 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Efficacy of Instance Incremental vs. Batch Learning in Delayed Label Environments: An Empirical Study on Tabular Data Streaming for Fraud Detection
Sep 16, 2024



Real-world tabular learning production scenarios typically involve evolving data streams, where data arrives continuously and its distribution may change over time. In such a setting, most studies in the literature regarding supervised learning favor the use of instance incremental algorithms due to their ability to adapt to changes in the data distribution. Another significant reason for choosing these algorithms is \textit{avoid storing observations in memory} as commonly done in batch incremental settings. However, the design of instance incremental algorithms often assumes immediate availability of labels, which is an optimistic assumption. In many real-world scenarios, such as fraud detection or credit scoring, labels may be delayed. Consequently, batch incremental algorithms are widely used in many real-world tasks. This raises an important question: "In delayed settings, is instance incremental learning the best option regarding predictive performance and computational efficiency?" Unfortunately, this question has not been studied in depth, probably due to the scarcity of real datasets containing delayed information. In this study, we conduct a comprehensive empirical evaluation and analysis of this question using a real-world fraud detection problem and commonly used generated datasets. Our findings indicate that instance incremental learning is not the superior option, considering on one side state-of-the-art models such as Adaptive Random Forest (ARF) and other side batch learning models such as XGBoost. Additionally, when considering the interpretability of the learning systems, batch incremental solutions tend to be favored. Code: \url{https://github.com/anselmeamekoe/DelayedLabelStream}
Self-Reinforcement Attention Mechanism For Tabular Learning
May 19, 2023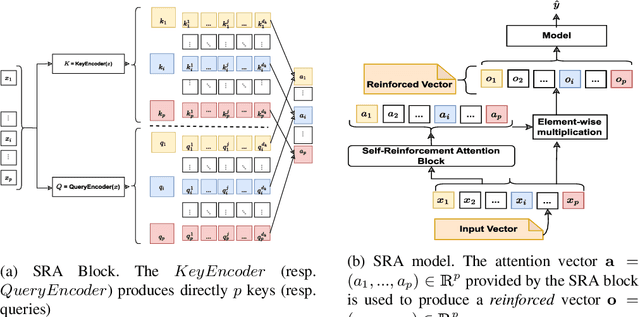
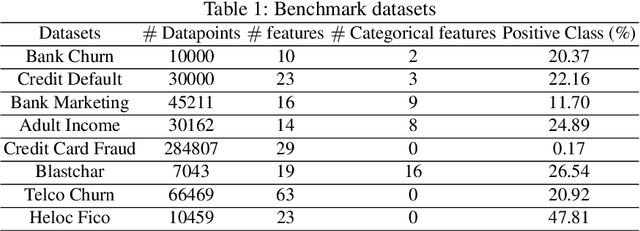
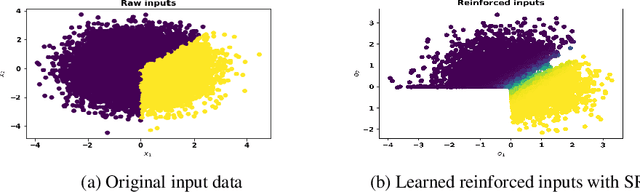
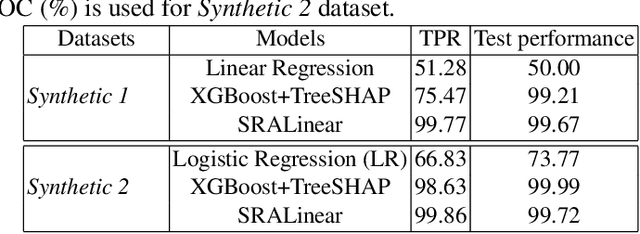
Apart from the high accuracy of machine learning models, what interests many researchers in real-life problems (e.g., fraud detection, credit scoring) is to find hidden patterns in data; particularly when dealing with their challenging imbalanced characteristics. Interpretability is also a key requirement that needs to accompany the used machine learning model. In this concern, often, intrinsically interpretable models are preferred to complex ones, which are in most cases black-box models. Also, linear models are used in some high-risk fields to handle tabular data, even if performance must be sacrificed. In this paper, we introduce Self-Reinforcement Attention (SRA), a novel attention mechanism that provides a relevance of features as a weight vector which is used to learn an intelligible representation. This weight is then used to reinforce or reduce some components of the raw input through element-wise vector multiplication. Our results on synthetic and real-world imbalanced data show that our proposed SRA block is effective in end-to-end combination with baseline models.