 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroGame Transformer: Gibbs-Inspired Attention Driven by Game Theory and Statistical Physics
Mar 19, 2026Standard attention mechanisms in transformers are limited by their pairwise formulation, which hinders the modeling of higher-order dependencies among tokens. We introduce the NeuroGame Transformer (NGT) to overcome this by reconceptualizing attention through a dual perspective: tokens are treated simultaneously as players in a cooperative game and as interacting spins in a statistical physics system. Token importance is quantified using two complementary game-theoretic concepts -- Shapley values for global, permutation-based attribution and Banzhaf indices for local, coalition-level influence. These are combined via a learnable gating parameter to form an external magnetic field, while pairwise interaction potentials capture synergistic relationships. The system's energy follows an Ising Hamiltonian, with attention weights emerging as marginal probabilities under the Gibbs distribution, efficiently computed via mean-field equations. To ensure scalability despite the exponential coalition space, we develop importance-weighted Monte Carlo estimators with Gibbs-distributed weights. This approach avoids explicit exponential factors, ensuring numerical stability for long sequences. We provide theoretical convergence guarantees and characterize the fairness-sensitivity trade-off governed by the interpolation parameter. Experimental results demonstrate that the NeuroGame Transformer achieves strong performance across SNLI, and MNLI-matched, outperforming some major efficient transformer baselines. On SNLI, it attains a test accuracy of 86.4\% (with a peak validation accuracy of 86.6\%), surpassing ALBERT-Base and remaining highly competitive with RoBERTa-Base. Code is available at https://github.com/dbouchaffra/NeuroGame-Transformer.
Manual Verbalizer Enrichment for Few-Shot Text Classification
Oct 08, 2024
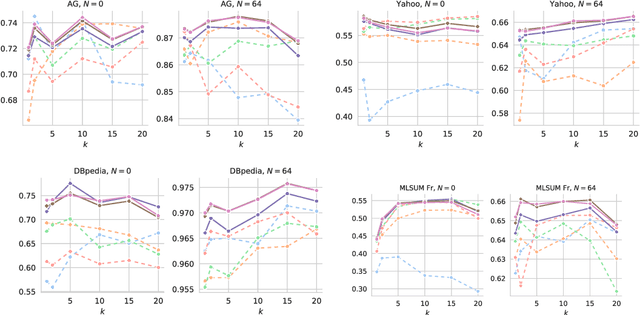


With the continuous development of pre-trained language models, prompt-based training becomes a well-adopted paradigm that drastically improves the exploitation of models for many natural language processing tasks. Prompting also shows great performance compared to traditional fine-tuning when adapted to zero-shot or few-shot scenarios where the number of annotated data is limited. In this framework, the role of verbalizers is essential, as an interpretation from masked word distributions into output predictions. In this work, we propose \acrshort{mave}, an approach for verbalizer construction by enrichment of class labels using neighborhood relation in the embedding space of words for the text classification task. In addition, we elaborate a benchmarking procedure to evaluate typical baselines of verbalizers for document classification in few-shot learning contexts. Our model achieves state-of-the-art results while using significantly fewer resources. We show that our approach is particularly effective in cases with extremely limited supervision data.
Evaluating the Efficacy of Instance Incremental vs. Batch Learning in Delayed Label Environments: An Empirical Study on Tabular Data Streaming for Fraud Detection
Sep 16, 2024



Real-world tabular learning production scenarios typically involve evolving data streams, where data arrives continuously and its distribution may change over time. In such a setting, most studies in the literature regarding supervised learning favor the use of instance incremental algorithms due to their ability to adapt to changes in the data distribution. Another significant reason for choosing these algorithms is \textit{avoid storing observations in memory} as commonly done in batch incremental settings. However, the design of instance incremental algorithms often assumes immediate availability of labels, which is an optimistic assumption. In many real-world scenarios, such as fraud detection or credit scoring, labels may be delayed. Consequently, batch incremental algorithms are widely used in many real-world tasks. This raises an important question: "In delayed settings, is instance incremental learning the best option regarding predictive performance and computational efficiency?" Unfortunately, this question has not been studied in depth, probably due to the scarcity of real datasets containing delayed information. In this study, we conduct a comprehensive empirical evaluation and analysis of this question using a real-world fraud detection problem and commonly used generated datasets. Our findings indicate that instance incremental learning is not the superior option, considering on one side state-of-the-art models such as Adaptive Random Forest (ARF) and other side batch learning models such as XGBoost. Additionally, when considering the interpretability of the learning systems, batch incremental solutions tend to be favored. Code: \url{https://github.com/anselmeamekoe/DelayedLabelStream}
Distributed MCMC inference for Bayesian Non-Parametric Latent Block Model
Feb 01, 2024



In this paper, we introduce a novel Distributed Markov Chain Monte Carlo (MCMC) inference method for the Bayesian Non-Parametric Latent Block Model (DisNPLBM), employing the Master/Worker architecture. Our non-parametric co-clustering algorithm divides observations and features into partitions using latent multivariate Gaussian block distributions. The workload on rows is evenly distributed among workers, who exclusively communicate with the master and not among themselves. DisNPLBM demonstrates its impact on cluster labeling accuracy and execution times through experimental results. Moreover, we present a real-use case applying our approach to co-cluster gene expression data. The code source is publicly available at https://github.com/redakhoufache/Distributed-NPLBM.
Distributed Collapsed Gibbs Sampler for Dirichlet Process Mixture Models in Federated Learning
Dec 18, 2023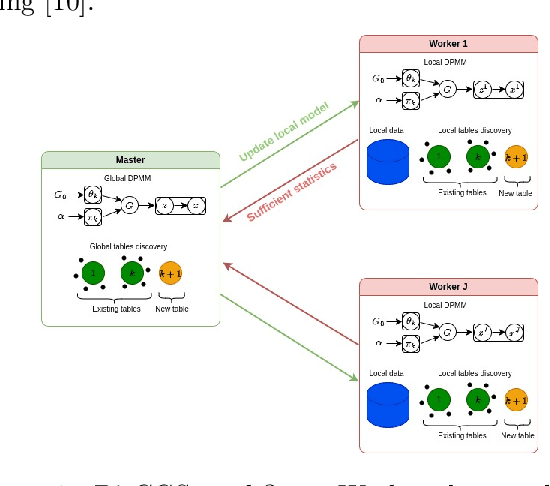

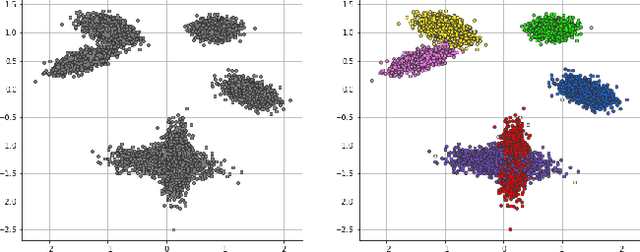
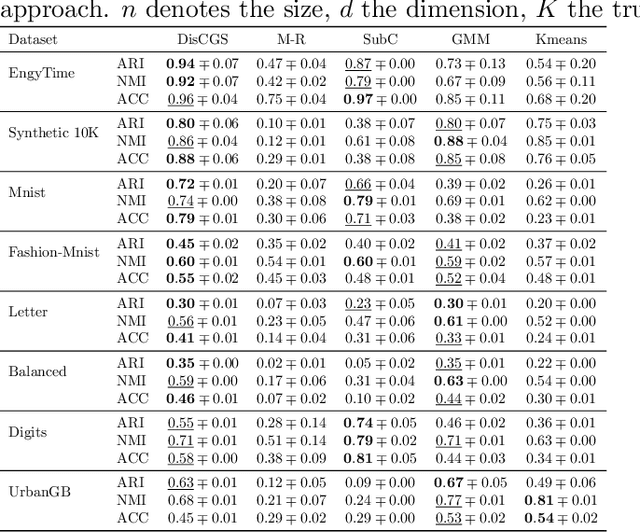
Dirichlet Process Mixture Models (DPMMs) are widely used to address clustering problems. Their main advantage lies in their ability to automatically estimate the number of clusters during the inference process through the Bayesian non-parametric framework. However, the inference becomes considerably slow as the dataset size increases. This paper proposes a new distributed Markov Chain Monte Carlo (MCMC) inference method for DPMMs (DisCGS) using sufficient statistics. Our approach uses the collapsed Gibbs sampler and is specifically designed to work on distributed data across independent and heterogeneous machines, which habilitates its use in horizontal federated learning. Our method achieves highly promising results and notable scalability. For instance, with a dataset of 100K data points, the centralized algorithm requires approximately 12 hours to complete 100 iterations while our approach achieves the same number of iterations in just 3 minutes, reducing the execution time by a factor of 200 without compromising clustering performance. The code source is publicly available at https://github.com/redakhoufache/DisCGS.
Self-Reinforcement Attention Mechanism For Tabular Learning
May 19, 2023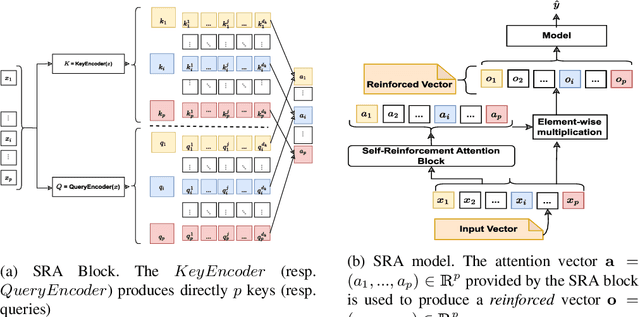
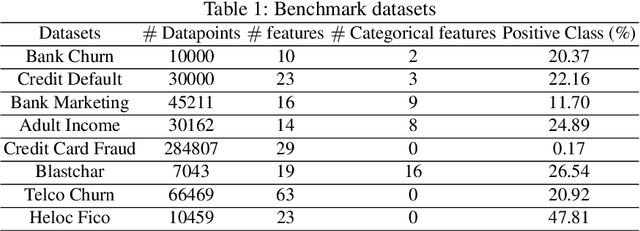
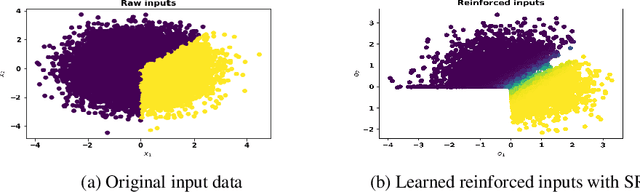
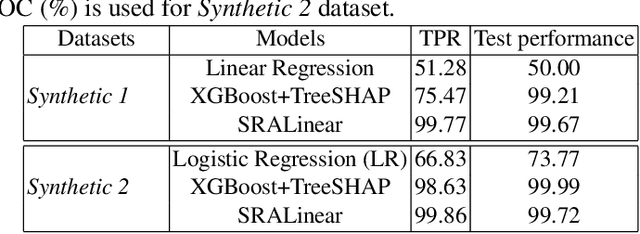
Apart from the high accuracy of machine learning models, what interests many researchers in real-life problems (e.g., fraud detection, credit scoring) is to find hidden patterns in data; particularly when dealing with their challenging imbalanced characteristics. Interpretability is also a key requirement that needs to accompany the used machine learning model. In this concern, often, intrinsically interpretable models are preferred to complex ones, which are in most cases black-box models. Also, linear models are used in some high-risk fields to handle tabular data, even if performance must be sacrificed. In this paper, we introduce Self-Reinforcement Attention (SRA), a novel attention mechanism that provides a relevance of features as a weight vector which is used to learn an intelligible representation. This weight is then used to reinforce or reduce some components of the raw input through element-wise vector multiplication. Our results on synthetic and real-world imbalanced data show that our proposed SRA block is effective in end-to-end combination with baseline models.
Epigenetics Algorithms: Self-Reinforcement-Attention mechanism to regulate chromosomes expression
Mar 15, 2023Genetic algorithms are a well-known example of bio-inspired heuristic methods. They mimic natural selection by modeling several operators such as mutation, crossover, and selection. Recent discoveries about Epigenetics regulation processes that occur "on top of" or "in addition to" the genetic basis for inheritance involve changes that affect and improve gene expression. They raise the question of improving genetic algorithms (GAs) by modeling epigenetics operators. This paper proposes a new epigenetics algorithm that mimics the epigenetics phenomenon known as DNA methylation. The novelty of our epigenetics algorithms lies primarily in taking advantage of attention mechanisms and deep learning, which fits well with the genes enhancing/silencing concept. The paper develops theoretical arguments and presents empirical studies to exhibit the capability of the proposed epigenetics algorithms to solve more complex problems efficiently than has been possible with simple GAs; for example, facing two Non-convex (multi-peaks) optimization problems as presented in this paper, the proposed epigenetics algorithm provides good performances and shows an excellent ability to overcome the lack of local optimum and thus find the global optimum.
Improved Multi-objective Data Stream Clustering with Time and Memory Optimization
Jan 13, 2022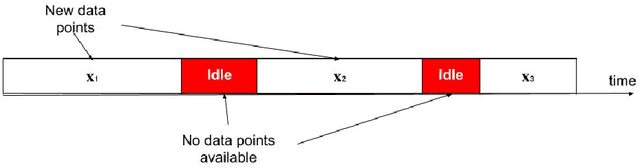



The analysis of data streams has received considerable attention over the past few decades due to sensors, social media, etc. It aims to recognize patterns in an unordered, infinite, and evolving stream of observations. Clustering this type of data requires some restrictions in time and memory. This paper introduces a new data stream clustering method (IMOC-Stream). This method, unlike the other clustering algorithms, uses two different objective functions to capture different aspects of the data. The goal of IMOC-Stream is to: 1) reduce computation time by using idle times to apply genetic operations and enhance the solution. 2) reduce memory allocation by introducing a new tree synopsis. 3) find arbitrarily shaped clusters by using a multi-objective framework. We conducted an experimental study with high dimensional stream datasets and compared them to well-known stream clustering techniques. The experiments show the ability of our method to partition the data stream in arbitrarily shaped, compact, and well-separated clusters while optimizing the time and memory. Our method also outperformed most of the stream algorithms in terms of NMI and ARAND measures.
Experience feedback using Representation Learning for Few-Shot Object Detection on Aerial Images
Sep 27, 2021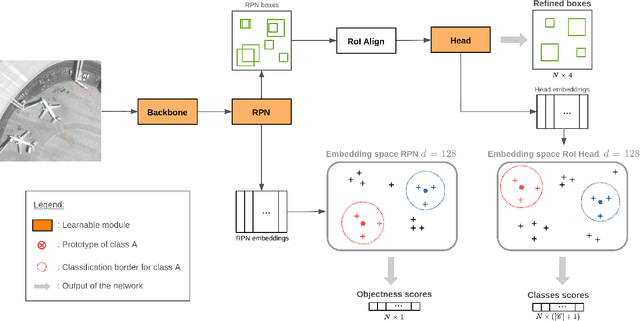
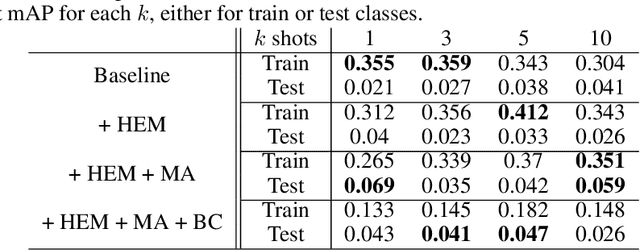
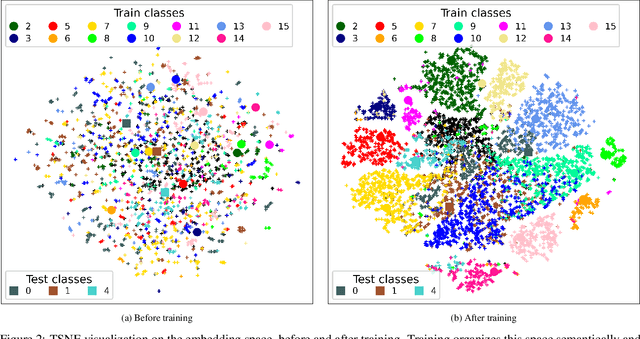
This paper proposes a few-shot method based on Faster R-CNN and representation learning for object detection in aerial images. The two classification branches of Faster R-CNN are replaced by prototypical networks for online adaptation to new classes. These networks produce embeddings vectors for each generated box, which are then compared with class prototypes. The distance between an embedding and a prototype determines the corresponding classification score. The resulting networks are trained in an episodic manner. A new detection task is randomly sampled at each epoch, consisting in detecting only a subset of the classes annotated in the dataset. This training strategy encourages the network to adapt to new classes as it would at test time. In addition, several ideas are explored to improve the proposed method such as a hard negative examples mining strategy and self-supervised clustering for background objects. The performance of our method is assessed on DOTA, a large-scale remote sensing images dataset. The experiments conducted provide a broader understanding of the capabilities of representation learning. It highlights in particular some intrinsic weaknesses for the few-shot object detection task. Finally, some suggestions and perspectives are formulated according to these insights.