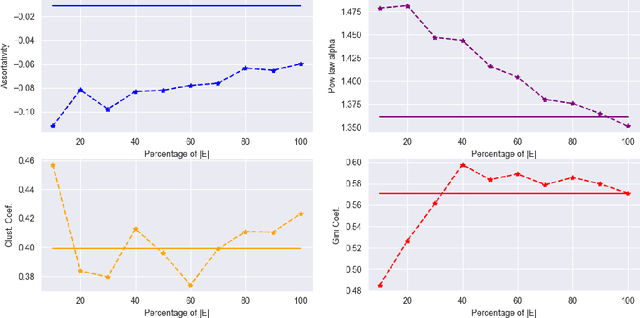
Over recent years, denoising diffusion generative models have come to be considered as state-of-the-art methods for synthetic data generation, especially in the case of generating images. These approaches have also proved successful in other applications such as tabular and graph data generation. However, due to computational complexity, to this date, the application of these techniques to graph data has been restricted to small graphs, such as those used in molecular modeling. In this paper, we propose SaGess, a discrete denoising diffusion approach, which is able to generate large real-world networks by augmenting a diffusion model (DiGress) with a generalized divide-and-conquer framework. The algorithm is capable of generating larger graphs by sampling a covering of subgraphs of the initial graph in order to train DiGress. SaGess then constructs a synthetic graph using the subgraphs that have been generated by DiGress. We evaluate the quality of the synthetic data sets against several competitor methods by comparing graph statistics between the original and synthetic samples, as well as evaluating the utility of the synthetic data set produced by using it to train a task-driven model, namely link prediction. In our experiments, SaGess, outperforms most of the one-shot state-of-the-art graph generating methods by a significant factor, both on the graph metrics and on the link prediction task.