 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Strategies in Large Language Models: Can They Follow, Prefer, and Optimize?
Jul 16, 2025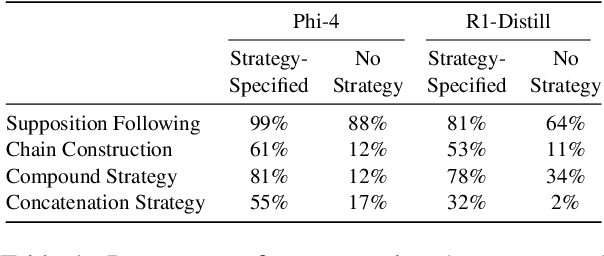

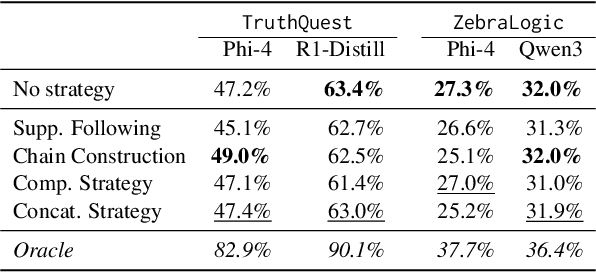
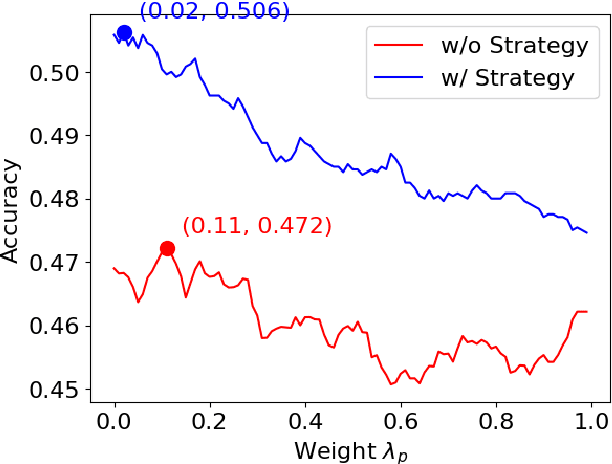
Human reasoning involves different strategies, each suited to specific problems. Prior work shows that large language model (LLMs) tend to favor a single reasoning strategy, potentially limiting their effectiveness in diverse reasoning challenges. In this work, we investigate whether prompting can control LLMs reasoning strategies and assess its impact on logical problem-solving. While our experiments show that no single strategy consistently improves accuracy, performance could be enhanced if models could adaptively choose the optimal strategy. We propose methods to guide LLMs in strategy selection, highlighting new ways to refine their reasoning abilities.
Scaling Graph-Based Dependency Parsing with Arc Vectorization and Attention-Based Refinement
Jan 16, 2025



We propose a novel architecture for graph-based dependency parsing that explicitly constructs vectors, from which both arcs and labels are scored. Our method addresses key limitations of the standard two-pipeline approach by unifying arc scoring and labeling into a single network, reducing scalability issues caused by the information bottleneck and lack of parameter sharing. Additionally, our architecture overcomes limited arc interactions with transformer layers to efficiently simulate higher-order dependencies. Experiments on PTB and UD show that our model outperforms state-of-the-art parsers in both accuracy and efficiency.
Manual Verbalizer Enrichment for Few-Shot Text Classification
Oct 08, 2024


With the continuous development of pre-trained language models, prompt-based training becomes a well-adopted paradigm that drastically improves the exploitation of models for many natural language processing tasks. Prompting also shows great performance compared to traditional fine-tuning when adapted to zero-shot or few-shot scenarios where the number of annotated data is limited. In this framework, the role of verbalizers is essential, as an interpretation from masked word distributions into output predictions. In this work, we propose \acrshort{mave}, an approach for verbalizer construction by enrichment of class labels using neighborhood relation in the embedding space of words for the text classification task. In addition, we elaborate a benchmarking procedure to evaluate typical baselines of verbalizers for document classification in few-shot learning contexts. Our model achieves state-of-the-art results while using significantly fewer resources. We show that our approach is particularly effective in cases with extremely limited supervision data.
GraphER: A Structure-aware Text-to-Graph Model for Entity and Relation Extraction
Apr 18, 2024Information extraction (IE) is an important task in Natural Language Processing (NLP), involving the extraction of named entities and their relationships from unstructured text. In this paper, we propose a novel approach to this task by formulating it as graph structure learning (GSL). By formulating IE as GSL, we enhance the model's ability to dynamically refine and optimize the graph structure during the extraction process. This formulation allows for better interaction and structure-informed decisions for entity and relation prediction, in contrast to previous models that have separate or untied predictions for these tasks. When compared against state-of-the-art baselines on joint entity and relation extraction benchmarks, our model, GraphER, achieves competitive results.
EnriCo: Enriched Representation and Globally Constrained Inference for Entity and Relation Extraction
Apr 18, 2024Joint entity and relation extraction plays a pivotal role in various applications, notably in the construction of knowledge graphs. Despite recent progress, existing approaches often fall short in two key aspects: richness of representation and coherence in output structure. These models often rely on handcrafted heuristics for computing entity and relation representations, potentially leading to loss of crucial information. Furthermore, they disregard task and/or dataset-specific constraints, resulting in output structures that lack coherence. In our work, we introduce EnriCo, which mitigates these shortcomings. Firstly, to foster rich and expressive representation, our model leverage attention mechanisms that allow both entities and relations to dynamically determine the pertinent information required for accurate extraction. Secondly, we introduce a series of decoding algorithms designed to infer the highest scoring solutions while adhering to task and dataset-specific constraints, thus promoting structured and coherent outputs. Our model demonstrates competitive performance compared to baselines when evaluated on Joint IE datasets.
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction
Jan 15, 2024In this paper, we propose a novel method for joint entity and relation extraction from unstructured text by framing it as a conditional sequence generation problem. In contrast to conventional generative information extraction models that are left-to-right token-level generators, our approach is \textit{span-based}. It generates a linearized graph where nodes represent text spans and edges represent relation triplets. Our method employs a transformer encoder-decoder architecture with pointing mechanism on a dynamic vocabulary of spans and relation types. Our model can capture the structural characteristics and boundaries of entities and relations through span representations while simultaneously grounding the generated output in the original text thanks to the pointing mechanism. Evaluation on benchmark datasets validates the effectiveness of our approach, demonstrating competitive results. Code is available at https://github.com/urchade/ATG.
Filtered Semi-Markov CRF
Nov 29, 2023



Semi-Markov CRF has been proposed as an alternative to the traditional Linear Chain CRF for text segmentation tasks such as Named Entity Recognition (NER). Unlike CRF, which treats text segmentation as token-level prediction, Semi-CRF considers segments as the basic unit, making it more expressive. However, Semi-CRF suffers from two major drawbacks: (1) quadratic complexity over sequence length, as it operates on every span of the input sequence, and (2) inferior performance compared to CRF for sequence labeling tasks like NER. In this paper, we introduce Filtered Semi-Markov CRF, a variant of Semi-CRF that addresses these issues by incorporating a filtering step to eliminate irrelevant segments, reducing complexity and search space. Our approach is evaluated on several NER benchmarks, where it outperforms both CRF and Semi-CRF while being significantly faster. The implementation of our method is available on \href{https://github.com/urchade/Filtered-Semi-Markov-CRF}{Github}.
GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer
Nov 14, 2023



Named Entity Recognition (NER) is essential in various Natural Language Processing (NLP) applications. Traditional NER models are effective but limited to a set of predefined entity types. In contrast, Large Language Models (LLMs) can extract arbitrary entities through natural language instructions, offering greater flexibility. However, their size and cost, particularly for those accessed via APIs like ChatGPT, make them impractical in resource-limited scenarios. In this paper, we introduce a compact NER model trained to identify any type of entity. Leveraging a bidirectional transformer encoder, our model, GLiNER, facilitates parallel entity extraction, an advantage over the slow sequential token generation of LLMs. Through comprehensive testing, GLiNER demonstrate strong performance, outperforming both ChatGPT and fine-tuned LLMs in zero-shot evaluations on various NER benchmarks.
DyREx: Dynamic Query Representation for Extractive Question Answering
Oct 26, 2022Extractive question answering (ExQA) is an essential task for Natural Language Processing. The dominant approach to ExQA is one that represents the input sequence tokens (question and passage) with a pre-trained transformer, then uses two learned query vectors to compute distributions over the start and end answer span positions. These query vectors lack the context of the inputs, which can be a bottleneck for the model performance. To address this problem, we propose \textit{DyREx}, a generalization of the \textit{vanilla} approach where we dynamically compute query vectors given the input, using an attention mechanism through transformer layers. Empirical observations demonstrate that our approach consistently improves the performance over the standard one. The code and accompanying files for running the experiments are available at \url{https://github.com/urchade/DyReX}.
Hierarchical Transformer Model for Scientific Named Entity Recognition
Mar 28, 2022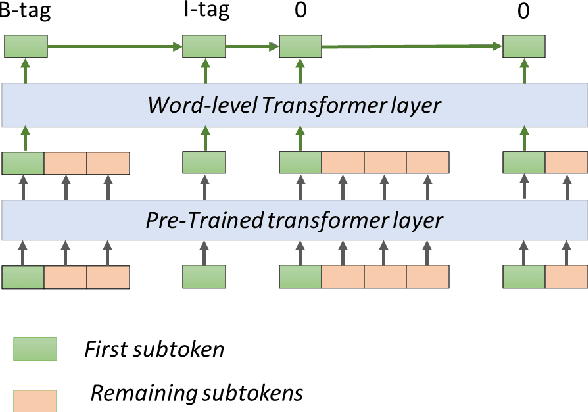
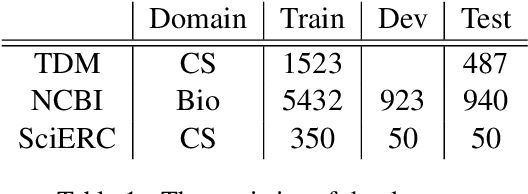
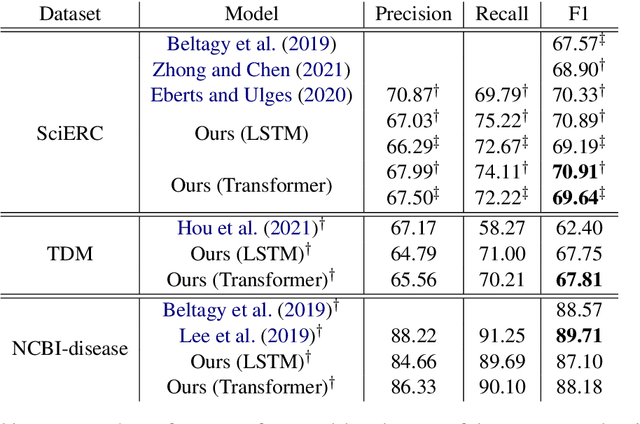

The task of Named Entity Recognition (NER) is an important component of many natural language processing systems, such as relation extraction and knowledge graph construction. In this work, we present a simple and effective approach for Named Entity Recognition. The main idea of our approach is to encode the input subword sequence with a pre-trained transformer such as BERT, and then, instead of directly classifying the word labels, another layer of transformer is added to the subword representation to better encode the word-level interaction. We evaluate our approach on three benchmark datasets for scientific NER, particularly in the computer science and biomedical domains. Experimental results show that our model outperforms the current state-of-the-art on SciERC and TDM datasets without requiring external resources or specific data augmentation. Code is available at \url{https://github.com/urchade/HNER}.