 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models
Mar 11, 2026Late-interaction models like ColBERT offer a competitive performance across various retrieval tasks, but require storing a dense embedding for each document token, leading to a substantial index storage overhead. Past works address this by attempting to prune low-importance token embeddings based on statistical and empirical measures, but they often either lack formal grounding or are ineffective. To address these shortcomings, we introduce a framework grounded in hyperspace geometry and cast token pruning as a Voronoi cell estimation problem in the embedding space. By interpreting each token's influence as a measure of its Voronoi region, our approach enables principled pruning that retains retrieval quality while reducing index size. Through our experiments, we demonstrate that this approach serves not only as a competitive pruning strategy but also as a valuable tool for improving and interpreting token-level behavior within dense retrieval systems.
Scaling Graph-Based Dependency Parsing with Arc Vectorization and Attention-Based Refinement
Jan 16, 2025



We propose a novel architecture for graph-based dependency parsing that explicitly constructs vectors, from which both arcs and labels are scored. Our method addresses key limitations of the standard two-pipeline approach by unifying arc scoring and labeling into a single network, reducing scalability issues caused by the information bottleneck and lack of parameter sharing. Additionally, our architecture overcomes limited arc interactions with transformer layers to efficiently simulate higher-order dependencies. Experiments on PTB and UD show that our model outperforms state-of-the-art parsers in both accuracy and efficiency.
Predicting Accurate Lagrangian Multipliers for Mixed Integer Linear Programs
Oct 23, 2023



Lagrangian relaxation stands among the most efficient approaches for solving a Mixed Integer Linear Programs (MILP) with difficult constraints. Given any duals for these constraints, called Lagrangian Multipliers (LMs), it returns a bound on the optimal value of the MILP, and Lagrangian methods seek the LMs giving the best such bound. But these methods generally rely on iterative algorithms resembling gradient descent to maximize the concave piecewise linear dual function: the computational burden grows quickly with the number of relaxed constraints. We introduce a deep learning approach that bypasses the descent, effectively amortizing the local, per instance, optimization. A probabilistic encoder based on a graph convolutional network computes high-dimensional representations of relaxed constraints in MILP instances. A decoder then turns these representations into LMs. We train the encoder and decoder jointly by directly optimizing the bound obtained from the predicted multipliers. Numerical experiments show that our approach closes up to 85~\% of the gap between the continuous relaxation and the best Lagrangian bound, and provides a high quality warm-start for descent based Lagrangian methods.
Towards Unsupervised Content Disentanglement in Sentence Representations via Syntactic Roles
Jun 22, 2022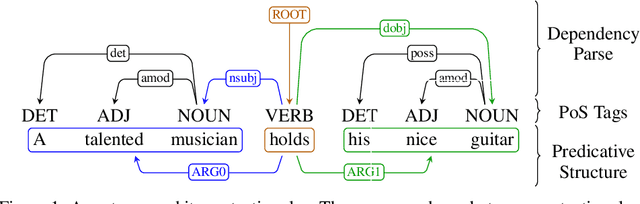
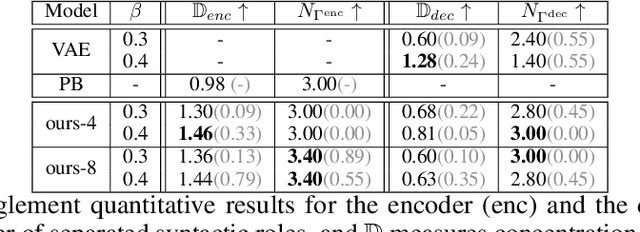
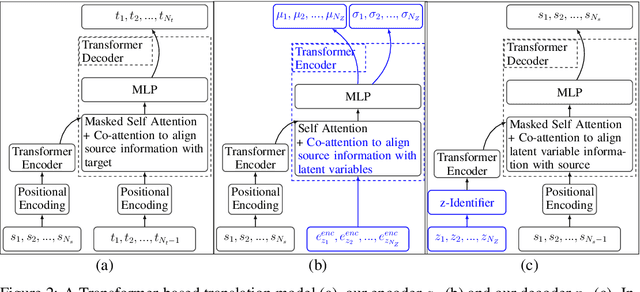
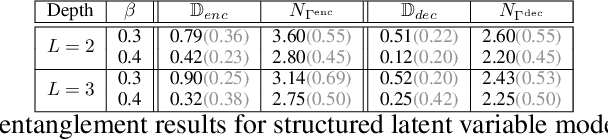
Linking neural representations to linguistic factors is crucial in order to build and analyze NLP models interpretable by humans. Among these factors, syntactic roles (e.g. subjects, direct objects,$\dots$) and their realizations are essential markers since they can be understood as a decomposition of predicative structures and thus the meaning of sentences. Starting from a deep probabilistic generative model with attention, we measure the interaction between latent variables and realizations of syntactic roles and show that it is possible to obtain, without supervision, representations of sentences where different syntactic roles correspond to clearly identified different latent variables. The probabilistic model we propose is an Attention-Driven Variational Autoencoder (ADVAE). Drawing inspiration from Transformer-based machine translation models, ADVAEs enable the analysis of the interactions between latent variables and input tokens through attention. We also develop an evaluation protocol to measure disentanglement with regard to the realizations of syntactic roles. This protocol is based on attention maxima for the encoder and on latent variable perturbations for the decoder. Our experiments on raw English text from the SNLI dataset show that $\textit{i)}$ disentanglement of syntactic roles can be induced without supervision, $\textit{ii)}$ ADVAE separates syntactic roles better than classical sequence VAEs and Transformer VAEs, $\textit{iii)}$ realizations of syntactic roles can be separately modified in sentences by mere intervention on the associated latent variables. Our work constitutes a first step towards unsupervised controllable content generation. The code for our work is publicly available.
Exploiting Inductive Bias in Transformers for Unsupervised Disentanglement of Syntax and Semantics with VAEs
May 19, 2022
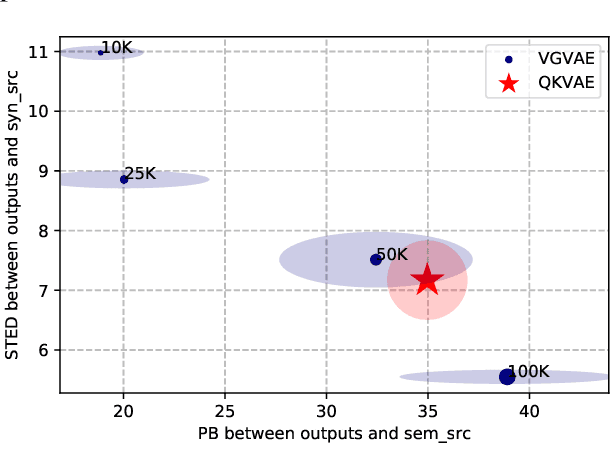
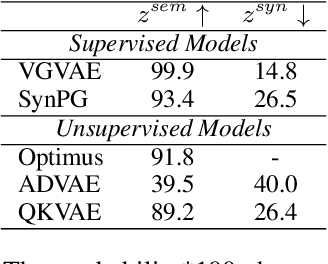
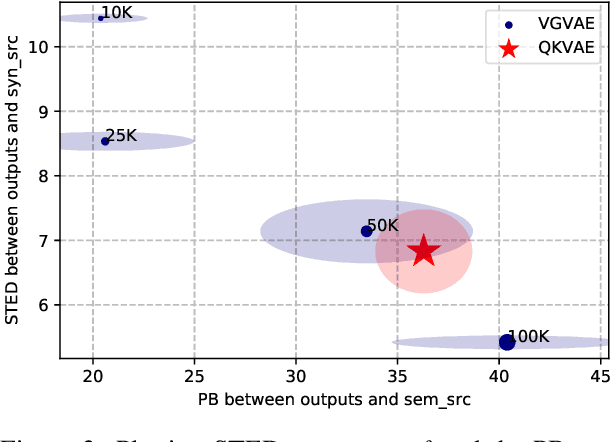
We propose a generative model for text generation, which exhibits disentangled latent representations of syntax and semantics. Contrary to previous work, this model does not need syntactic information such as constituency parses, or semantic information such as paraphrase pairs. Our model relies solely on the inductive bias found in attention-based architectures such as Transformers. In the attention of Transformers, keys handle information selection while values specify what information is conveyed. Our model, dubbed QKVAE, uses Attention in its decoder to read latent variables where one latent variable infers keys while another infers values. We run experiments on latent representations and experiments on syntax/semantics transfer which show that QKVAE displays clear signs of disentangled syntax and semantics. We also show that our model displays competitive syntax transfer capabilities when compared to supervised models and that comparable supervised models need a fairly large amount of data (more than 50K samples) to outperform it on both syntactic and semantic transfer. The code for our experiments is publicly available.
AraBART: a Pretrained Arabic Sequence-to-Sequence Model for Abstractive Summarization
Mar 21, 2022
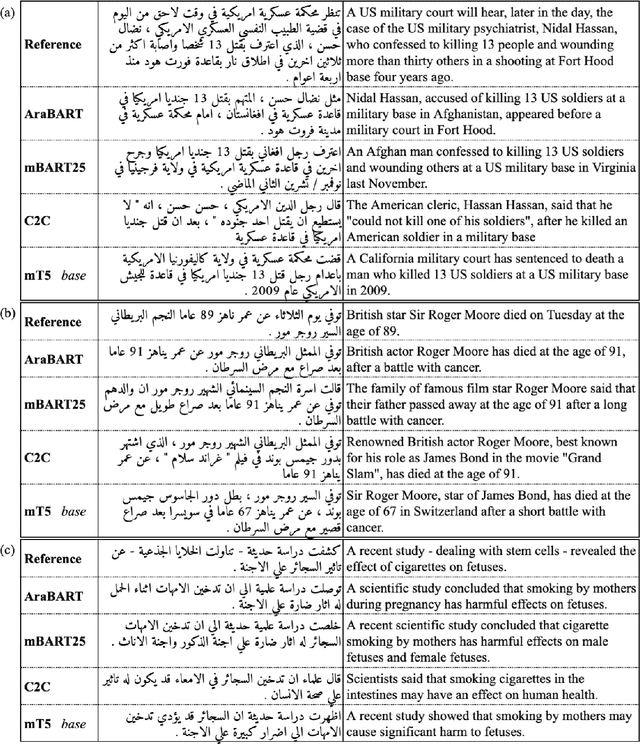
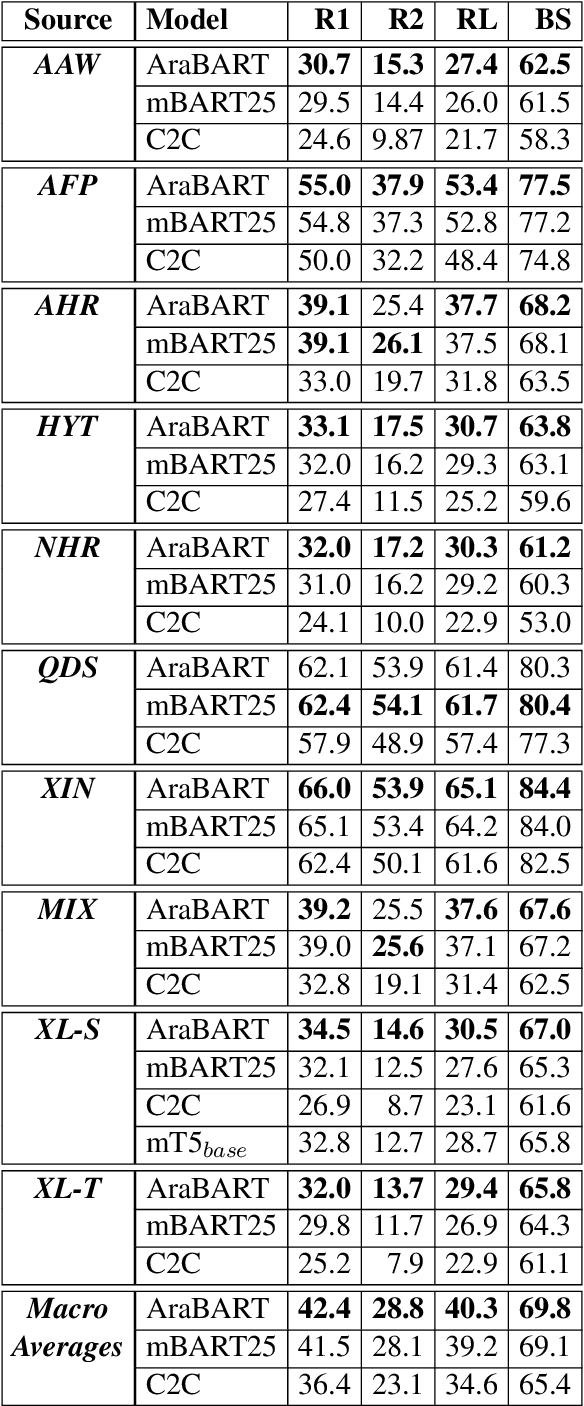
Like most natural language understanding and generation tasks, state-of-the-art models for summarization are transformer-based sequence-to-sequence architectures that are pretrained on large corpora. While most existing models focused on English, Arabic remained understudied. In this paper we propose AraBART, the first Arabic model in which the encoder and the decoder are pretrained end-to-end, based on BART. We show that AraBART achieves the best performance on multiple abstractive summarization datasets, outperforming strong baselines including a pretrained Arabic BERT-based model and multilingual mBART and mT5 models.
Challenging the Semi-Supervised VAE Framework for Text Classification
Sep 27, 2021
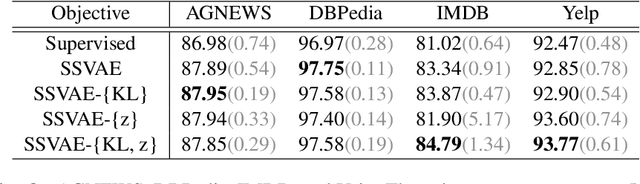


Semi-Supervised Variational Autoencoders (SSVAEs) are widely used models for data efficient learning. In this paper, we question the adequacy of the standard design of sequence SSVAEs for the task of text classification as we exhibit two sources of overcomplexity for which we provide simplifications. These simplifications to SSVAEs preserve their theoretical soundness while providing a number of practical advantages in the semi-supervised setup where the result of training is a text classifier. These simplifications are the removal of (i) the Kullback-Liebler divergence from its objective and (ii) the fully unobserved latent variable from its probabilistic model. These changes relieve users from choosing a prior for their latent variables, make the model smaller and faster, and allow for a better flow of information into the latent variables. We compare the simplified versions to standard SSVAEs on 4 text classification tasks. On top of the above-mentioned simplification, experiments show a speed-up of 26%, while keeping equivalent classification scores. The code to reproduce our experiments is public.
Disentangling semantics in language through VAEs and a certain architectural choice
Dec 28, 2020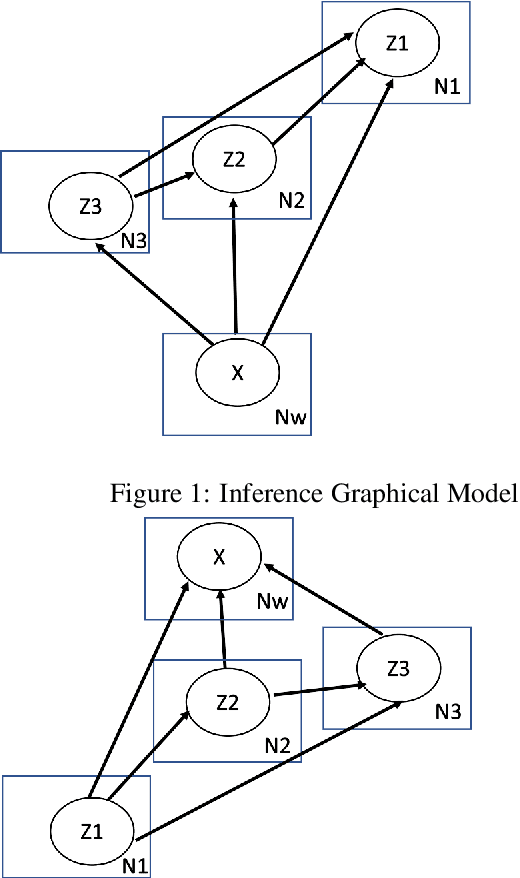
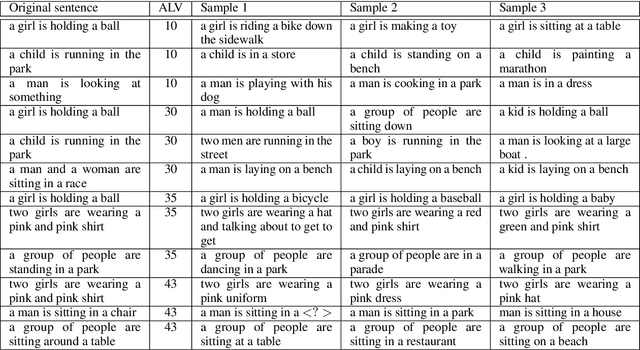
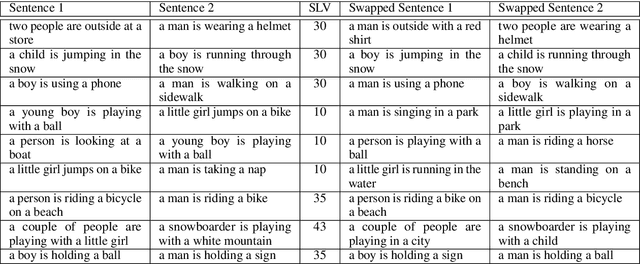
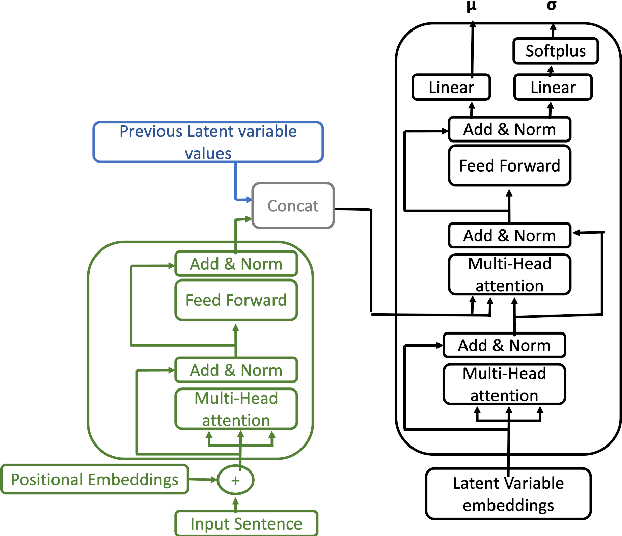
We present an unsupervised method to obtain disentangled representations of sentences that single out semantic content. Using modified Transformers as building blocks, we train a Variational Autoencoder to translate the sentence to a fixed number of hierarchically structured latent variables. We study the influence of each latent variable in generation on the dependency structure of sentences, and on the predicate structure it yields when passed through an Open Information Extraction model. Our model could separate verbs, subjects, direct objects, and prepositional objects into latent variables we identified. We show that varying the corresponding latent variables results in varying these elements in sentences, and that swapping them between couples of sentences leads to the expected partial semantic swap.
Feature Unification in TAG Derivation Trees
Apr 29, 2008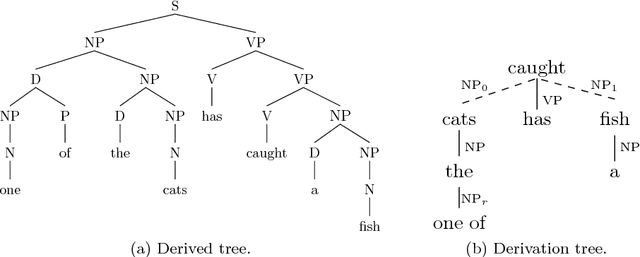
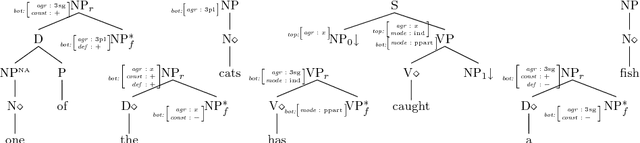
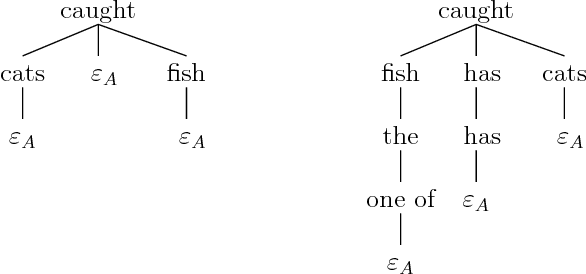
The derivation trees of a tree adjoining grammar provide a first insight into the sentence semantics, and are thus prime targets for generation systems. We define a formalism, feature-based regular tree grammars, and a translation from feature based tree adjoining grammars into this new formalism. The translation preserves the derivation structures of the original grammar, and accounts for feature unification.
* 12 pages, 4 figures In TAG+9, Ninth International Workshop on Tree Adjoining Grammars and Related Formalisms, 2008